09-tuning
1. CPU利用率高/飙升
CPU飙升只是一种现象,其中具体的问题可能有很多种,只是借这个现象切入
注:CPU使用率是衡量系统繁忙程度的重要指标。但是CPU使用率的安全阈值是相对的,取决于系统的IO密集型还是计算密集型。一般计算密集型应用CPU使用率偏高load偏低,IO密集型相反
- 常见原因
- 频繁gc
- 业务逻辑死循环
- 上下文切换频繁
- 线程阻塞
- io_wait
- 排查及解决方案。定位CPU的问题一般可以分为以下几个步骤:
- 定位进程
- 定位线程
- 查看线程信息
- 定位具体方法(代码)
1. 定位进程
- 通过
top -c(然后按P按cpu排序),htop等工具定位到具体的高CPU进程 - 假设定位到的进程ID为14279
- 或者使用jps查看java进程号
top - 13:48:34 up 97 days, 19:04, 1 user, load average: 0.09, 0.08, 0.10
Tasks: 284 total, 1 running, 283 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.5 us, 0.7 sy, 0.0 ni, 98.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8168236 total, 231696 free, 3660496 used, 4276044 buff/cache
KiB Swap: 969964 total, 969964 free, 0 used. 4197860 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14293 faceless 20 0 4508772 97036 18112 S 45 1.2 152:35.42 java
14279 faceless 20 0 4508772 97036 18112 S 23 1.2 0:00.00 java
14282 faceless 20 0 4508772 97036 18112 S 0.0 1.2 0:00.37 java
一般超过80%就是比较高的,80%左右是合理情况
2. 定位线程
top -H -p 14279定位占cpu的线程
方法一:手动定位
- 使用jstack分别查找上面的线程的具体内容。eg:第一个线程14293
# 将线程ID转换为16进制
printf '0x%x' 14293 => 0x37d5
# 通过jstack查看进程中该线程的信息:
# `jstack pid | grep tid` 找到线程堆栈
jstack 12816 | grep 0x3211 -A 30
# 【示例输出】
"VM Periodic Task Thread" os_prio=0 tid=0x00007ff1802d5800 nid=0x37d5 waiting on condition
- 也可以直接使用
jstack 14279 > ~/tmp/pid-14279.log显示所有线程,然后手动寻找对应的ID - 更常见的是对整个jstack文件进行分析,通常会比较关注
WAITING和TIMED_WAITING的部分,BLOCKED就不用说了。可以使用命令cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c来对jstack的状态有一个整体的把握,如果WAITING的类的特别多,那么多半是有问题啦
方法二:通过arthas定位
- [Arthas]支持直接通过
thread子命令显示占用cpu最高的n个线程 - 展示当前最忙的前3个线程并打印堆栈:
$ thread -n 3
"as-command-execute-daemon" Id=29 cpuUsage=75% RUNNABLE
at sun.management.ThreadImpl.dumpThreads0(Native Method)
at sun.management.ThreadImpl.getThreadInfo(ThreadImpl.java:440)
at com.taobao.arthas.core.command.monitor200.ThreadCommand$1.action(ThreadCommand.java:58)
at com.taobao.arthas.core.command.handler.AbstractCommandHandler.execute(AbstractCommandHandler.java:238)
at com.taobao.arthas.core.command.handler.DefaultCommandHandler.handleCommand(DefaultCommandHandler.java:67)
at com.taobao.arthas.core.server.ArthasServer$4.run(ArthasServer.java:276)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Number of locked synchronizers = 1
- java.util.concurrent.ThreadPoolExecutor$Worker@6cd0b6f8
"as-session-expire-daemon" Id=25 cpuUsage=24% TIMED_WAITING
at java.lang.Thread.sleep(Native Method)
at com.taobao.arthas.core.server.DefaultSessionManager$2.run(DefaultSessionManager.java:85)
"Reference Handler" Id=2 cpuUsage=0% WAITING on java.lang.ref.Reference$Lock@69ba0f27
at java.lang.Object.wait(Native Method)
- waiting on java.lang.ref.Reference$Lock@69ba0f27
at java.lang.Object.wait(Object.java:503)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133)
- 根据Arthas
thread命令打印出来的堆栈信息定位具体的业务代码,review代码并尝试定位逻辑。如有必要,还可以通过watch子命令监听某个方法的调用次数和资源占用情况
要注意的是,arthas的cpu占比,和前面两种cpu占比统计方式不同。前面两种针对的是Java进程启动开始到现在的cpu占比情况,arthas这种是一段采样间隔内,当前JVM里各个线程所占用的cpu时间占总cpu时间的百分比
定位具体方法
- GC线程
- 如果是GC线程一直在占用cpu,那么就基本确定是内存泄漏。进一步按照内存问题定位
- 业务线程
- 如果是业务线程,那么根据下一节的方法,继续定位是哪些代码占用cpu
- io_wait
- 比如磁盘空间不够导致的io阻塞
- 等待内核态锁。eg:synchronized
jstack -l pid | grep BLOCKED查看阻塞态线程堆栈- dump 线程栈,分析线程持锁情况
- arthas提供了
thread -b,可以找出当前阻塞其他线程的线程。针对 synchronized 情况
3. 上下文切换
- 针对频繁上下文问题,可以使用
vmstat命令来进行查看
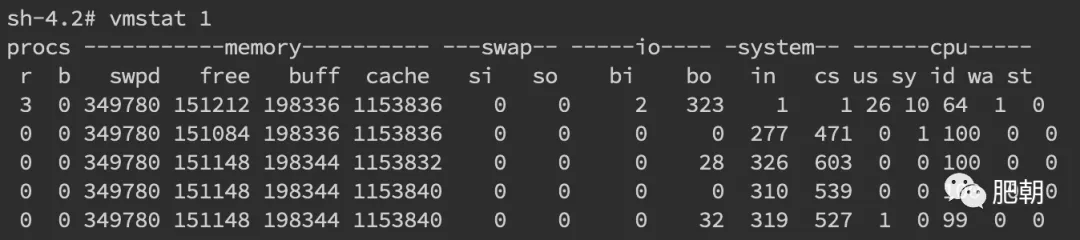
- cs(context switch)一列则代表了上下文切换的次数
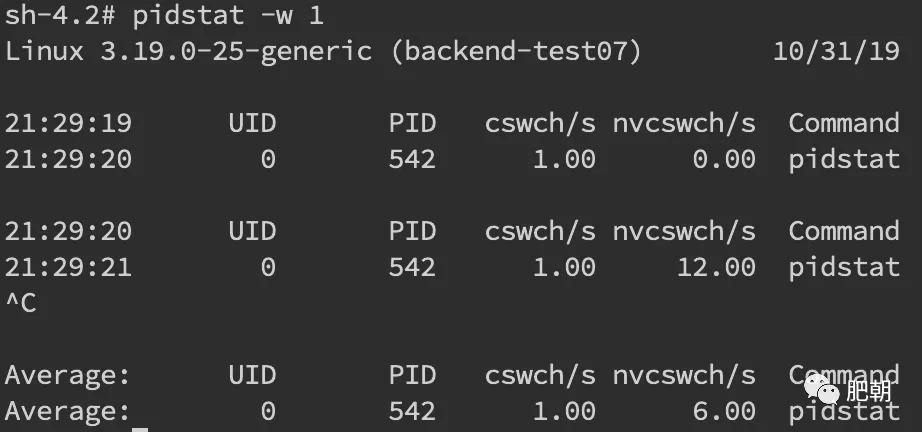
- 如果希望对特定的pid进行监控。可以使用
pidstat -w pid命令,cswch和nvcswch表示自愿及非自愿切换
2. GC问题定位解决方案
# 开启GC日志
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
1. prommotion failed
从S区晋升的Obj在Old也放不下导致FullGC(fgc回收无效则抛OOM),可能原因:
- survivor 区太小,Obj过早进入老年代
- 查看 SurvivorRatio 参数
- 大Obj分配,没有足够的内存
- dump 堆,profiler/MAT 分析Obj占用情况
- Old存在大量Obj
- dump 堆,profiler/MAT 分析Obj占用情况
- 也可以从Full_GC的效果来推断问题,正常情况下,一次Full_GC应该会回收大量内存,所以正常的堆内存曲线应该是呈锯齿形。如果你发现Full_GC之后堆内存几乎没有下降,那么可以推断:堆中有大量不能回收的Obj且在不停膨胀,使堆的使用占比超过FGC的触发阈值,但又回收不掉,导致FGC一直执行。换句话来说,可能是内存泄漏了
- 一般来说,GC相关的异常推断都需要涉及到内存分析,使用
jmap之类的工具dump出内存快照(或者 Arthas的heapdump)命令,然后使用MAT、JProfiler、JVisualVM等可视化内存分析工具
2. FullGC频繁
- 对于FGC较多的情况,其主要有如下两个特征:
- 线上多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是GC线程
- 通过jstat命令监控GC情况,可以看到FGC次数非常多,并且次数在不断增加
- FGC原因
- JVM参数设置问题。包括总内存大小、新生代和老年代的大小、Eden区和S区的大小、元空间大小、垃圾回收算法等等
- 代码中显示调用了
System.gc();。通过添加-XX:+DisableExplicitGC来禁用JVM对显示GC的响应 - 内存溢出或内存泄漏。频繁创建了大量Obj,但是无法被回收(eg:IO_Obj使用完后未调用close方法释放资源),先引发FGC,最后导致OOM
- 大Obj:系统一次性加载了过多数据到内存中(比如SQL查询未做分页),导致大Obj进入了老年代
- 程序频繁生成一些长生命周期的Obj,当这些Obj的存活年龄超过分代年龄时便会进入老年代,最后引发FGC
- 程序BUG导致动态生成了很多新类,使得 Metaspace 不断被占用,先引发FGC,最后导致OOM
3. YoungGC
- YGC过于频繁
- YGC频繁一般是短周期小Obj较多,先考虑是不是Eden区/新生代设置的太小了,看能否通过调整
-Xmn、-XX:SurvivorRatio等参数设置来解决问题。如果参数正常,但是YGC频率还是太高,就需要使用Jmap和MAT对dump文件进行进一步排查了
- YGC频繁一般是短周期小Obj较多,先考虑是不是Eden区/新生代设置的太小了,看能否通过调整
- YGC耗时过长
- 耗时过长问题就要看GC日志里耗时耗在哪一块了。以G1日志为例,可以关注Root Scanning、Object Copy、Ref Proc等阶段。Ref Proc耗时长,就要注意引用相关的Obj。Root Scanning耗时长,就要注意线程数、跨代引用。Object Copy则需要关注Obj生存周期
3. 内存问题
- 堆内内存问题:表象上主要分为OOM和StackOverflow
- 堆外内存问题
- GC问题
1. 内存溢出、内存泄漏
- 内存溢出(out of memory):指程序运行过程中无法申请到足够的内存而导致的一种错误
- 内存泄漏(memory leak):指程序中动态分配内存给一些临时Obj,但是Obj不会被GC回收,始终占用内存。即被分配的Obj可达但已无用
2. 内存溢出
- 堆内存溢出:
OutOfMemoryError:java heap space - 方法区内存溢出:
OutOfMemoryError:permgem space、OutOfMemoryError: Meta space - 线程栈溢出:
java.lang.StackOverflowError
内存溢出问题一般分为两种:
- 大峰值下瞬间创建大量Obj而导致的内存溢出 => 可通过限流处理
- 内存泄漏而导致的内存溢出 => 需要分析程序是否存在Bug
1. 栈溢出
// 没有足够的内存空间给线程分配java栈
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
- JVM方面可以通过指定
Xss来减少单个thread stack的大小 - 系统层面通过修改
/etc/security/limits.confnofile和nproc来增大os对线程的限制 - 代码问题,eg:线程池为shutdown
2. 堆溢出
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
- JVM启动参数堆内存值设定的过小
- 在内存中加载了大量的数据或缓存了过多的数据(一次性从Mysql、Redis取出过多数据)
- Obj的引用没有及时释放,使得JVM不能回收
- 代码中存在死循环或循环产生过多重复的Obj实体(在循环体内New大量的Obj)
3. 对外内存溢出
DirectByteBuffer分配内存的话,需要FGC或者手动system.gc来进行回收的
OutOfDirectMemoryError -- netty
OutOfMemoryError: Direct buffer memory -- DirectByteBuffer
3. 内存泄漏
内存泄漏分类
- 常发性内存泄漏:bug被多次执行到,每次被执行的时候都会导致一块内存泄漏
- 偶发性内存泄漏:bug只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要
- 一次性内存泄漏:bug只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。eg:在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次
- 隐式内存泄漏:程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏
Java内存泄漏的一些场景
- 过度使用静态成员属性(static fields)
- 忘记关闭已打开的资源链接(unclosed Resources)
- 没有正确的重写
equals()和hashcode()(HashMap、HashSet)
4. 磁盘问题
- 磁盘空间方面,直接使用
df -hl来查看文件系统状态 - lsof命令来确定具体的文件读写情况
lsof -p pid
robert@robertdeMacBook-Pro:~$ df -lh
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1s1 233Gi 108Gi 121Gi 48% 1295662 9223372036853480145 0% /
/dev/disk1s4 233Gi 4.0Gi 121Gi 4% 4 9223372036854775803 0% /private/var/vm
更多时候,磁盘问题还是性能上的问题。可以通过iostat -d -k -x来进行分析
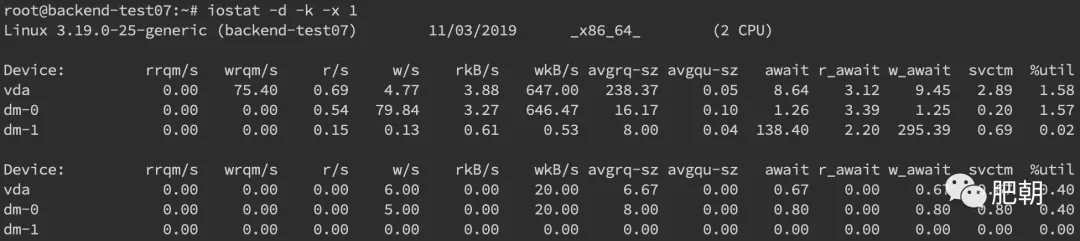
- 最后一列
%util可以看到每块磁盘写入的程度 - 而
rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了
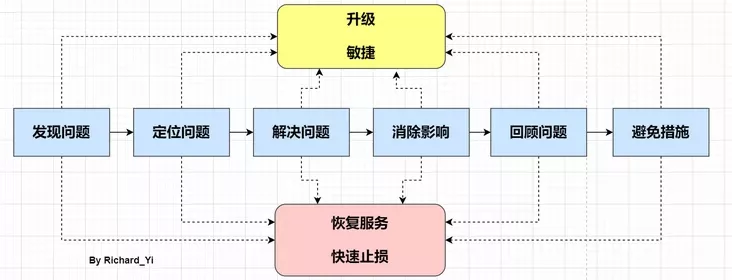
5. 线上问题解决方案
- 总体目标:尽快恢复服务/止血/止损,消除影响
- 处理手段:
- 降级(服务降级/业务降级/业务下线)
- 回滚
- 复盘流程
1. 不定期出现接口耗时现象
- 某个接口访问经常需要2~3s才能返回。一般来说,其消耗的CPU不多,而且占用的内存也不高
- 首先找到该接口,通过压测工具不断加大访问力度
- 该接口中有某个位置是比较耗时的,由于访问的频率非常高,大多数的线程最终都将阻塞于该阻塞点,这样通过多个线程具有相同的堆栈日志,基本上就可以定位到该接口中比较耗时的代码的位置
2. 线程池异常
- Java线程池以有界队列的线程池为例,当新任务提交时
- 如果运行的线程少于 corePoolSize,则创建新线程来处理请求
- 如果正在运行的线程数等于 corePoolSize,则新任务被添加到队列中,直到队列满。当队列满了后,会继续开辟新线程来处理任务,但不超过 maximumPoolSize
- 当任务队列满了并且已开辟了最大线程数,此时又来了新任务,ThreadPoolExecutor 会拒绝服务
这种线程池异常,一般可以通过开发查看日志查出原因,有以下几种原因:
- 下游服务 响应时间(RT)过长
- 下游服务异常导致的,作为消费者要设置合适的超时时间和熔断降级机制
- 另外针对这种情况,一般都要有对应的监控机制。eg:日志监控、metrics监控告警等,不要等到目标用户感觉到异常,才去查看日志
- 数据库慢 sql 或者数据库死锁
- 查看日志中相关的关键词
- Java 代码死锁
jstack –l pid | grep -i –E 'BLOCKED | deadlock'
- 应用线程池设置过小
- 可以调整应用线程池大小
3. 死锁问题
jstack可以帮助检查deadlock,并且在日志中打印具体的死锁线程信息。如下是一个产生死锁的一个jstack日志示例:
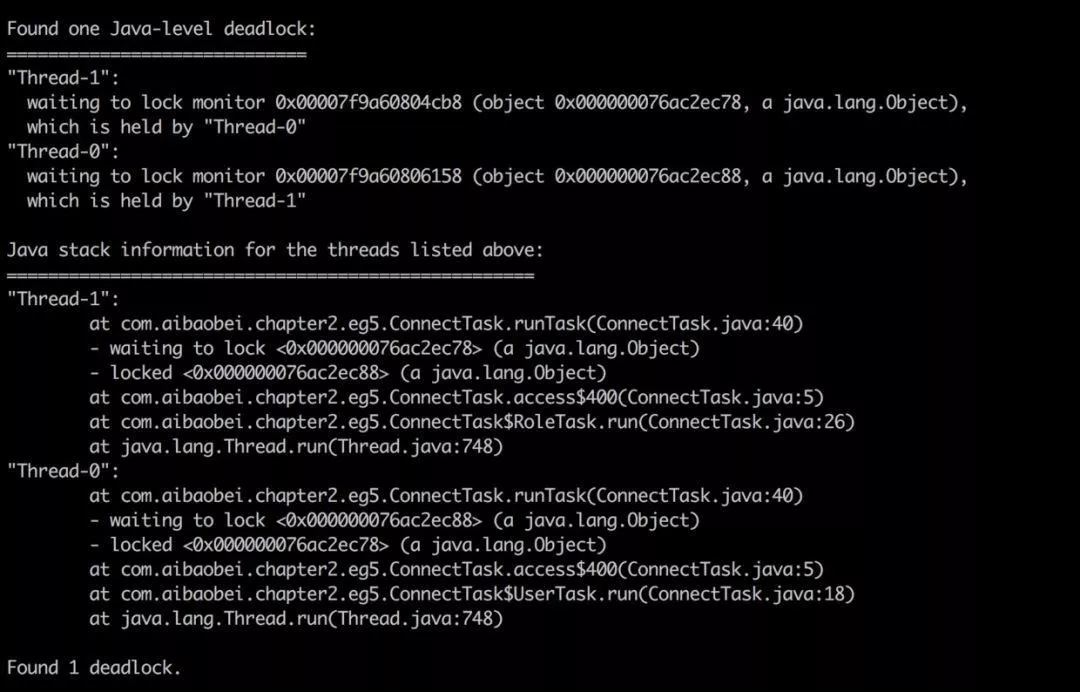
可以看到,在jstack日志的底部,其直接帮我们分析了日志中存在哪些死锁,以及每个死锁的线程堆栈信息。这里有两个用户线程分别在等待对方释放锁,而被阻塞的位置都是在ConnectTask的第5行,此时我们就可以直接定位到该位置,并且进行代码分析,从而找到产生死锁的原因
6. JVM调优
目前对于JVM的优化基本是按照应用程序的使用场景来定的,G1的原则是在吞吐量优先的情况下,降低停顿时间
JVM调优一般针对的是吞吐量和暂停时间
- 较高的吞吐量在较长时间段内,会让用户感觉上只有程序线程在执行,就认为程序运行是比较块的。
- 对于交互性较高的应用场景来说,越低的暂停时间用户体验越好
高吞吐量和低暂停时间是一对相矛盾的存在
- 调优以吞吐量为主,那么必然会降低内存回收的频率,STW变长
- 调优以低延迟为主,那么每次GC回收的垃圾必然会减少,只能通过频繁GC
参考配置G1
java -server -Xms11200m -Xmx11200m -Dfile.encoding=UTF-8 -XX:UseG1GC -XX:MaxGCPauseMillis=20 -XX:+UnlockExperimentalVMOptions -XX:InitiatingHeapOccupancyPercent=56 -Xloggc:/root/logs/app-gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/root/logs/app-java.hprof app.jar
- 2C4G linux64 jdk8
-Xmx2688M -Xms2688M -Xmn960M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M -XX:+UseG1GC
- 4C8G linux64 jdk8
-Xmx5440M -Xms5440M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M -XX:+UseG1GC
- 4C16G linux64 jdk8
-Xmx10880M -Xms10880M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M -XX:+UseG1GC
7. JVM参考配置
| 参数 | 内容 |
|---|---|
| -Xms | 初始堆大小,默认物理内存 1/64 。eg:-Xms256m |
| -Xmx | 最大堆大小,默认物理内存 1/4。eg:-Xmx512m |
| -Xmn:[g|m|k] | - 新生代大小。新生代 = Eden + 2个Survivor。实际可用空间为 = Eden + 1个Survivor,即 90%。整个JVM内存=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小 - 如果Xms和Xmx没有设置为同一个值时,堆空间扩展或收缩时,新生代大小是不会随着调整的,是固定的 - 只有Xms和Xmx是同一个值得时候,才使用Xmn选项。 |
| -Xss | - 设置每个线程的堆栈大小 - JDK1.5+ 每个线程堆栈大小为 1M,一般来说如果栈不是很深的话,1M是绝对够用了的 |
| -XX:NewRatio | 新生代与老年代的比例。eg:–XX:NewRatio=2,则新生代占整个堆空间的1/3,老年代占2/3 |
| -XX:SurvivorRatio | 新生代中 Eden(8) 与 Survivor(1+1) 的比值。默认值为 8。即 Eden 占新生代空间的 8/10,另外两个 Survivor 各占 1/10 |
| -XX:PermSize | 永久代(方法区)的初始大小 |
| -XX:MaxPermSize | 永久代(方法区)的最大值 |
| -XX:+PrintGCDetails | 打印 GC 信息 |
| -XX:+HeapDumpOnOutOfMemoryError | 让JVM在发生内存溢出时 Dump 出当前的内存堆转储快照,以便分析用 |
| -XX:NewSize=[g|m|k] | 新生代最小空间大小 |
| -XX:MaxNewSize | 新生代最大空间大小 |
| -XX:MetaspaceSize | class_metadata的初始空间配额,以bytes为单位,达到该值就会触发GC进行类型卸载,同时GC会对该值进行调整 |
| -XX:MaxMetaspaceSize | 可以为class_metadata分配的最大空间。默认是没有限制的 |
| MinHeapFreeRatio | GC后如果发现空闲堆内存占到整个预估堆内存的N%(百分比),则放大堆内存的预估最大值 |
| MaxHeapFreeRatio | GC后如果发现空闲堆内存占到整个预估堆内存的N%(百分比),则收缩堆内存的预估最大值,预估堆内存是堆大小动态调控的重要选项之一。堆内存预估最大值一定小于或等于固定最大值(-Xmx指定的数值)。前者会根据使用情况动态调大或缩小,以提高GC回收的效率 |
- 注意:JDK8去掉了
-XX:PermSize和-XX:MaxPermSize,新增了-XX:MetaspaceSize和-XX:MaxMetaspaceSize - JVM会根据堆的空闲情况动态调整推大小,空余大于70%,会减少到
-Xms,空余小于40%,会增大到-Xmx Xmn设置新生代大小,等同于同时设置NewSize和MaxNewSize- 如
-Xmn128m等同于:-XX:NewSize=128m -XX:MaxNewSize=128m
- 如
- 一般实际生产应用中,Xms与Xmx设置为同一个值,避免JVM GC频繁缩容扩容
1. 参考配置CMS
JAVA_OPTS="-server -Xss256k $JAVA_OPTS"
JAVA_OPTS="${JAVA_OPTS} -XX:SurvivorRatio=10"
JAVA_OPTS="${JAVA_OPTS} -XX:+UseConcMarkSweepGC -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80"
JAVA_OPTS="${JAVA_OPTS} -XX:+UseCMSInitiatingOccupancyOnly"
JAVA_OPTS="${JAVA_OPTS} -XX:+DisableExplicitGC"
JAVA_OPTS="${JAVA_OPTS} -verbose:gc -Xloggc:/root/logs/app-gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
JAVA_OPTS="${JAVA_OPTS} -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/root/logs/app-java.hprof"
JAVA_OPTS="${JAVA_OPTS} -Djava.awt.headless=true"
JAVA_OPTS="${JAVA_OPTS} -Dsun.net.client.defaultConnectTimeout=10000"
JAVA_OPTS="${JAVA_OPTS} -Dsun.net.client.defaultReadTimeout=30000"
java -Djava.security.egd=file:/dev/./urandom $JAVA_OPTS -jar ./app.jar $*
-Xint- 解释执行不对代码进行编译,这种模式抛弃了 JIT 可能带来的性能优势,毕竟解释器(interpreter)是逐条读入,逐条解释运行的;
-Xcomp- 关闭解释器,不要进行解释执行,或者叫作最大优化级别。
-Xcomp会导致JVM启动变慢非常多,同时有些JIT编译器优化方式,eg:分支预测,如果不进行 profiling,往往并不能进行有效优化
- 关闭解释器,不要进行解释执行,或者叫作最大优化级别。
8. JVM命令
1. jstat
jstat:一个极强的监视VM内存工具。可以用来监视VM内存内的各种堆和非堆的大小及其内存使用量
jstat -class pid:显示加载class的数量,及所占空间等信息jstat -compiler pid:显示VM实时编译的数量等信息jstat -gc pid:可以显示gc的信息,查看gc的次数,及时间jstat -gcnew pid:newObj的信息jstat -gcnewcapacity pid:newObj的信息及其占用量jstat -gcold pid: oldObj的信息jstat -gcoldcapacity pid:oldObj的信息及其占用量jstat -gcpermcapacity pid:permObj的信息及其占用量jstat -util pid:统计gc信息统计jstat -printcompilation pid:当前VM执行的信息jstat -gcutil pid 1000 10:1000ms统计一次gc情况统计10次
# 查看内存使用情况
jstat -gcutil pid
jstat -gcutil 38141
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
69.31 0.00 32.37 45.65 97.67 95.47 20 0.160 2 0.169 0.329
- S0:Survivor 0区的空间使用率
- S1:Survivor 1区的空间使用率
- E:Eden区的空间使用率
- O:老年代的空间使用率
- M:元数据的空间使用率
- CCS:类指针压缩空间使用率
- YGC:新生代GC次数
- YGCT:新生代GC总时长
- FGC:Full GC次数
- FGCT:Full GC总时长
- GCT:总共的GC时长
jstat -gc pid
示例:
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
10752.0 10752.0 0.0 0.0 65536.0 2621.5 175104.0 0.0 4480.0 779.9 384.0 76.4 0 0.000 0 0.000 0.000
- S0C:s0容量
- S1C:s1容量
- S0U:s0使用情况
- S1U:s1使用情况
- EC:eden总容量
- EU:eden已用情况
- OC:old总容量
- OU:old已用情况
- PC:perm容量
- PU:perm已用
- YGC:新生代gc次数
- YGCT:新生代gc回收时间
- FGC:老年代gc次数
- FGCT:老年代gc回收时间
- GCT:gc总消耗时间
2. jmap
# 查看JVM内存Obj分布情况
jmap -histo 17592
# 生成堆转储快照dump文件
jmap -dump:format=b,file=heapdump.phrof pid
# 查看目前堆情况
jmap -heap pid
[xixicat@cloud01 ~]$ jmap -heap 22869
Attaching to process ID 22869, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 23.21-b01
using thread-local object allocation.
Garbage-First (G1) GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 5368709120 (5120.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 17592186044415 MB
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 20971520 (20.0MB)
MaxPermSize = 268435456 (256.0MB)
G1HeapRegionSize = 2097152 (2.0MB)
Heap Usage:
G1 Heap:
regions = 2560
capacity = 5368709120 (5120.0MB)
used = 3826721792 (3649.4462890625MB)
free = 1541987328 (1470.5537109375MB)
71.27824783325195% used
G1 Young Generation:
Eden Space:
regions = 1068
capacity = 2808086528 (2678.0MB)
used = 2239758336 (2136.0MB)
free = 568328192 (542.0MB)
79.76101568334578% used
Survivor Space:
regions = 29
capacity = 60817408 (58.0MB)
used = 60817408 (58.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 1000
capacity = 2499805184 (2384.0MB)
used = 1524048896 (1453.4462890625MB)
free = 975756288 (930.5537109375MB)
60.96670675597735% used
Perm Generation:
capacity = 171966464 (164.0MB)
used = 170752872 (162.8426284790039MB)
free = 1213592 (1.1573715209960938MB)
99.29428565792921% used
48213 interned Strings occupying 5246936 bytes.
3. jstack
jstack(Stack Trace for Java)命令用于生成JVM当前时刻的线程快照(一般称为threaddump或javacore文件)
jstack 31034 > ~/run/dump31034 # dump java线程信息
grep Thread.State dump31034 | awk '{print $2$3$4$5}' | sort | uniq -c # 统计所有线程的状态
========>
8 RUNNABLE
1 TIMED_WAITING(onobjectmonitor)
2 WAITING(onobjectmonitor)
- jstack默认只能看到java栈
jstack -m可以看到线程的Java栈和native栈
jstack工具主要选项
| 选项 | 作用 |
|---|---|
| -F | 当正常输出的请求不被响应时,强制输出线程堆栈 |
| -l | 除堆栈外,显示关于锁的附加信息 |
| -m | 如果调用到本地方法的话,可以显示 C/C++ 的堆栈 |
4. jinfo
# 用于查看jvm参数
jinfo -flag NewSize pid
jinfo -flag OldSize pid
# 查看jvm所有参数
java -XX:+PrintFlagsFinal -version
5. jps
可以列出正在运行的JVM进程,并显示JVM执行主类(Main Class,main()函数所在的类)名称以及这些进程的本地虚拟机唯一ID(LVMID,Local Virtual Machine Identifier)
jps工具主要选项
| 选项 | 作用 |
|---|---|
| -q | 只输出LVMID,省略主类的名称 |
| -m | 输出JVM进程启动时传递给主类main()函数的参数 |
| -l | 输出主类的全名,如果进程执行的是 JAR 包,则输出 JAR 路径 |
| -v | 输出虚拟机进程启动时的 JVM 参数 |
9. VM的退出
- 程序正常执行结束
- 程序在执行过程中遇到了异常或错误而异常终止
- 由于OS出现错误而导致JVM进程终止
- 某线程调用Runtime类或system类的exit方法,或Runtime类的halt方法,并且Java安全管理器也允许这次exit或halt操作
- 除此之外,JNI(Java Native Interface)规范描述了用JNI Invocation API来加载或卸载JVM时,Java虚拟机的退出情况
// 正常关闭
System.exit(0);
Runtime.getRuntime().exit(0);
1. Shutdown Hook
- Shutdown Hook关闭钩子
- 在正常关闭中,JVM 首先调用所有已注册的关闭钩子(Shutdown Hook)。关闭钩子是指通过
Runtime.addShutdownHook注册的但尚未开始的线程。JVM并不能保证关闭钩子的调用顺序。在关闭应用程序线程时,如果有(守护或非守护)线程仍然在运行,那么这些线程接下来将与关闭进程并发执行。当所有的关闭钩子都执行结束时,如果runFinalizersOnExit为true,那么JVM将运行终结器,然后再停止。JVM并不会停止或中断任何在关闭时仍然运行的应用程序线程。当JVM最终结束时,这些线程将被强行结束。如果关闭钩子或终结器没有执行完成,那么正常关闭进程“挂起”并且JVM必须被强行关闭。当被强行关闭时,只是关闭JVM,而不会运行关闭钩子
10. JVM指令
| invokevirtual | Invoke instance method; dispatch based on class | 执行一般实例方法,创建完实例Obj后,obj.method()调用的 |
|---|---|---|
| invokespecial | Invoke instance method; special handling for superclass, private, and instance initialization method invocations | 实例初始化方法(构造函数)、父类的方法(super.method()方式调用)、私有方法 |
| invokeinterface | Invoke interface method | 执行接口方法 |
| invokestatic | Invoke a class (static) method | 执行静态方法 |
| invokedynamic | Invoke dynamic method | jdk1.7新增,执行动态方法,不需要在编译时确定 |
11. 附录
1. 常用JVM指令
| 指令 | 助记符 | 指令描述 |
|---|---|---|
| 0xac | ireturn | 从当前方法返回int(当返回值是boolean/byte/char/short/int类型时使用) |
| 0xad | lreturn | 从当前方法返回long |
| 0xac | freturn | 从当前方法返回float |
| 0xaf | dreturn | 从当前方法返回double |
| 0xb0 | areturn | 从当前方法返回Obj引用 |
| 0xb1 | return | 从当前方法返回void(声明为void的方法、实例初始化方法、类和接口的初始化方法使用) |
| 0xbb | new | 创建一个Obj,并将其引用值压入栈顶 |
| 0xbc | newarray | 创建一个指定原始类型(如int/float/char)的数组,并将其引用值压入栈顶 |
| 0xbf | athrow | 将栈顶的异常抛出 |
| 0xc2 | monitorenter | 获取Obj的监视锁,用于同步方法或同步块 |
| 0xc3 | monitorexit | 释放Obj监视锁,用于同步方法或同步块 |
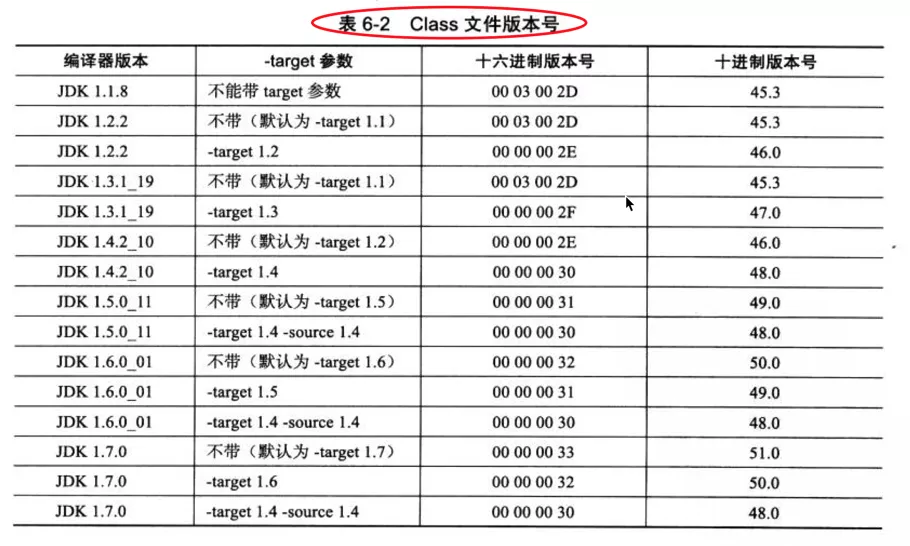
2. Class文件版本号
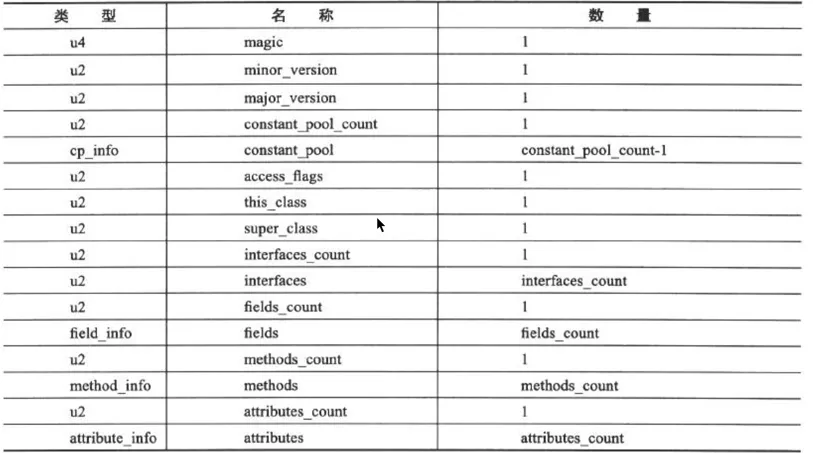
3. Class文件格式
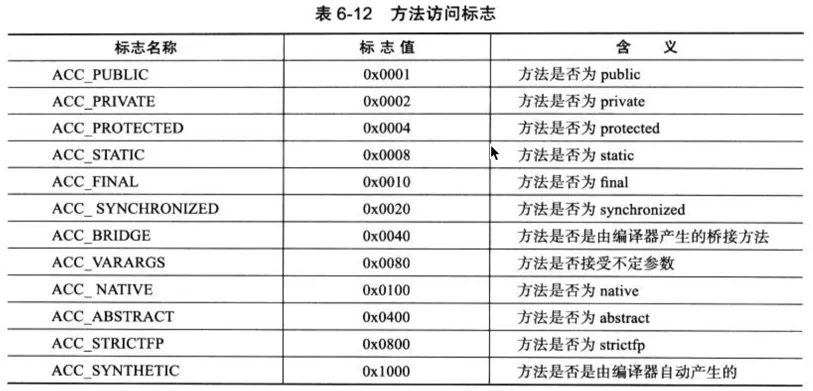
4. 方法访问标识
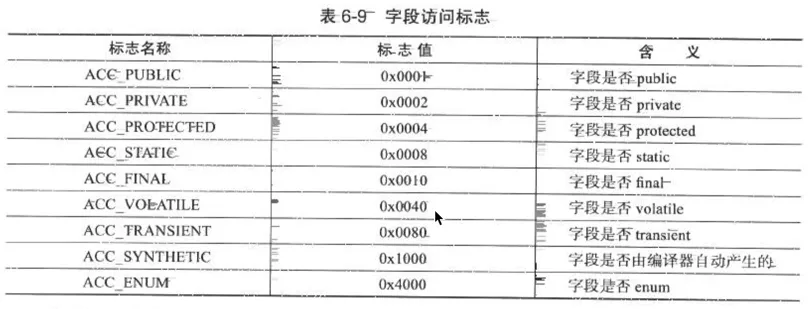
5. jvm常量池
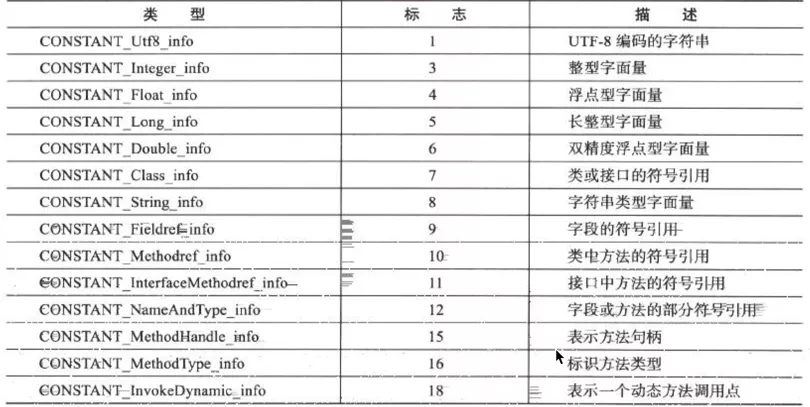
6. 类或接口的访问标识
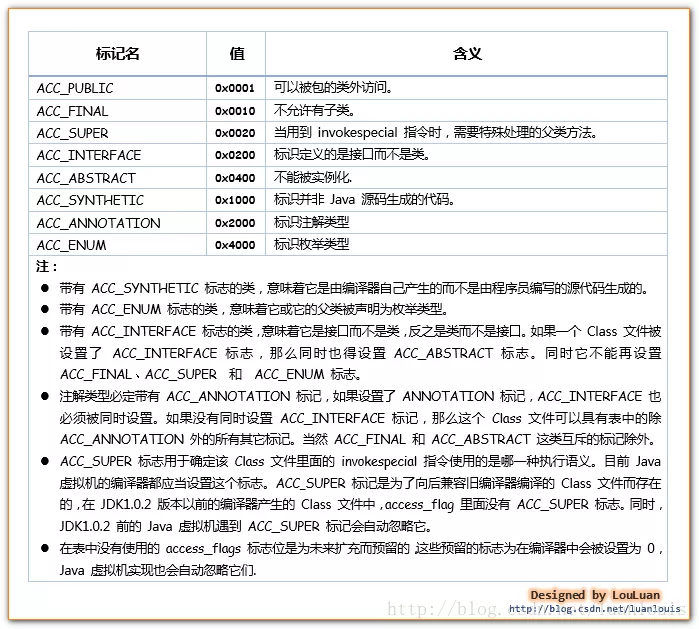
7. 描述符标识字符含义
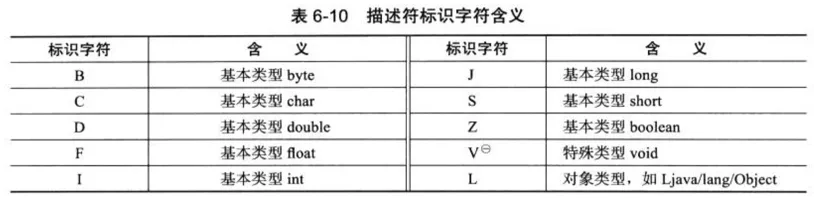

8. 字段访问标识
9. Java程序与Docker容器环境
对于Java来说,Docker毕竟是一个较新的环境,eg:其内存、CPU等资源限制是通过CGroup(Control Group)实现的,早期的JDK版本(8u131之前)并不能识别这些限制,进而会导致一些基础问题:
- 如果未配置合适的JVM堆和元数据区、直接内存等参数,Java就有可能试图使用超过容器限制的内存,最终被容器OOM kill,或者自身发生OOM
- 错误判断了可获取的CPU资源,eg:Docker限制了CPU的核数,JVM就可能设置不合适的GC并行线程数等
10. 基准测试
- 对于大多数Java开发者,更熟悉的则是范围相对较小、关注点更加细节的微基准测试(Micro-Benchmark)
- JMH是由Hotspot_JVM团队专家开发的,除了支持完整的基准测试过程,包括预热、运行、统计和报告等,还支持Java和其他JVM语言。更重要的是,它针对Hotspot_JVM提供了各种特性,以保证基准测试的正确性,整体准确性大大优于其他框架,并且,JMH还提供了用近乎白盒的方式进行Profiling等工作的能力