22-Network(34)
1. HTTP2.0、3.0区别
- Google 它自己突破自己,主要也是源自于痛点,这次的痛点来自于 HTTP 依赖的 TCP
- TCP 是面向可靠的、有序的传输协议,会有失败重传和按序机制,而 HTTP/2 是所有流共享一个 TCP 连接,所以会有 TCP 层面的队头阻塞,当发生重传时会影响多个请求响应
- 并且 TCP 是基于四元组(源IP、源端口、目标IP、目标端口)来确定连接的,而在移动网络的情况下 IP 地址会频繁的换,这会导致反复的建连
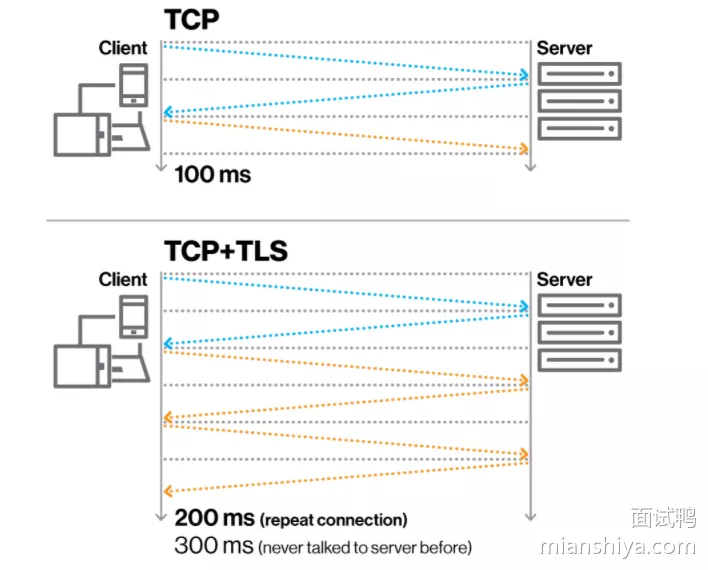
- 还有 TCP 与 TLS 的叠加握手,增加了延时
问题就出在 TCP 身上,所以 Google 就把目光瞄向了 UDP
- UDP 是无连接的,不管什么顺序,也不管你什么丢包
- 把 TCP 可靠、有序的功能提到应用层来实现,因此 Google 就研究出了 QUIC 协议
- QUIC 层来实现自己的丢包重传和拥塞控制

- 出于安全的考虑我们都会用 HTTPS ,所以需要多次握手
- 关于四元组的情况,所以在移动互联网时代这握手的消耗就更加放大了
- QUIC 引入了个叫 Connection ID 来标识一个链接,所以切换网络之后可以复用这个连接,达到 0 RTT 就能开始传输
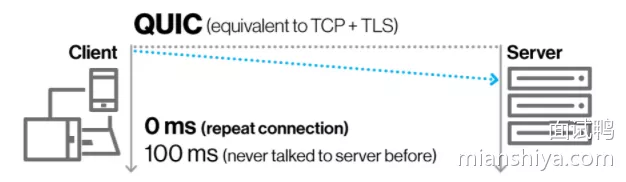
- 已经和服务端握过手之后的,由于网络切换等原因才有 0 RTT ,也就是 Connection ID 在之前生成过了
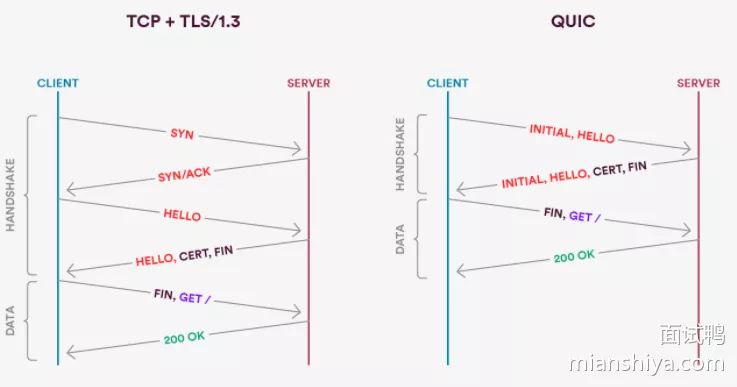
- 如果是第一次建连还是需要多次握手的,简化的握手对比图
HTTP/2 提到的 HPACK,这个是依赖 TCP 的可靠、有序传输的,于是 QUIC 得搞了个 QPACK,也采用了静态表、动态表和哈夫曼编码
- 它丰富了 HTTP/2 的静态表,从 61 项加到了 98 项
- 动态表,是用来存储未包含在静态表中的头部项,假设动态表还未收到,后面来解头部的时候肯定要被阻塞的
- QPACK 就另开一条路,在单向的 Stream 里传输动态表的编解码,单向传输好了,接受端到才能开始解码,也就是说还没好你就先别管,防止做一半卡住了
TCP 队头阻塞, QUIC 怎么解决?毕竟它要保证有序和可靠
- 因为 TCP 不认识每个流分别是哪个请求的,所以它只能全部阻塞住
- 而 QUIC 知道,因此请求 A 丢包了,就把 A 卡住了就行,请求 B 完全可以全部放行,丝毫不受影响
可以看到基于 UDP 的 QUIC 还是很强大的,而且google用户多,在 2018 年,互联网标准化组织 IETF 提议将 HTTP over QUIC 更名为 HTTP/3 并获得批准
2. 到底是什么连接
- TCP 是面向连接的
- 所谓的连接其实只是双方都维护了一个状态,通过每一次通信来维护状态的变更,使得看起来好像有一条线关联了对方
3. HTTP/1.0、2.0区别
HTTP/1.0 版本:
- 增加了 HEAD、POST 等新方法
- 增加了响应状态码
- 引入了头部,即请求头和响应头
- 在请求中加入了 HTTP 版本号
- 引入了 Content-Type ,使得传输的数据不再限于文本
HTTP/1.1 版本:
- 新增了连接管理即 keepalive ,允许持久连接
- 支持 pipeline,无需等待前面的请求响应,即可发送第二次请求
- 允许响应数据分块(chunked),即响应的时候不标明Content-Length,客户端就无法断开连接,直到收到服务端的 EOF ,利于传输大文件
- 新增缓存的控制和管理
- 加入了 Host 头,用在你一台机子部署了多个主机,然后多个域名解析又是同一个 IP,此时加入了 Host 头就可以判断你到底是要访问哪个主机
HTTP/2 版本:
- 是二进制协议,不再是纯文本
- 支持一个 TCP 连接发起多请求,移除了 pipeline
- 利用 HPACK 压缩头部,减少数据传输量
- 允许服务端主动推送数据
4. HTTP、HTTPS区别
- http 是明文传输,而 https 是加密传输,所以基本上市面上的网站用的都是 https 协议,因为明文传输很容易被中间人抓包然后获取一些敏感信息。而加密传输中间人只能获取加密的数据
- https 是基于 http 上又加了 SSL(Secure Sockets Layer)或 TLS(Transport Layer Security) 协议来实现的加密传输
- https 传输的过程使用对称加密,这比非对称加密更加高效
5. TCP解决什么问题
TCP(Transmission Control Protocol),可以看到是一个传输控制协议,重点就在这个控制
- 控制什么?
- 控制可靠、按序地传输以及端与端之间的流量控制。需要更加智能,加个拥塞控制,为整体网络的情况考虑
6. TCP和UDP区别
- TCP:面向连接的协议,它提供有序、可靠的数据传输,有确认应答、超时重传、流量控制和拥塞控制等机制
- 可靠传输场景。eg:文件传输、电商网站等
- UDP:无连接协议,它不保证数据的可靠性,仅传输数据,也不会等待对方的响应,没有顺序、流量和拥塞控制,也因此它的传输速度更快
- 游戏、直播等对数据可靠性要求不高的场景
7. TCP?IP层不能控制?
- 网络是分层实现的,网络协议的设计就是为了通信,从链路层到 IP 层其实就已经可以完成通信了
- 链路层不可或缺毕竟电脑都是通过链路相互连接的,然后 IP 充当了地址的功能,所以通过 IP 找到了对方就可以进行通信了
把控制的逻辑独立出来成 TCP 层,IP 层只进行寻址跳转,提升网络整体的传输效率
- 之所以要提取出一个 TCP 层来实现控制是因为 IP 层涉及到的设备更多,一条数据在网络上传输需要经过很多设备,而设备之间需要靠 IP 来寻址

假如 A 要传输给 F 一个积木,但是无法直接传输到,需要经过 B、C、D、E 这几个中转站。 两种情况:
- 假设 BCDE 都需要关心这个积木搭错了没,都拆开包裹仔细的看看,没问题了再装回去,最终到了 F 的手中
- 假设 BCDE 都不关心积木的情况,来啥包裹只管转发就完事了,由最终的 F 自己来检查这个积木答错了没
明显是第二种效率高,转发的设备不需要关心这些事,只管转发就完事!
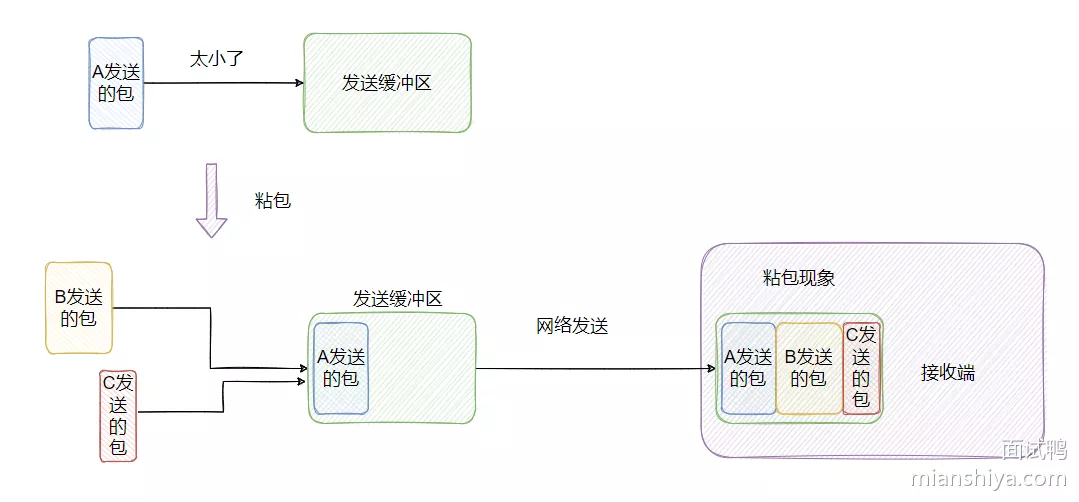
8. TCP的粘包和拆包
粘包与半包只有在 TCP 传输的时候才会有,像 UDP 是不会有这种情况的,原因是因为 TCP 是面向流的,数据之间没有界限的,而 UDP 是有的界限的
- TCP 的包没有报文长度,而 UDP 的包有报文长度,这也说明了 TCP 为什么是流式
- TCP 有发送缓冲区的概念,UDP 实际上没这个概念
半包: 假设 TCP 一次传输的数据大小超过发送缓冲区大小,那么一个完整的报文就需要被拆分成两个或更多的小报文。当接收端收到不完整的数据,是无法解析成功的
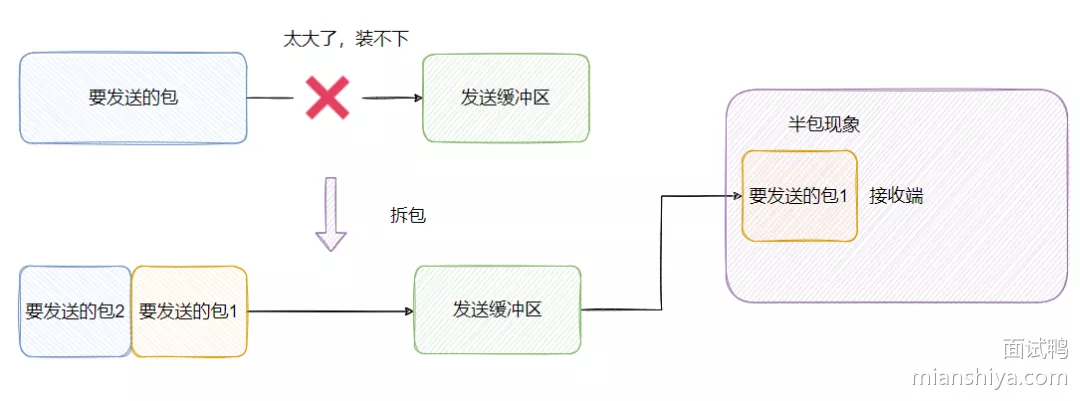
粘包: 如果 TCP 一次传输的数据大小小于发送缓冲区,那么可能会跟别的报文合并起来一块发送
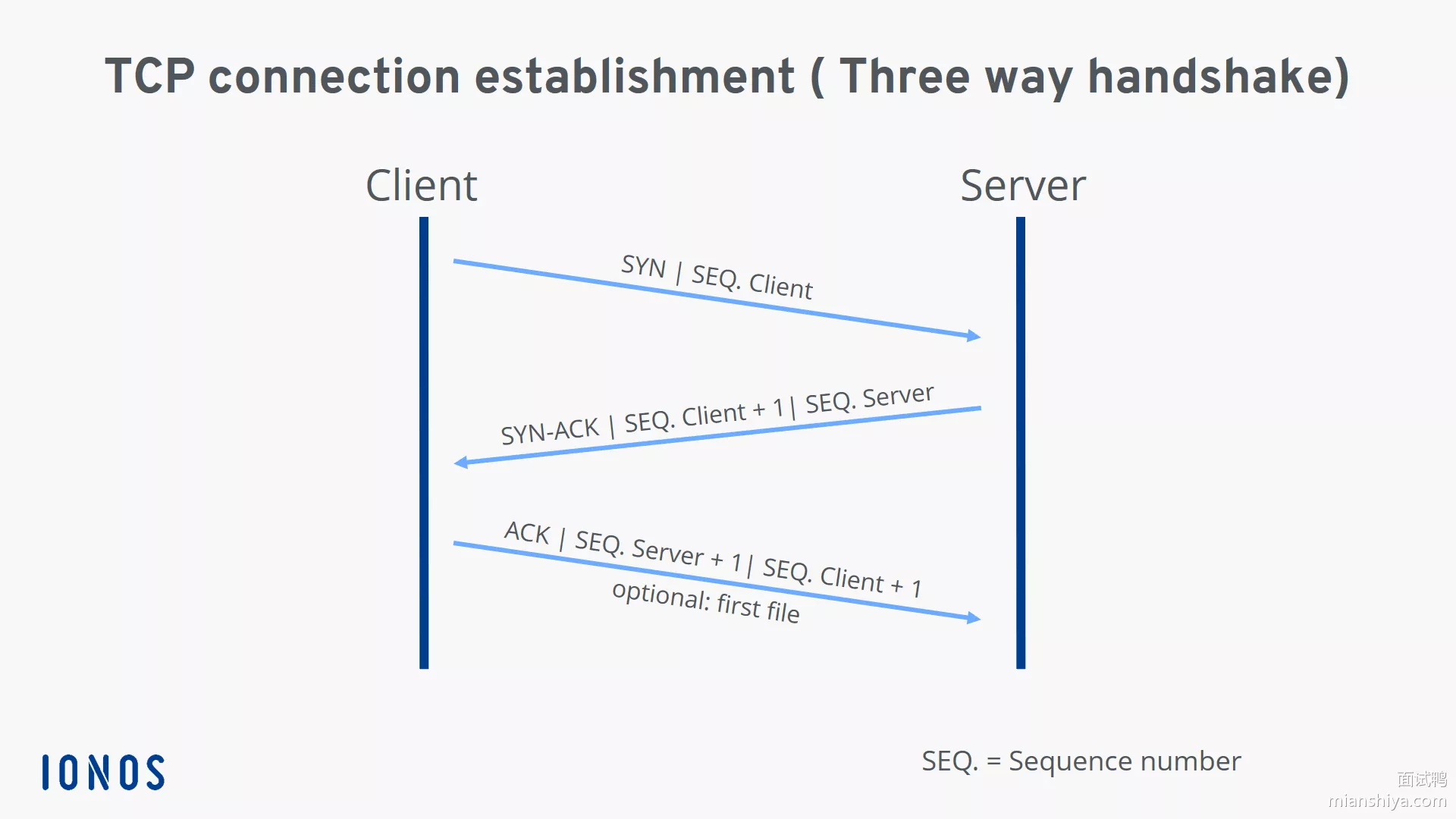
9. TCP的三次握手
具体流程:
- 客户端首先发送一个SYN(同步序列编号)消息给服务器
- 服务器收到后回复一个SYN-ACK(同步序列编号-确认)消息
- 最后客户端再发送一个ACK(确认)消息确认服务器已经收到SYN-ACK消息
从而完成三次握手,建立起一个可靠的TCP连接
10. 初始序列号ISN怎么取值
想象一下如果写死一个值,比如 0 ,那么假设已经建立好连接了,client 也发了很多包比如已经第 20 个包了,然后网络断了之后 client 重新,端口号还是之前那个,然后序列号又从 0 开始,此时服务端返回第 20 个包的ack,客户端是不是傻了?
所以 RFC793 中认为 ISN 要和一个假的时钟绑定在一起
- ISN 每四微秒加一,当超过 2 的 32 次方之后又从 0 开始,要四个半小时左右发生 ISN 回绕
- 所以 ISN 变成一个递增值,真实的实现还需要加一些随机值在里面,防止被不法份子猜到 ISN
11. SYN超时了怎么处理
也就是 client 发送 SYN 至 server 然后就挂了,此时 server 发送 SYN+ACK 就一直得不到回复,怎么办?
- 重试,但是不能连续快速重试多次,假设 client 掉线了,你总得给它点时间恢复吧,所以需要慢慢重试,阶梯性重试
- 在 Linux 中就是默认重试 5 次,并且就是阶梯性的重试,间隔就是1s、2s、4s、8s、16s,再第五次发出之后还得等 32s 才能知道这次重试的结果,所以说总共等63s 才能断开连接
12. SYN Flood攻击有听过吗
SYN 超时需要耗费服务端 63s 的时间断开连接,也就说 63s 内服务端需要保持这个资源,所以不法分子就可以构造出大量的 client 向 server 发 SYN 但就是不回 server
- 使得 server 的 SYN 队列耗尽,无法处理正常的建连请求
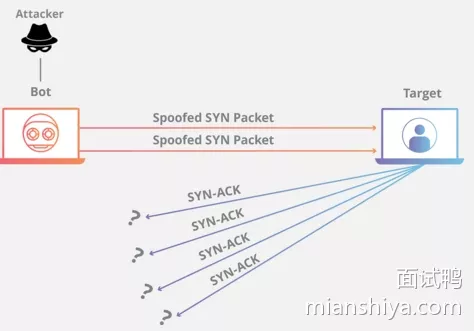
- 可以开启
tcp_syncookies,那就用不到 SYN 队列了- SYN 队列满了之后 TCP 根据自己的 ip、端口、然后对方的 ip、端口,对方 SYN 的序号,时间戳等一波操作生成一个特殊的序号(即 cookie)发回去,如果对方是正常的 client 会把这个序号发回来,然后 server 根据这个序号建连
- 调整
tcpsynackretries减少重试的次数 - 设置
tcpmaxsyn_backlog增加 SYN 队列数 - 设置
tcp_abortonoverflowSYN 队列满了直接拒绝连接
13. TCP四次挥手
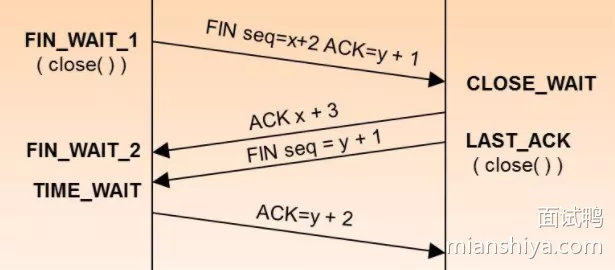
- 一方发送了最后一个数据包后,它会发送一个
FIN(结束)消息 - 收到
FIN消息的一方会发送一个ACK(确认)消息确认收到FIN消息,然后等待对方的ACK消息 - 当双方都发送了
FIN和ACK消息后,连接被关闭
14. 为什么要四次挥手
因为 TCP 是全双工协议,也就是说双方都要关闭,每一方都向对方发送 FIN 和回应 ACK
主动关闭方的状态是 FINWAIT1 到 FINWAIT2 然后再到 TIMEWAIT,而被动关闭方是 CLOSEWAIT 到 LAST_ACK
15. 挥手一定需要四次吗
- 假设 Client 已经没有数据发送给 Server 了,所以它发送
FIN给 Server 表明自己数据发完了,不再发了,如果这时候 Server 还是有数据要发送给 Client 那么它就是先回复ACK,然后继续发送数据 - 等 Server 数据发送完了之后再向 Client 发送
FIN表明它也发完了,然后等 Client 的ACK这种情况下就会有四次挥手 - 那么假设 Client 发送
FIN给 Server 的时候 Server 也没数据给 Client,那么 Server 就可以将ACK和它的FIN一起发给 Client ,然后等待 Client 的ACK,这样不就三次挥手了?
16. 为什么要有TIME_WAIT
- 断开连接发起方在接受到接受方的
FIN并回复ACK之后并没有直接进入CLOSED状态,而是进行了一波等待,等待时间为 2MSL - MSL(Maximum Segment Lifetime),即报文最长生存时间,RFC 793 定义的 MSL 时间是 2 分钟,Linux 实际实现是 30s,那么 2MSL 是一分钟
那么为什么要等 2MSL 呢?
- 就是怕被动关闭方没有收到最后的 ACK,如果被动方由于网络原因没有到,那么它会再次发送 FIN, 此时如果主动关闭方已经 CLOSED 那就傻了,因此等一会儿
- 假设立马断开连接,但是又重用了这个连接,就是五元组完全一致,并且序号还在合适的范围内,虽然概率很低但理论上也有可能,那么新的连接会被已关闭连接链路上的一些残留数据干扰,因此给予一定的时间来处理一些残留数据
17. 等待2MSL会产生什么问题
- 如果服务器主动关闭大量的连接,那么会出现大量的资源占用,需要等到 2MSL 才会释放资源
- 如果是客户端主动关闭大量的连接,那么在 2MSL 里面那些端口都是被占用的,端口只有 65535 个(这个概率很低),如果端口耗尽了就无法发起送的连接了
18. 如何解决2MSL产生的问题
- 快速回收: 即不等 2MSL 就回收, Linux 的参数是
tcp_tw_recycle,还有tcp_timestamps(默认打开)- 不建议开启,而且 Linux 4.12 版本后已经删除该参数
- 重用: 即开启
tcp_tw_reuse当然也需要tcp_timestamps- 重点,
tcp_tw_reuse是用在连接发起方的,而服务端基本上是连接被动接收方 tcp_tw_reuse是发起新连接的时候,可以复用超过 1s 的处于TIME_WAIT状态的连接,所以压根没有减少服务端的压力- 它重用的是发起方处于
TIME_WAIT的连接
- 重点,
SO_REUSEADDR、tcp_tw_reuse区别- 首先
tcp_tw_reuse是内核选项,SO_REUSEADDR是用户态选项 SO_REUSEADDR主要用在启动服务时,如果此时端口被占用并且这个连接处于TIME_WAIT状态,那么可以重用这个端口,如果不是TIME_WAIT,那就报Address already in use- 都不行,而且
tcp_tw_reuse和tcp_tw_recycle,其实是违反 TCP 协议的
- 首先
调小 MSL 的时间,不过也不太安全。要么调整 tcp_max_tw_buckets 控制 TIME_WAIT 的数量,不过默认值已经很大了 180000,应该是用来对抗 DDos 攻击的
所以建议是服务端不要主动关闭,把主动关闭方放到客户端。毕竟服务器是一对很多很多服务,资源比较宝贵
19. 超时重传机制解决什么问题
TCP 要提供可靠的传输,那么网络又是不稳定的,如果传输的包对方没收到却又得保证可靠,就必须重传
- TCP 的可靠性是靠确认号的。eg:我发给你1、2、3、4这4个包,你告诉我你现在要 5 那说明前面四个包你都收到了
- 注意,SeqNum 和 ACK 都是以字节数为单位的,也就是说假设你收到了1、2、4 但是 3 没有收到你不能 ACK 5,如果你回了 5 那么发送方就以为你5之前的都收到了
- 所以只能回复确认最大连续收到包,也就是 3
发送方不清楚 3、4 这两个包到底是还没到呢还是已经丢了,于是发送方需要等待,这等待的时间就比较讲究了
- 如果太心急可能 ACK 已经在路上了,重传就是浪费资源了
- 如果太散漫,那么接收方急死了
RTT(Round Trip Time)来回一趟的时间,然后根据这个时间制定 RTO(Retransmission Timeout,超时重传的时间)
RFC793 定义的公式如下:
- 先采样 RTT
- SRTT = ( ALPHA * SRTT ) + ((1-ALPHA) * RTT)
- RTO = min[UBOUND,max[LBOUND,(BETA*SRTT)]]
ALPHA 是一个平滑因子取值在
0.8-0.9之间,UBOUND 就是超时时间上界-1分钟,LBOUND 是下界-1秒钟,BETA 是一个延迟方差因子,取值在1.3-2.0
问题:RTT 采样的时间用一开始发送数据的时间到收到 ACK 的时间作为样本值,还是重传的时间到 ACK 的时间作为样本值?
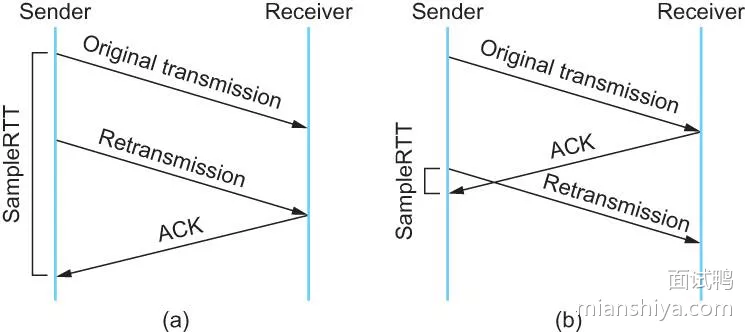
- 从图中就可以看到,一个时间算长了,一个时间算短了,这有点难,因为你不知道这个 ACK 到底是回复谁的
- 发生重传的来回我不采样不就好了,不知道这次 ACK 到底是回复谁的,就不管他,就采样正常的来回
Karn / Partridge 算法,不采样重传的RTT
- 问题,eg:某一时刻网络突然就是很差,不管重传,那么还是按照正常的 RTT 来算 RTO, 那么超时的时间就过短了,于是在网络很差的情况下还疯狂重传加重了网络的负载
- 因此 Karn 算法就很粗暴,发生重传就将现在的 RTO 翻倍
又搞了个 Jacobson / Karels Algorithm 算法
- 把最新的 RTT 和平滑过的 SRTT 做了波计算得到合适的 RTO
20. 为什么还需要快速重传机制
超时重传是按时间来驱动的,如果是网络状况真的不好的情况,超时重传没问题,但是如果网络状况好的时候,只是恰巧丢包了,那等这么长时间就没必要
- 快速重传:引入了数据驱动重传。发送方如果连续三次收到对方相同的确认号,那么马上重传数据
- 因为连续收到三次相同 ACK 证明当前网络状况是 ok 的,确认是丢包了,于是立马重发,没必要等这么久

21. SACK的引入解决什么问题
SACK(Selective Acknowledgment),为了解决发送方不知道该重传哪些数据的问题
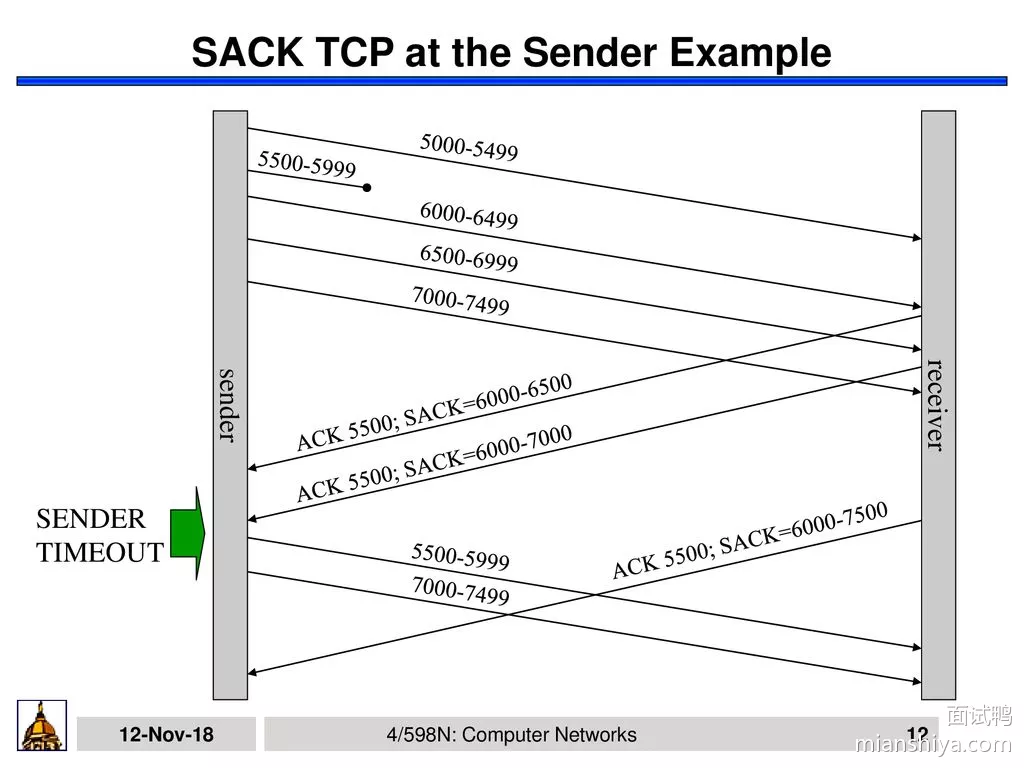
SACK 就是接收方会回传它已经接受到的数据,这样发送方就知道哪一些数据对方已经收到了,所以就可以选择性的发送丢失的数据。
- 如图,通过 ACK 告知我接下来要 5500 开始的数据,并一直更新 SACK,
6000-6500我收到了,6000-7000我收到了,6000-7500我收到了,发送方很明确的知道,5500-5999的那一波数据应该是丢了,于是重传 - 而且如果数据是多段不连续的,SACK 也可以发送,eg:
SACK 0-500, 1000-1500, 2000-2500。就表明这几段已经收到了
22. D-SACK是什么
D-SACK 是 SACK 的扩展,利用 SACK 的第一段来描述重复接受的不连续的数据序号,如果第一段描述的范围被 ACK 覆盖,说明重复了,比如我都 ACK 到 6000了你还给我回 SACK 5000-5500 呢?
- 说白了就是从第一段的反馈来和已经接受到的 ACK 比一比,参数是
tcp_dsack,Linux 2.4 之后默认开启
知道重复了有什么用呢?
- 知道重复了说明对方收到刚才那个包了,所以是回来的 ACK 包丢了
- 是不是包乱序的,先发的包后到?
- 是不是自己太着急了,RTO 太小了?
- 是不是被数据复制了,抢先一步呢?
23. 滑动窗口作用
TCP 有序号,并且还有重传,还需要根据情况来控制一下发送速率,因为网络是复杂多变的,有时候就会阻塞住,而有时候又很通畅
- 发送方需要知道接收方的情况,好控制一下发送速率,不至于接受方接受不过来
- 因此 TCP 就有个叫滑动窗口的东西来做流量控制,也就是接收方告诉发送方还能接受多少数据,然后发送方就可以根据这个信息来进行数据发送
以下是发送方维护的窗口(黑色圈起来的)
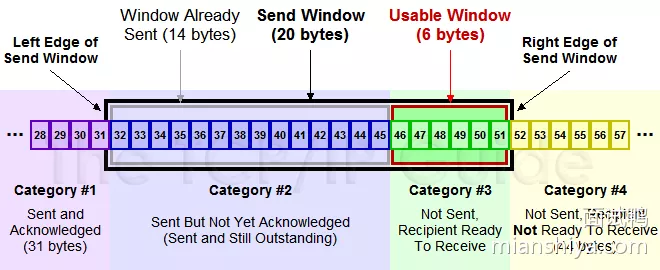
#1:已收到 ACK 的数据#2:已经发出去但是还没收到 ACK 的数据#3:在窗口内可以发送但是还没发送的数据#4:还不能发送的数据
然后此时收到了 36 的 ACK,并且发出了 46-51 的字节,于是窗口向右滑动了
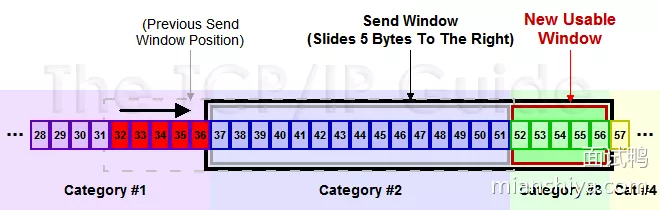
TCP/IP Guide 上还有一张完整的图,画的十分清晰
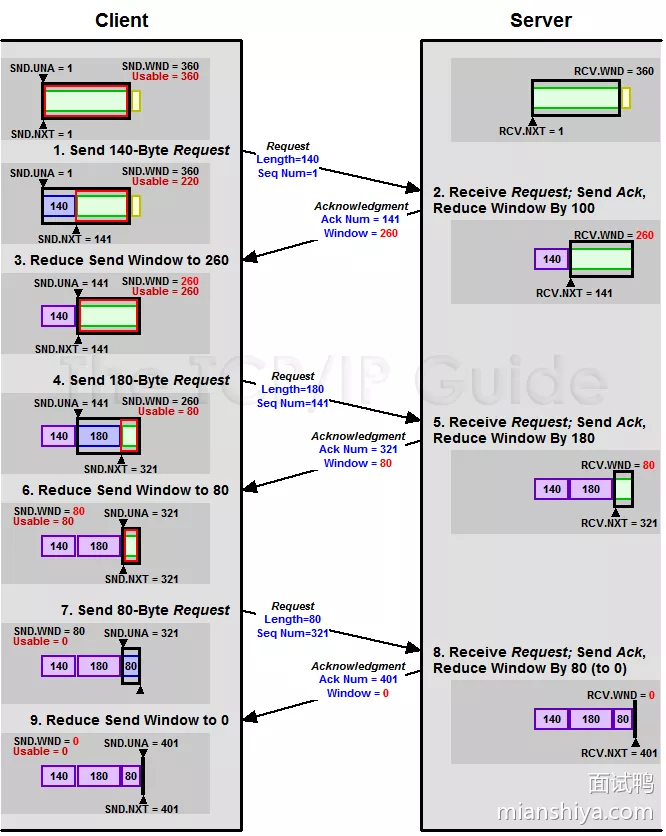
24. 已经有滑动窗口了还要拥塞控制?
拥塞控制:因为 TCP 不仅仅就管两端之间的情况,还需要知晓一下整体的网络情形,毕竟只有都守规矩了道路才会通畅
- 重传,如果不管网络整体的情况,肯定就是对方没给 ACK ,那就无脑重传
- 如果此时网络状况很差,所有的连接都这样无脑重传,是不是网络情况就更差了,更加拥堵
所以需要个拥塞控制,来避免这种情况
25. 拥塞控制步骤
主要有以下几个步骤:
- 慢启动,探探路
- 拥塞避免,感觉差不多了减速看看
- 拥塞发生快速重传/恢复
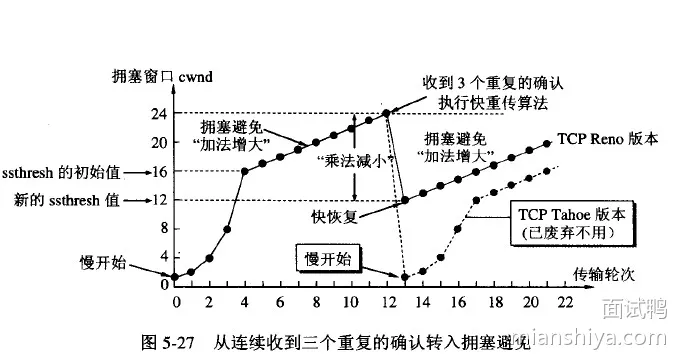
1)慢启动,初始化 cwnd(Congestion Window)为 1,然后每收到一个 ACK 就 cwnd++ 并且每过一个 RTT,cwnd = 2*cwnd
- 线性中带着指数,指数中又夹杂着线性增
- 然后到了一个阈值,也就是 ssthresh(slow start threshold)时
2)拥塞避免阶段
- 这个阶段是每收到一个 ACK 就
cwnd = cwnd + 1/cwnd并且每一个 RTT 就cwnd++ - 可以看到都是线性增
- 然后就是一直增,直到开始丢包。重传有两种,一种是超时重传,一种是快速重传
3)重传
- 如果发生超时重传时,说明情况有点糟糕,于是直接把 ssthresh 置为当前 cwnd 的一半,然后 cwnd 直接变为 1,进入慢启动阶段
- 如果是快速重传,那么这里有两种实现
- 一种是 TCP Tahoe ,和超时重传一样的处理
- 一种是 TCP Reno,这个实现是把
cwnd = cwnd/2,然后把 ssthresh 设置为当前的 cwnd
4)然后进入快速恢复阶段
- 将
cwnd = cwnd + 3(因为快速重传有三次),重传 DACK 指定的包,如果再收到一个DACK则cwnd++,如果收到是正常的 ACK 那么就将 cwnd 设为 ssthresh 大小,进入拥塞避免阶段 - 可以看到快速恢复就重传了指定的一个包,那有可能是很多包都丢了,然后其他的包只能等待超时重传,超时重传就会导致 cwnd 减半,多次触发就指数级下降
5)New Reno
- 所以又搞了个 New Reno,多加了个 New,它是在没有 SACK 的情况下改进快速恢复,它会观察重传 DACK 指定的包的响应 ACK 是否是已经发送的最大 ACK,eg:你发了1、2、3、4,对方没收到 2,但是 3、4都收到了,于是你重传 2 之后 ACK 肯定是 5,说明就丢了这一个包
- 不然就是还有其他包丢了,如果就丢了一个包就是之前的过程一样,如果还有其他包丢了就继续重传,直到 ACK 是全部的之后再退出快速恢复阶段
- 简单的说,就是一直探测到全部包都收到了再结束这个环节
还有个 FACK,它是基于 SACK 用来作为重传过程中的拥塞控制,相对于上面的 New Reno 就知道它有 SACK 所以不需要一个一个试过去,具体。。。
26. 还有哪些拥塞控制算法
维基上看有这么多

27. ARP、RARP区别
- ARP(Address Resolution Protocol)将 IP 地址转换为 MAC 地址,因为最终需要找到 MAC 地址才能跟具体的设备通信
- RARP(Reverse Address Resolution Protocol)用于将 MAC 地址转换为 IP 地址
- eg:一些设备启动时,需要根据 RARP 来得知分配给它的 ip 是什么
28. TCP/IP四层模型是什么
四层主要指的是:网络接口层、互联网层、传输层和应用层
- 网络接口层:负责在计算机和网络硬件之间传输数据
- 互联网层(网络层):通过 IP 协议提供数据包的路由和转发
- 传输层:通过 TCP 和 UDP 协议提供端到端的通信服务
- 应用层:通过各种协议提供网络应用程序的功能,如 HTTP 等
29. OSI七层模型是什么
OSI七层模型是计算机网络通信的标准模型,从底层到顶层依次为:
- 物理层,主要描述物理层面的传输,eg:光纤、电缆
- 数据链路层,可以认为是 MAC 层面相邻节点的传输
- 网络层,IP 层面的寻址、路由
- 传输层,TCP 和 UDP 层 的传输
- 会话层,负责会话状态的保持、管理与同步
- 表示层,一些数据的转化,压缩和编码
- 应用层,http 之类的协议的交互转化
30. Cookie、Session、Token区别
- Cookie:存储在浏览器,生命周期可以由服务器端设置
- Session:存储在服务器,生命周期由服务器端控制
- Token(eg:JWT):存储在客户端,是一个加密的令牌,可以跨多个会话使用
Cookie 和 Session 更适合用于单次会话的认证和状态管理,而 Token 更适合用于跨会话的认证和状态管理
31. JWT_Token听过吗
Token(eg:JWT)其实就是一个加密的令牌,服务端通过一定的方式将用户的信息加密生成一个 Token,后续客户端带着这个 token 来访问服务端时,服务端可以解密得到对应的用户信息,这样就能进行身份和权限的验证了
32. 对DNS的理解
DNS(Domain Name System)是一个用于将域名转换为 IP 地址的分布式数据库系统
- 工作原理:当用户输入一个域名时,DNS 服务器会查询该域名对应的 IP 地址,并将结果返回给用户。这样,用户就可以通过域名访问网站,而不需要记住复杂的 IP 地址
- DNS 简化了网络访问过程,提高了网络通信的效率
33. 对CDN的理解?
CDN(Content Delivery Network)是一种分布式网络架构,用于加速互联网内容的分发
背景:因为网络传输有距离限制,部署杭州的服务器,不同地区的用户访问得到响应的时长是不一样的,杭州的用户来访问肯定比美国的用户来访问快多了。所以就弄了个 CDN 来加快内容的分发
工作原理:它通过在全球多个地理位置部署服务器,当用户请求内容时,CDN 会根据用户的地理位置,将请求转发到最近的缓存服务器上。这样可以减少数据传输的延迟,提高用户访问速度,同时减轻源服务器的负载
CDN 通常用于加速静态内容(如图片、视频、静态页面等)的访问,提高网站的性能和用户体验
34. 浏览器输入域名回车
简单流程:
- 浏览器会向DNS服务器发送一个查询请求,请求将域名解析为对应的 IP 地址。DNS 服务器返回 IP 地址
- 浏览器使用该 IP 地址向服务器发起 HTTP 请求
- 服务器收到请求后,做对应的处理,且返回相应的网页内容。浏览器接收到网页内容后,解析 HTML、CSS、JS 等文件,最终显示网页