03-table
collation 英 [kəˈleɪʃn] 美 [kəˈleɪʃn] n. 校对,核对;整理;
1. Character_Set
字符集
- data存储编码方式,同样的内容不同字符集所占用的空间大小有较大差异
- 使用合适的字符集,减少数据量,减少IO操作次数,减少IO量
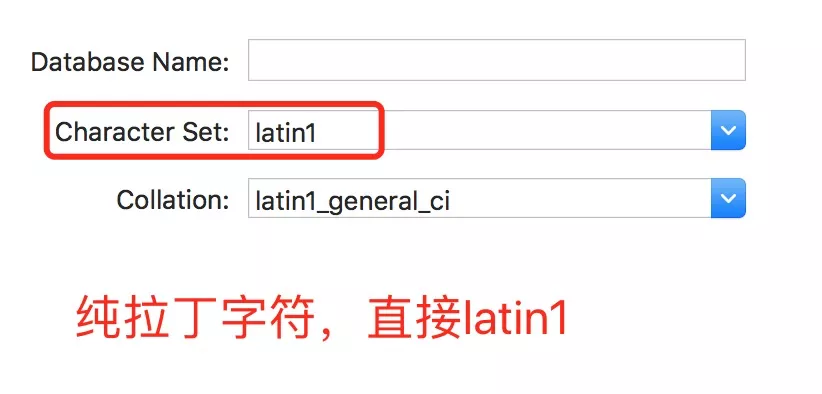
- 纯拉丁字符,选择《latin1》
- 不需要存放多种语言,就没必要utf8或者其他unicode字符类型

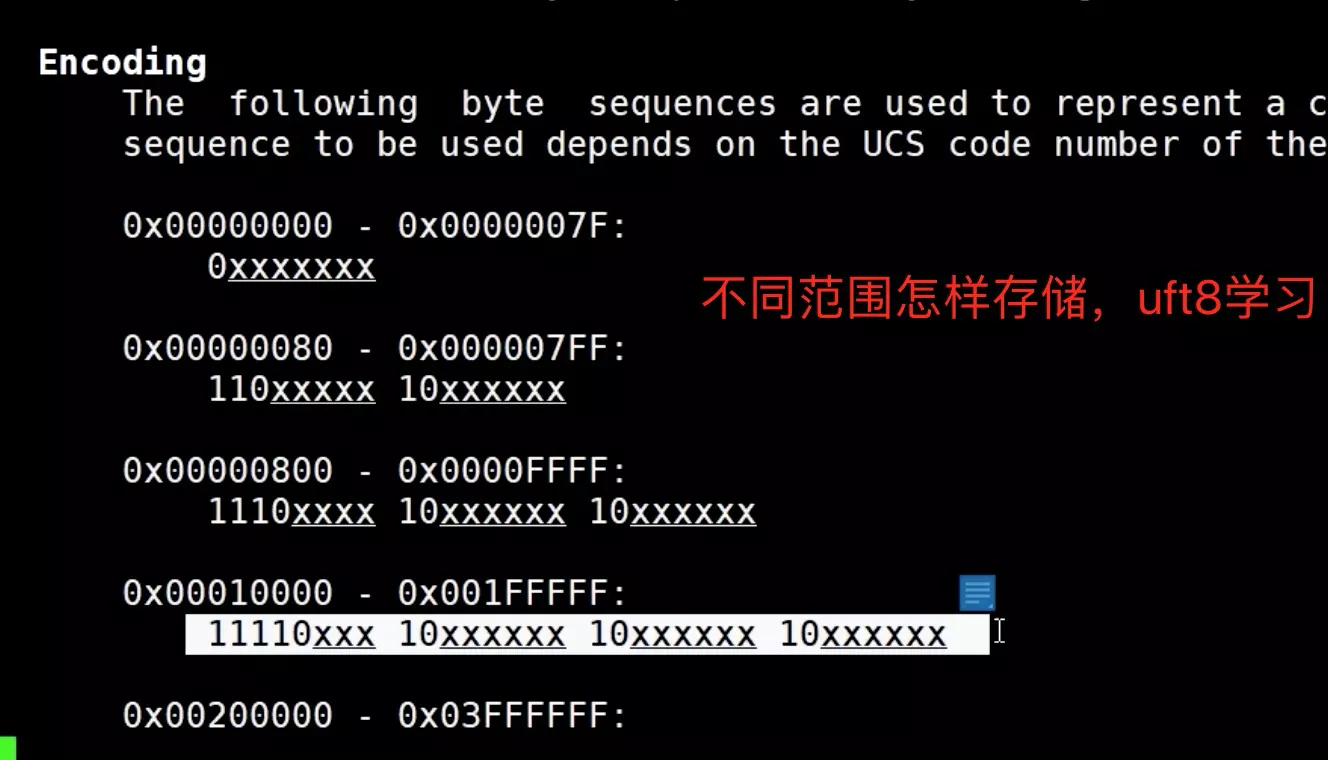
- utf8:支持最长三个字节的unicode字符
- utf8mb4:
most bytes 4(5.5.3 以上的版本)。支持最长4B的unicode字符,中文在db存,2B/3B
1. Collation
排序规则
- 直接用《utf8mb4_general_ci》
utf8mb4_unicode_ci更准确,utf8mb4_general_ci速度较快,其准确性已满足
2. Engine
- 存储引擎:数据文件的组织形式
- 聚簇索引:primary的tree的叶子节点即为data
- InnoDB默认情况下index加锁。crud的条件列为index列,行锁,否则表锁
- 全文索引:db文章表,有字段存文章内容。文章内容搜索java关键字,用solr、es,不用全文索引
| MyISAM | InnoDB | |
|---|---|---|
| 索引类型 | 非聚簇索引 | 聚簇索引 |
| 支持事务 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 否 | 是 |
| 支持处键 | 否 | 是 |
| 支持全文索引 | 是 | 是(5.6后支持) |
| 适合操作类型 | 大量select | 大量insert、delete、update |
# 默认搜索引擎
default-storage-engine=INNODB
3. 范式、反范式
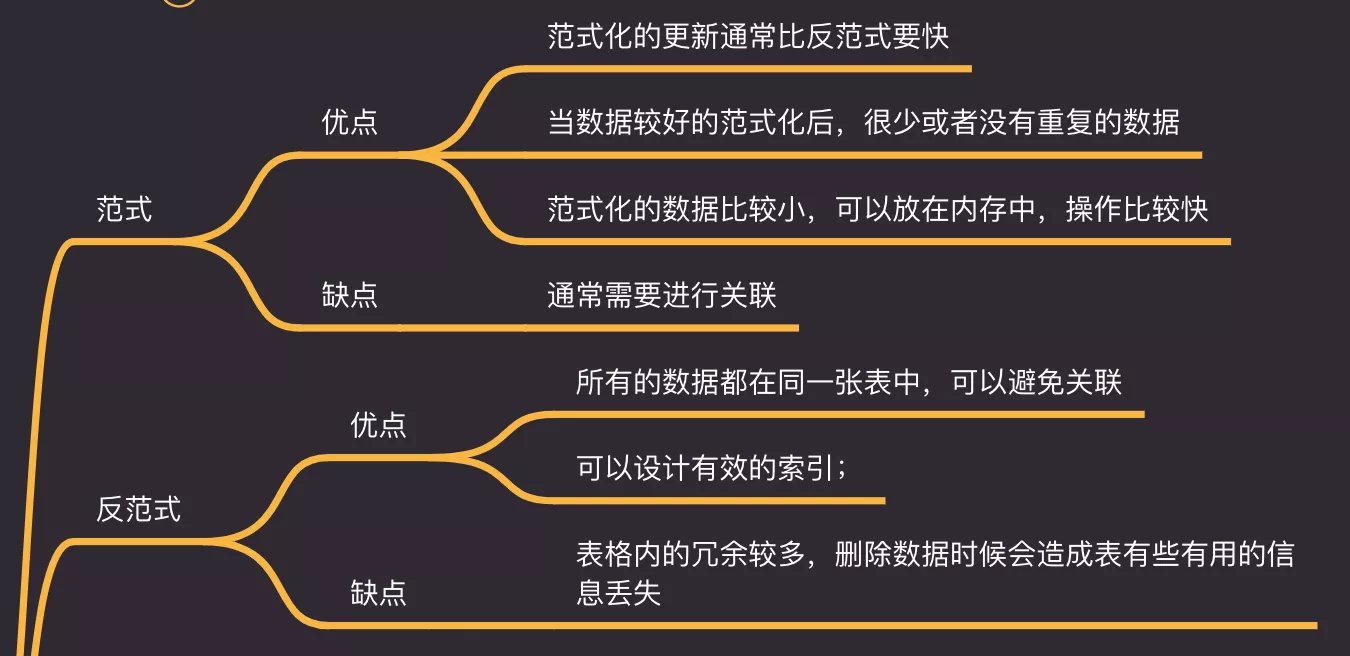
- 范式(NF:NormalForm):数据库设计总结的经验性规范
- 优点:
- 更新比反范式快
- 减少数据冗余
- 缺点:
- 通常需要关联
- 优点:
- 反范式
- 优点:
- 避免关联
- 有效设计索引
- 缺点:
- 数据冗余,删除可能删掉有用信息
- 优点:
- 三张table的join,阿里规范是不允许的。要看实际数据量
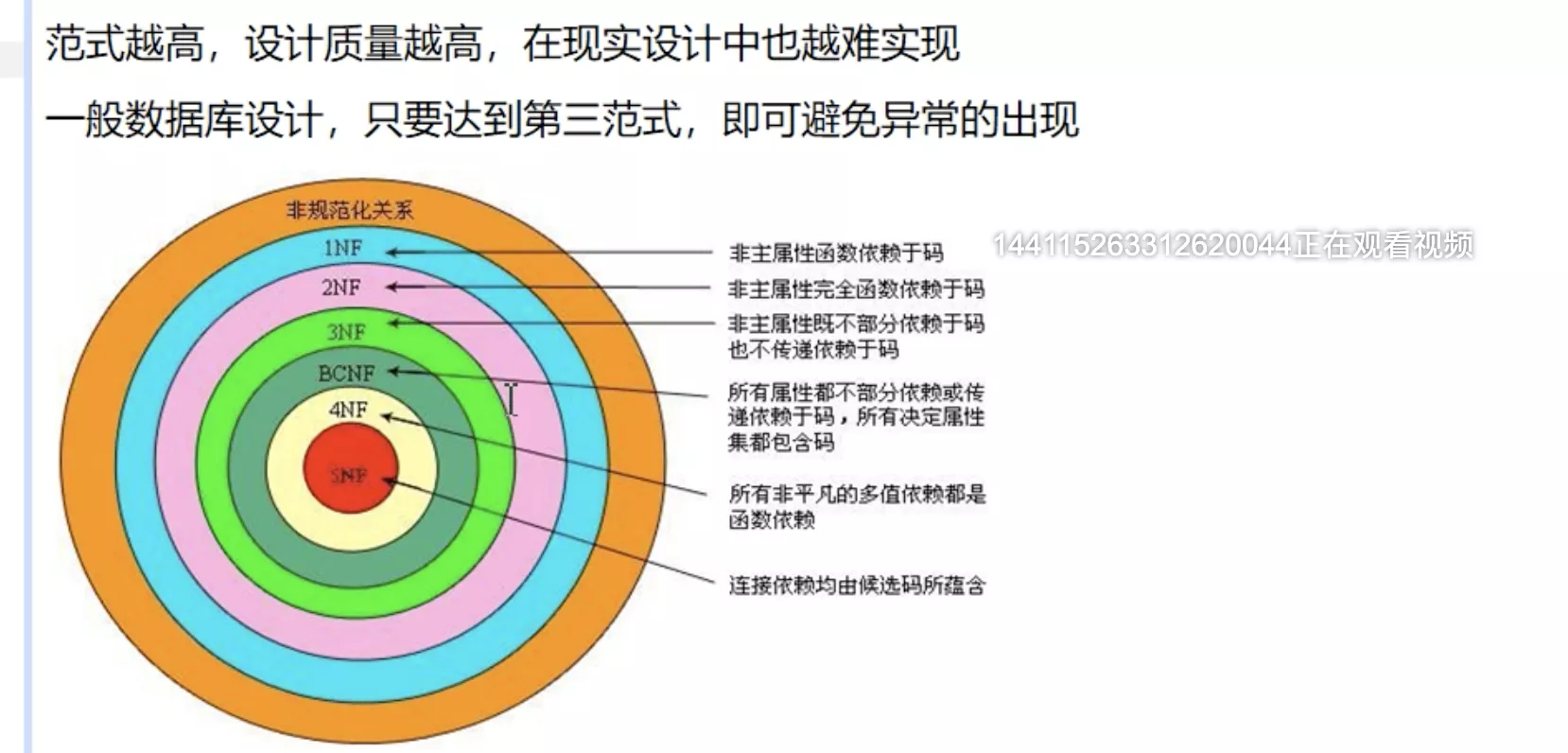
- 实际有5范式,4NF、5NF对数据库要求更高,完全没必要。所以三大范式即可
- 满足2NF,必须满足1NF;满足3NF,必须满足1NF、2NF
1. NF1_列原子性
- 列的原子性,取决于业务逻辑

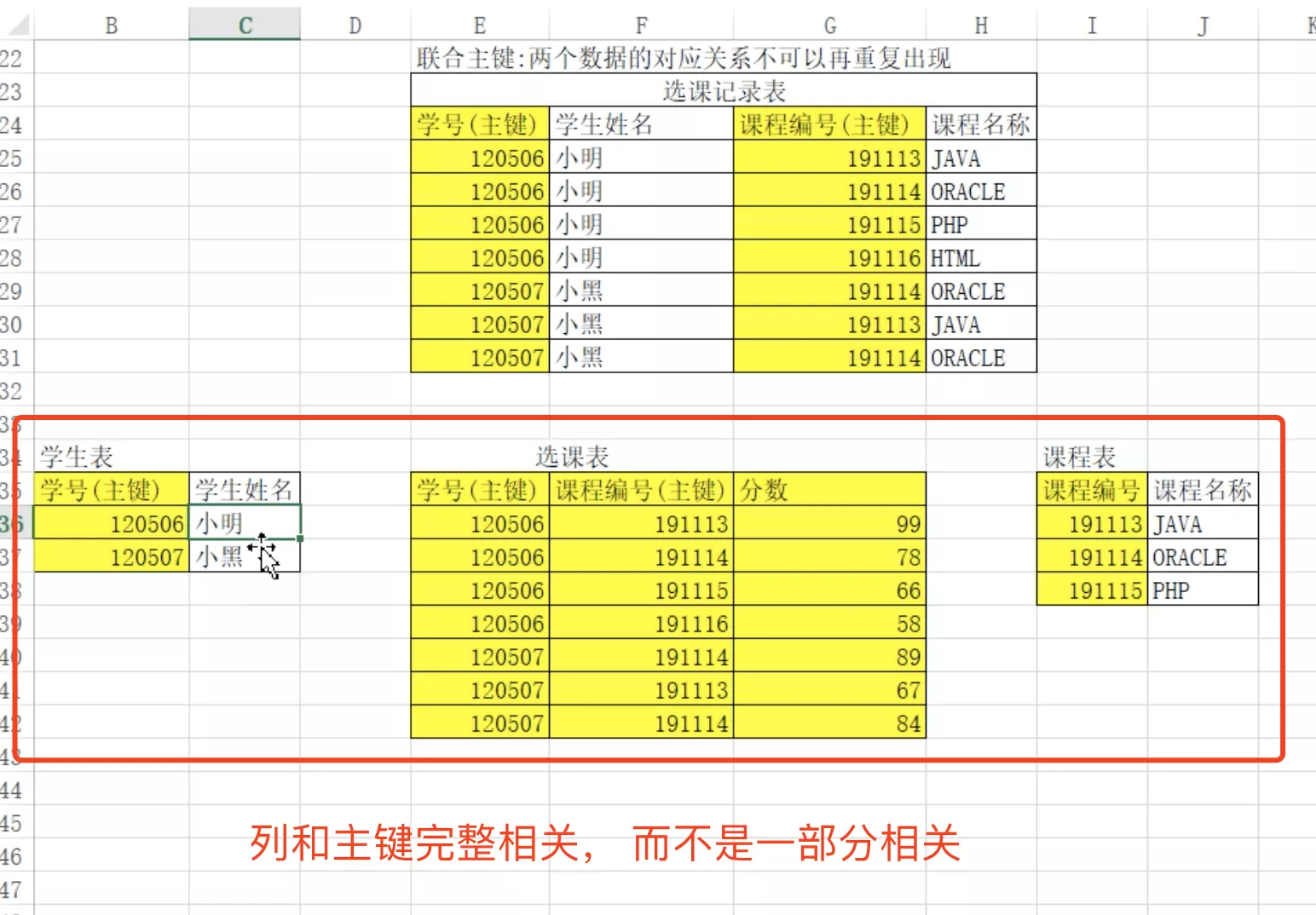
2. NF2_列和联合主键完整相关
- 多对多
- 列和联合主键完整相关,而不能只与主键的某一部分相关(主要针对联合主键而言)
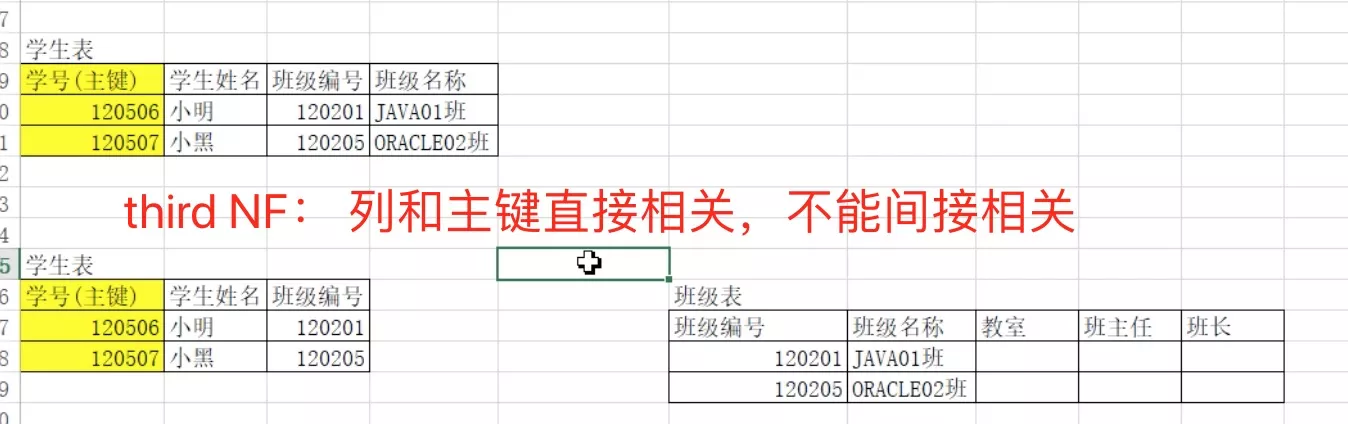
3. NF3_列和主键直接相关
- 一对多
- 列和主键直接相关,不能间接相关
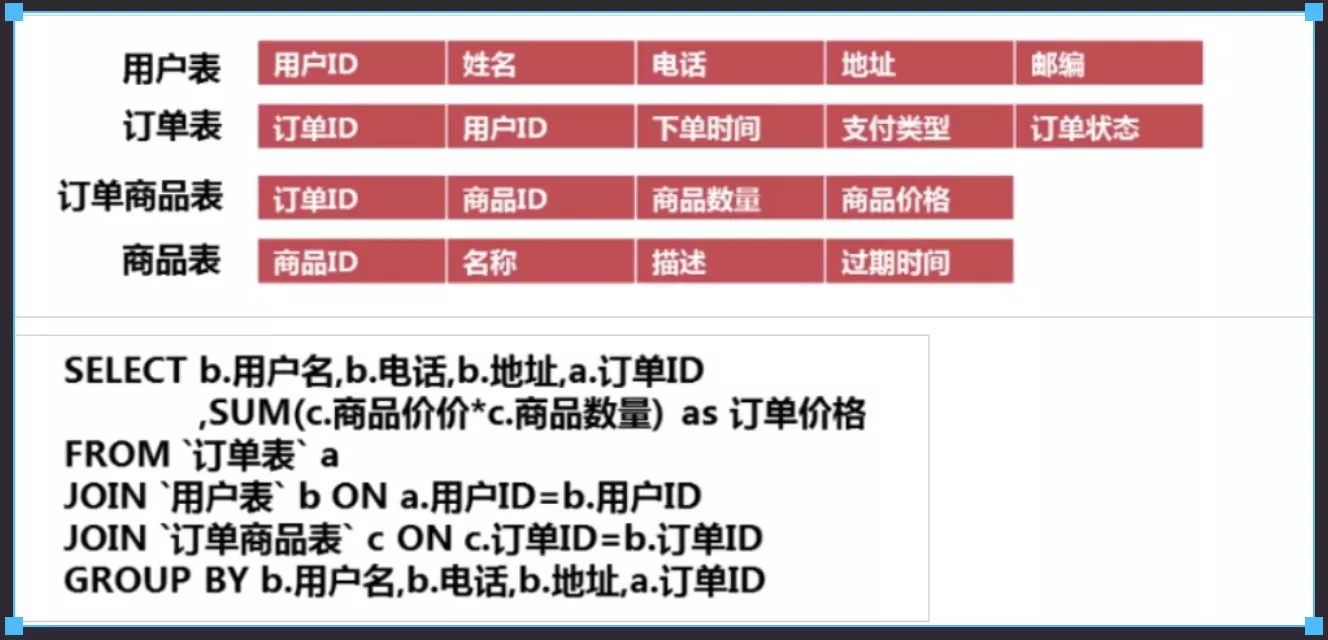
4. 反范式
- 空间换时间

4. 表关系
1. 一对一

2. 一对多
- 多表中含有一表中的主键
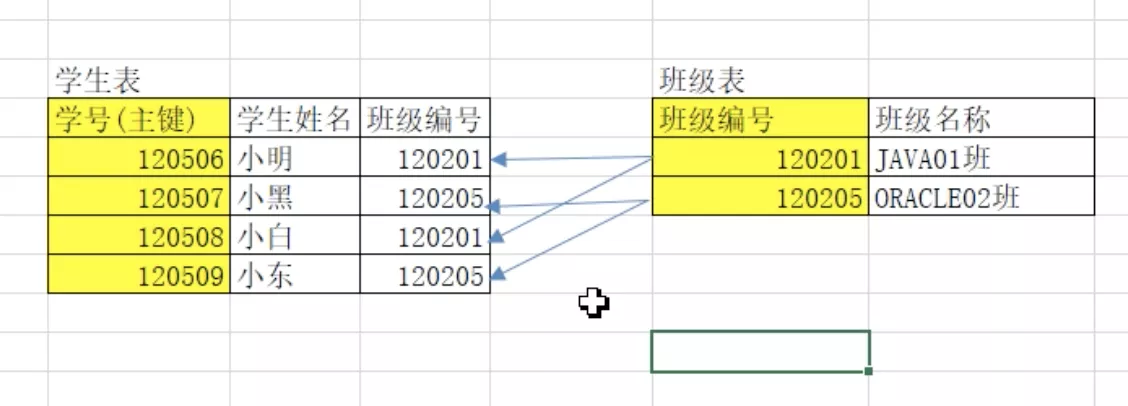
3. 多对多
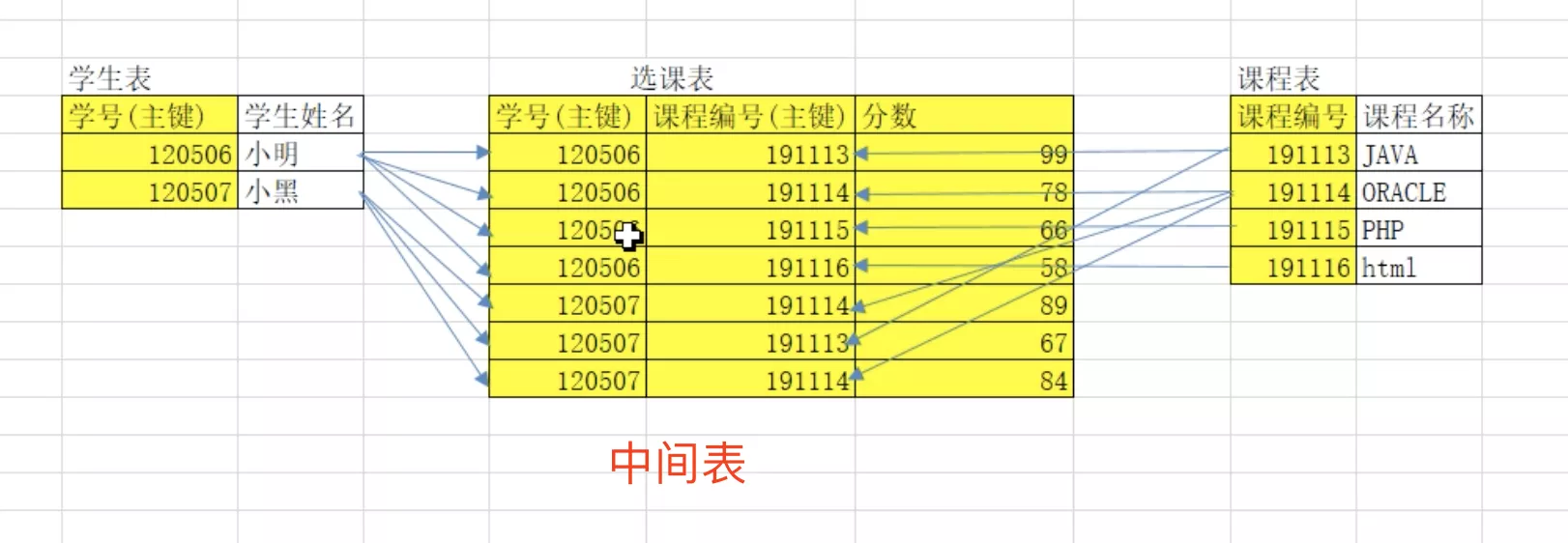
- 创建中间表。多表和中间表是一对多。《多对多》转换成2个《一对多》
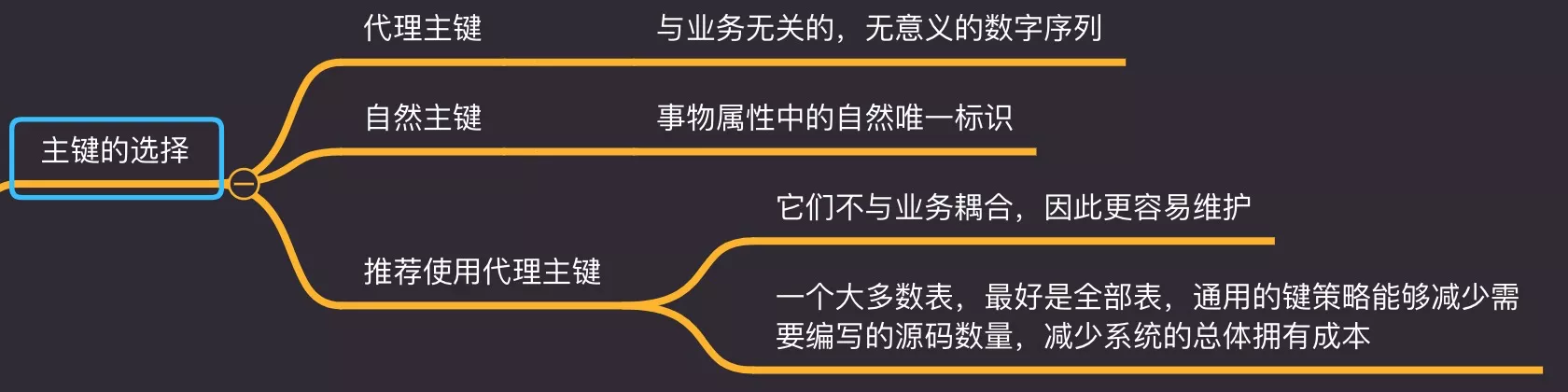
5. 主键
- 代理主键:与业务无关的,无意义的数字序列
- 自然主键:事物属性中的自然唯一标识
- 推荐使用代理主键
- 它们不与业务耦合,因此更容易维护
- 全部表,采用通用的主键策略能够减少需要编写的源码数量,减少系统的总体成本
6. 适当的数据冗余
- 频繁join2张(更多)大表的方式才能得到的独立小字段,join到的记录又大,会造成大量不必要的 IO,通过反范式优化
- 冗余的同时需要确保数据一致性,确保更新的同时冗余字段也被更新

7. 适当拆分
- 表中存在类似于
TEXT或很大的VARCHAR的大字段,如果大部分访问这张表时不需要这个字段。将其拆分到另外独立表中,以减少常用数据所占用的存储空间 - 每个数据块中可以存储的数据条数可以大大增加,既减少物理IO次数,大大提高内存中的缓存命中率

1. 分库分表(使用较多)
- 垂直拆分:不同的表不同的库(业务来拆)
- 水平拆分:一张表不同库
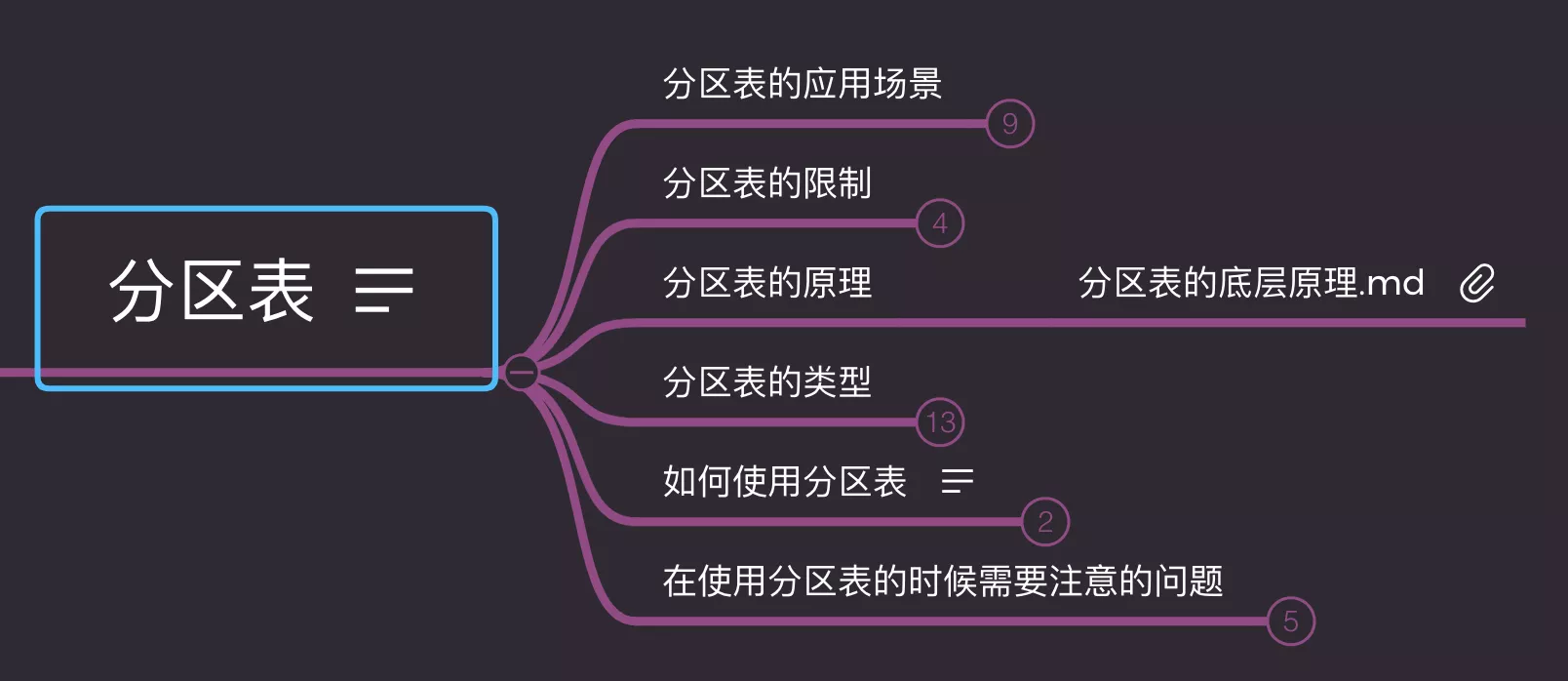
8. partition_table
- 分而治之(水平切分)
- 将表按照自定义规则,划分成n多个文件进行存储。每个文件是一类data
- idea没有界面化操作
CREATE TABLE `sales` (
`id` int(11) DEFAULT NULL,
`sales_date` date DEFAULT NULL,
`amount` decimal(10,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*!50100 PARTITION BY RANGE (YEAR(sales_date))
(PARTITION p1 VALUES LESS THAN (2020) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (2021) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (2022) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */;
INSERT INTO sales VALUES (4, '2020-11-14', 4.00);
INSERT INTO sales VALUES (3, '2021-11-14', 3.00);
INSERT INTO sales VALUES (1, '2023-11-14', 1.00);
INSERT INTO sales VALUES (2, '2022-11-14', 2.00);
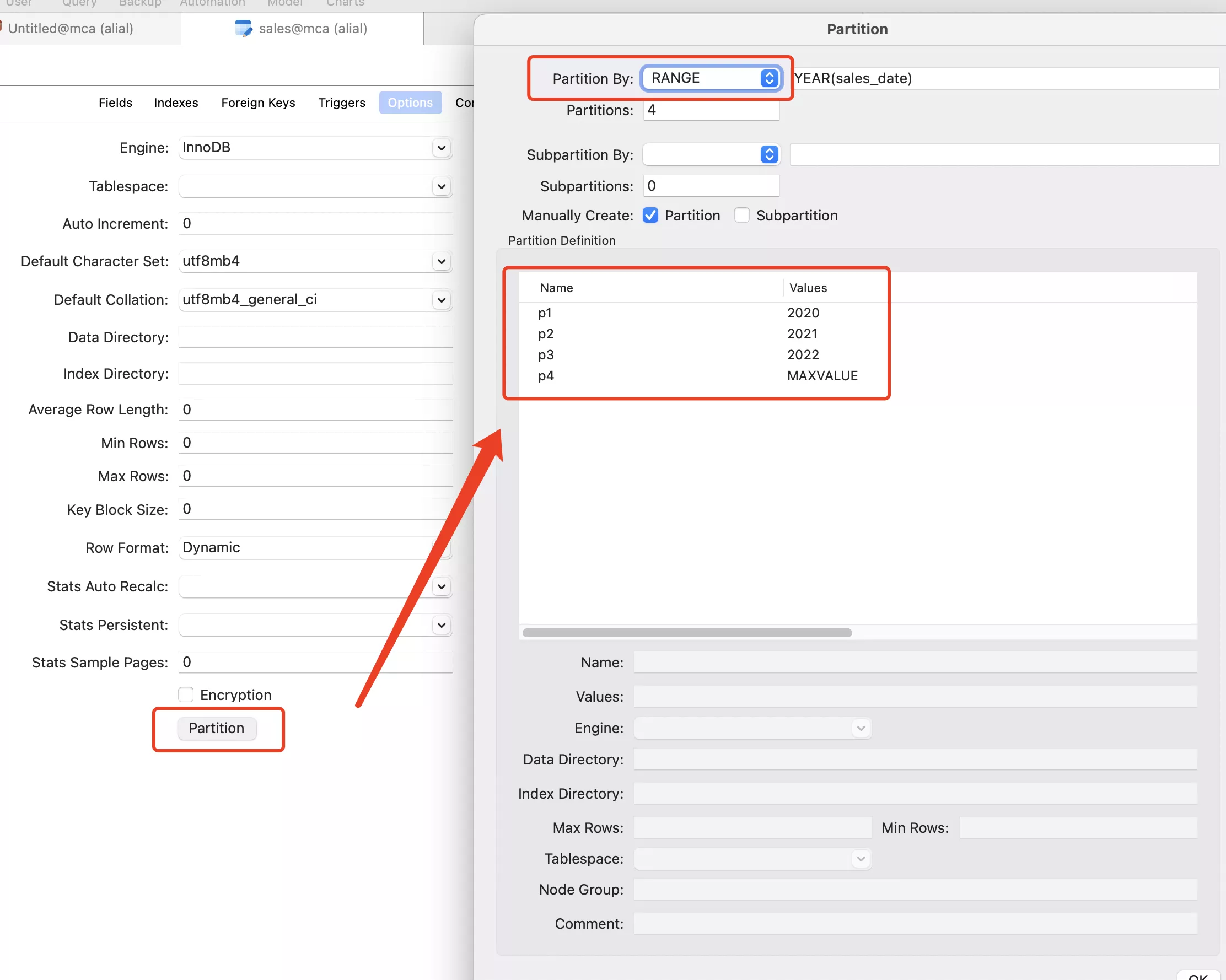
-rw-r-----. 1 polkitd input 8652 Oct 16 20:32 mysql_trx.frm
-rw-r-----. 1 polkitd input 131072 Oct 16 20:32 mysql_trx.ibd
-rw-r-----. 1 polkitd input 8632 Nov 14 14:41 sales.frm
-rw-r-----. 1 polkitd input 98304 Nov 14 14:41 sales#P#p1.ibd
-rw-r-----. 1 polkitd input 98304 Nov 14 15:07 sales#P#p2.ibd
-rw-r-----. 1 polkitd input 98304 Nov 14 14:46 sales#P#p3.ibd
-rw-r-----. 1 polkitd input 98304 Nov 14 14:46 sales#P#p4.ibd
1. 应用场景
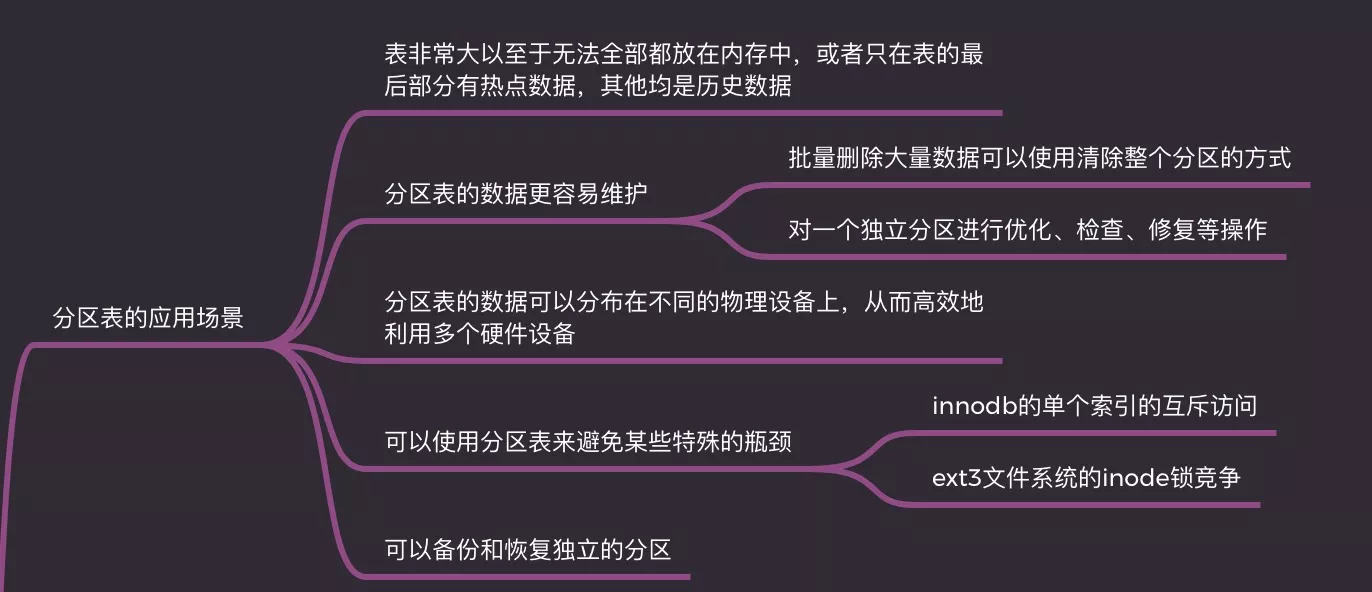
- 表非常大以至于无法全部放在内存中,或者表有部分热点数据,其他均为历史数据
- 更易维护
- 批量删除大量数据可以使用清除整个分区的方式
- 对一个独立分区进行优化、检查、修复等操作
- 数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备
- 可以使用分区表来避免某些特殊的瓶颈
- InnoDB的单个索引的互斥访问
- ext3文件系统的inode锁竞争
- 可以备份和恢复独立的分区
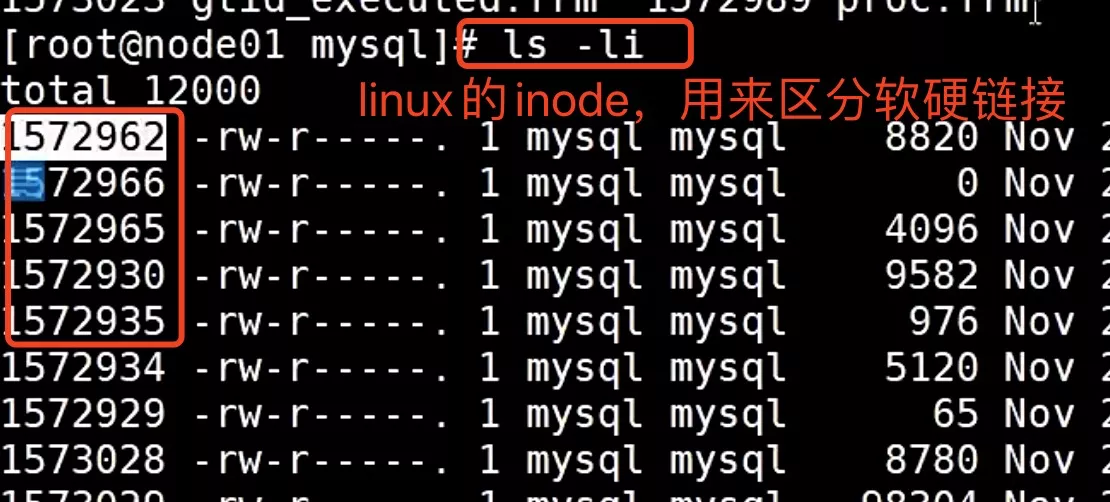
1. inode
- 文件物理存储(硬盘存储)的最小单位《扇区(Sector)》512B(相当于0.5KB)
- OS文件存取的最小单位《块(block)》:通常4KB,即连续8个Sector组成一个block
- inode_index(索引节点号)储存文件的元信息(创建者、创建日期、大小等等),指向文件物理地址
- Unix/Linux,文件名 => inode => 文件物理位置
ls -li命令,看到文件名对应的inode号码
1. hard_link
- 《硬链接》:A文件名、B文件名指向同一个inode
- A是B的硬链接(A和B 都是文件名),则A的目录项中的inode节点号与B的目录项中的inode节点号相同,即一个inode节点对应两个不同的文件名,两个文件名指向同一个文件,A和B 对文件系统来说是完全平等的。删除其中任何一个都不会影响另外一个的访问
- 作用:允许一个文件拥有多个有效路径名,防止“误删”。删除一个文件名,不影响另一个文件名的访问
- 文件真正删除是其所有硬连接文件均被删除
# source与target,同一个inode。inode中的"链接数",会增加1
ln source target
2. soft_link, symbolic_link
- 《软链接》《符号链接》:A是B的软链接(A和B 都是文件名),A的目录项中的inode节点号与B的目录项中的inode节点号不相同,A和B指向的是两个不同的inode,继而指向两块不同的数据块。但是A的数据块中存放的只是B的路径名(可以根据这个找到B的目录项)
- 如果删除了B,打开A就会报错:
No such file or directory
# source与target,不同inode。"链接数",不变
ln -s source target

2. 分库分表
- 水平切分:一表多库
- 垂直切分:一表一库
2. 限制

- 一个表最多只能有1024个分区。5.7版本可以支持8196个分区
- 早期Mysql,分区表达式必须是整数或者是返回整数的表达式。在Mysql5.5中,某些场景可以直接使用列来进行分区
- 如果分区字段中有primary或者unique_index,那么所有primary和unique_index都必须包含进来
- 分区表无法使用外键约束
3. 原理
- 分区表由多个相关的底层表实现,底层表由句柄对象(可以看作inode)标识,可以直接访问各个分区
- 存储引擎管理分区的各个底层表和管理普通表一样(底层表必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个完全相同的索引
- 有些操作支持过滤,只锁操作的底层表
- select
- 分区层先打开并锁住所有的底层表。优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据
- insert
- 分区层先打开并锁住所有的底层表。然后确定对应的分区,对相应底层表进行insert
- delete
- 分区层先打开并锁住所有的底层表。然后确定对应的分区,对相应底层表进行delete
- update
- 分区层先打开并锁住所有的底层表。select + update => insert => delete
4. 类型
- 数据被分成了几个带#的文件存储
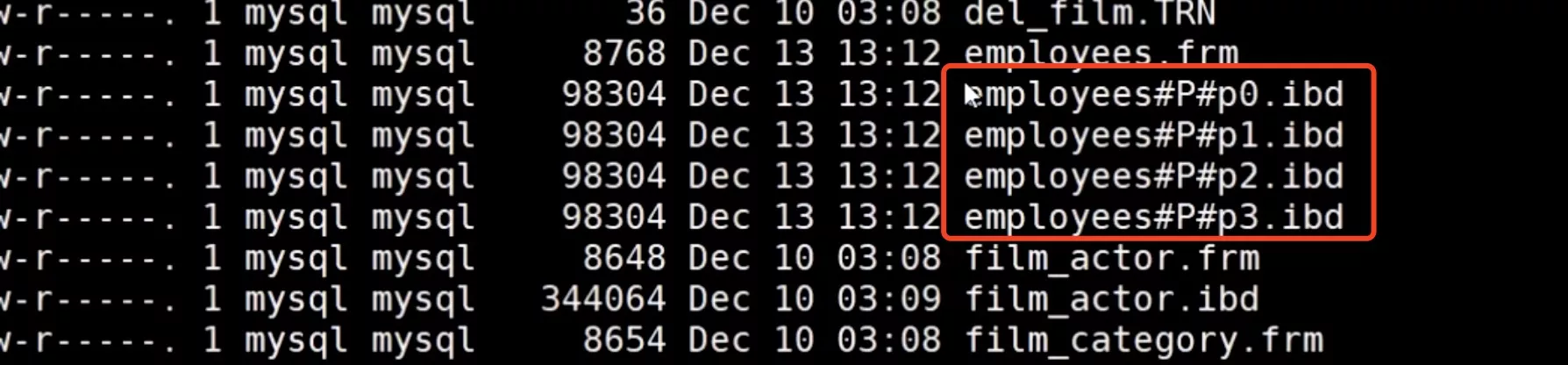

1. range_partition
- 范围分区:根据列值在给定范围内将行分配给分区
2. list_partition
- 列表分区:类似于range_partition,区别在于list分区是基于列值匹配一个离散值集合中的某个值来进行选择
3. columns_partition
- 列分区:Mysql从5.5开始支持,是range和list的升级版。只接受普通列不接受表达式
4. hash_partition
- hash分区:基于用户定义的表达式的返回值进行分区。这个表达式函数为Mysql中有效的、产生非负整数值的任何表达式
5. key_partition
- key分区:类似于hash分区,key分区支持一列或多列,且Mysql_server提供其自身的哈希函数,必须有一列或多列包含整数值
6. sub_partition
- 子分区:在分区的基础之上,再进行分区
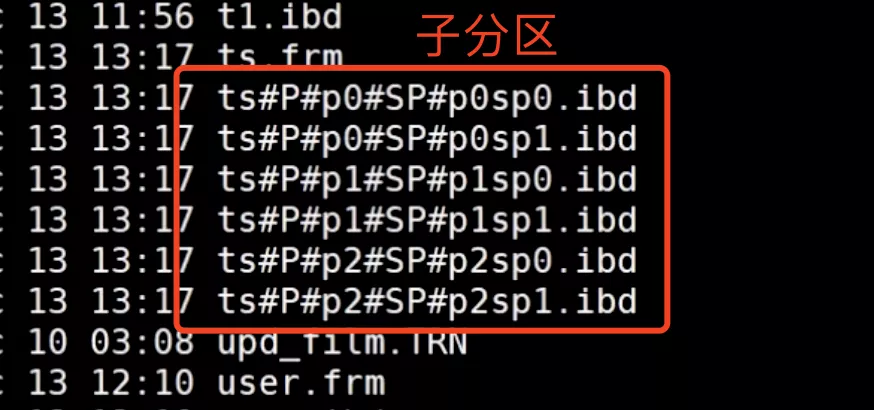
5. 使用

需要从非常大的、按照时间排序的表中查询出某一段时间的记录?
- 数据量巨大,扫描全表,不可取
- index在空间和维护上消耗巨大、产生大量的碎片、产生大量的随机IO,不可取
1. 全量扫描数据,不要任何索引
- 使用简单的分区方式存放表,不要任何索引。根据分区规则大致定位需要的数据位置,通过使用where条件将需要的数据限制在少数分区中,这种策略适用于以正常的方式访问大量数据
2. 索引数据,并分离热点
- 数据有明显的热点。将热点数据单独放在一个分区,缓存在内存中。这样查询就可以只访问一个很小的分区表,能够使用索引,也能够使用缓存
6. 注意问题
- null值会使分区过滤无效
- 分区列和索引列不匹配,会导致查询无法进行分区过滤
- 选择分区的成本可能很高
- 打开并锁住所有底层表的成本可能很高
- 维护分区的成本可能很高