01-Basic(50)
1. Java好在哪
- 面试官问你一些空、大的问题?其实就是考察是否有形成体系的理解
- 可以从跨平台、垃圾回收、生态三个方面来阐述。这种开放性问题没有固定答案,我的回答仅供参考。
1. 跨平台
首先 Java 是跨平台的,不同平台执行的机器码是不一样的,而 Java 因为加了一层中间层 JVM ,所以可以做到一次编写多平台运行,即 「Write once,Run anywhere」。
编译执行过程是先把 Java 源代码编译成字节码,字节码再由 JVM 解释或 JIT 编译执行,而因为 JIT 编译时需要预热的,所以还提供了 AOT(Ahead-of-Time Compilation),可以直接把字节码转成机器码,来让程序重启之后能迅速拉满战斗力。
2. 垃圾回收
Java 还提供垃圾自动回收功能,虽说手动管理内存意味着自由、精细化地掌控,但是很容易出错。
在内存较充裕的当下,将内存的管理交给 GC 来做,减轻了程序员编程的负担,提升了开发效率!
3. 生态
现在 Java 生态圈太全了,丰富的第三方类库、网上全面的资料、企业级框架、各种中间件等等。
2. 多态是什么意思
多态其实是一种抽象行为,主要作用是让程序员可以面对抽象编程而不是具体的实现类,代码扩展性会更强。
使用的对象是 person,但是 new 不同的实现类,表现的形式不同。
class Person {
void work() {
System.out.println("工作");
}
}
class Student extends Person {
@Override
void work() {
System.out.println("上学");
}
}
public class Test {
public static void main(String[] args) {
Person person = new Student();
person.work(); // 输出 "上学"
}
}
3. Java按值按引用传递
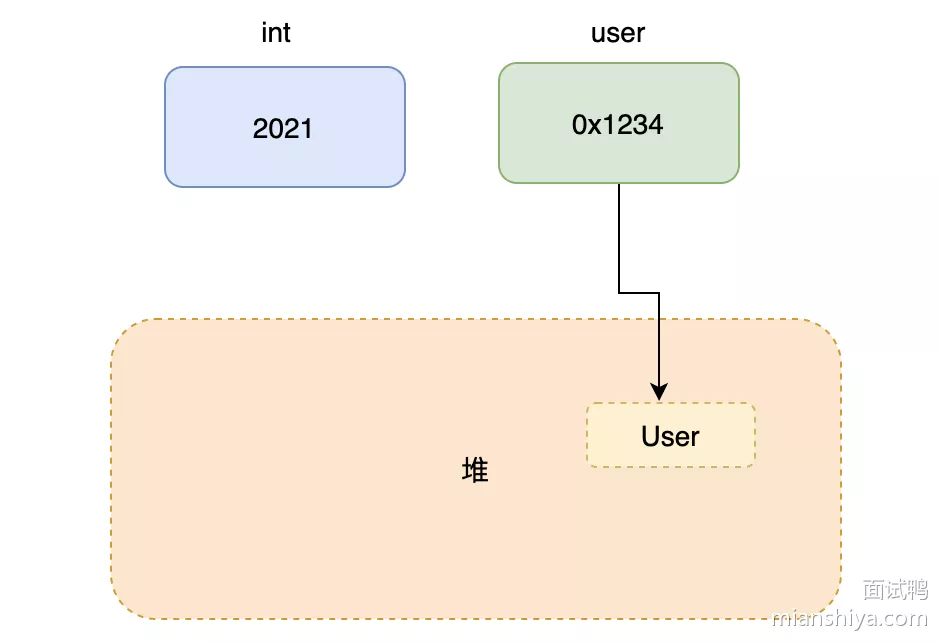
Java 只有按值传递,不论是基本类型还是引用类型。
JVM 内存有划分为栈和堆,局部变量和方法参数是在栈上分配的,引用类型占4个字节,基本类型看具体类型,eg:long和double占8个字节。
对象所占的空间是在堆中开辟的,引用类型变量存储对象在堆中地址来访问对象,引用类型传递时可以理解为把变量存储的地址给传递过去,因此引用类型也是值传递。
4. 接口、抽象类区别
- 接口:只能包含抽象方法(但在 Java8 之后可以设置 · 方法或者静态方法),成员变量只能是
public static final类型,当like-a的情况下用接口。- 接口是对行为的抽象,类似于条约。在 Java 中接口可以多实现,从
like-a角度来说接口先行,也就是先约定接口,再实现。
- 接口是对行为的抽象,类似于条约。在 Java 中接口可以多实现,从
- 抽象类: 可以包含成员变量和一般方法和抽象方法,当
is-a并且主要用于代码复用的场景下使用抽象类继承的方式,子类必须实现抽象类中的抽象方法。
在 Java 中只支持单继承。从 is-a 角度来看一般都是先写,然后发现代码能复用,然后抽象一个抽象类。
1. is-a、has-a、like-a
is-a:是一个,代表继承关系,如果 A is-a B,那么 B 就是 A 的父类。has-a:有一个,代表从属关系,如果A has a B,那么 B 就是 A 的组成部分。like-a:像一个,代表组合关系,如果 A like a B,那么 B 就是 A 的接口。
应用
- 如果确定两件对象之间是
is-a关系,应该使用继承;eg:菱形、圆形和方形都是形状的一种,应该从形状类继承 - 如果确定两件对象之间是
has-a关系,应该使用聚合;eg:电脑是由显示器、CPU、硬盘等组成的,那么聚合成电脑类 - 如果确定两件对象之间是
like-a关系,应该使用组合;eg:空调继承于制冷机,但它同时有加热功能,那么继承制冷机类,并实现加热接口
5. 不支持多继承
多继承会产生菱形继承(也叫钻石继承)问题,Java 之父就是吸取 C++ 的教训,因此在不支持多继承。
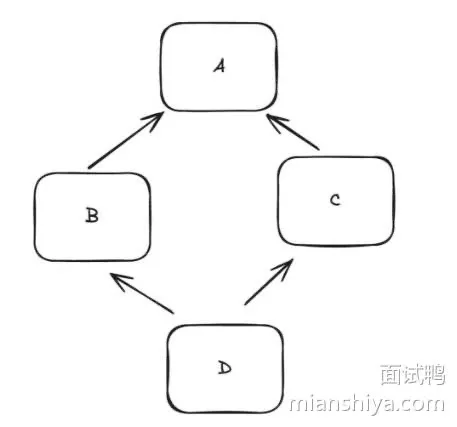
是不是看起来很像一个菱形,BC 继承了 A,然后 D 继承了 BC,假设此时要调用 D 内定义在 A 的方法,因为 B 和 C 都有不同的实现,此时就会出现歧义
6. 序列化、反序列化
- 序列化:其实就是将对象转化成可传输的字节序列格式,以便于存储和传输
- 反序列化:将字节序列格式转换为对象的过程
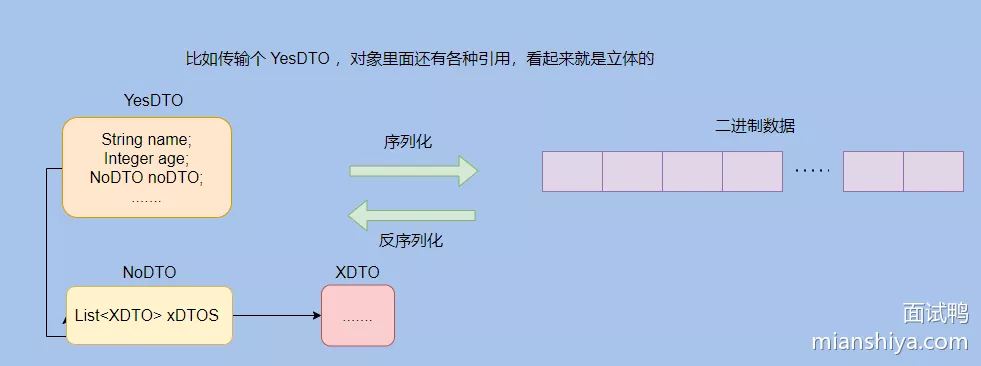
因为对象在 JVM 中可以认为是“立体”的,会有各种引用。eg:在内存地址Ox1234引用了某某对象,这个对象要传输到网络的另一端时候就需要把这些引用“压扁”。
因为网络的另一端的内存地址Ox1234可以没有某某对象,所以传输的对象需要包含这些信息,然后接收端将这些扁平的信息再反序列化得到对象。
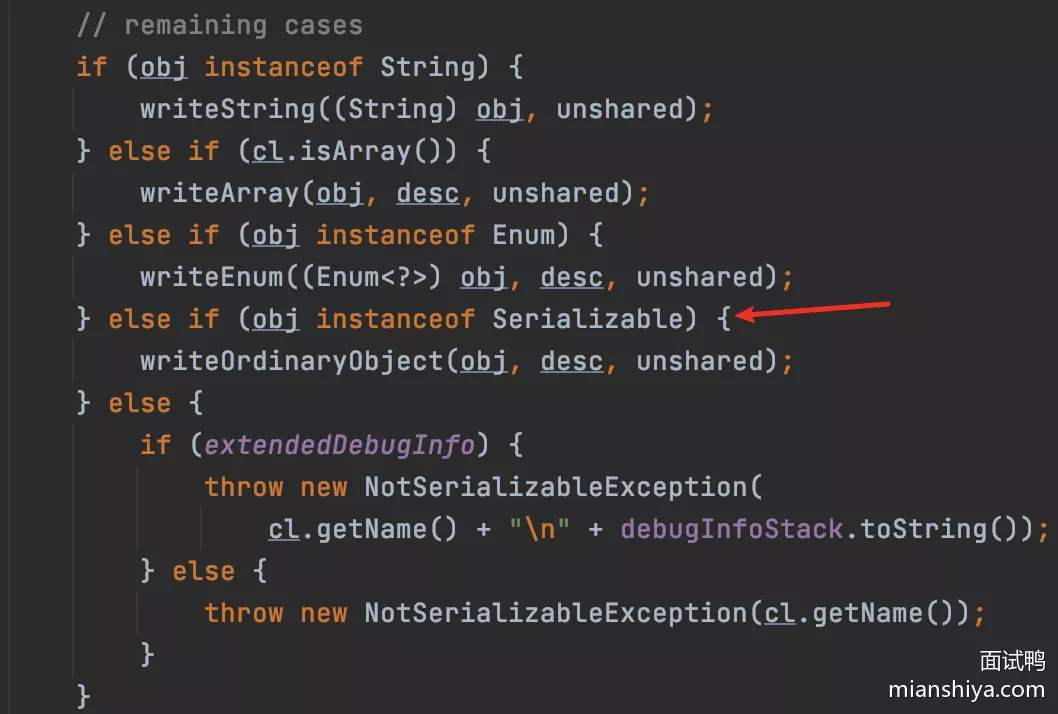
首先说一下 Serializable,这个接口没有什么实际的含义,就是起标记作用。
来看下源码就很清楚了,除了 String、数组、枚举外,如果实现了这个接口就走 writeOrdinaryObject ,否则就序列化就抛错。
1. serialVersionUID
serialVersionUID 又有什么用?
private static final long serialVersionUID = 1L;
- 用来验证序列化的对象和反序列化对应的对象的 ID 是否是一致的,验证作用
- 这个 ID 的数字其实不重要,无论是 1L 还是 idea 自动生成的,只要序列化、反序列化对象的
serialVersionUID一致的话就行 - 没有显式指定
serialVersionUID,则编译器会根据类的相关信息自动生成一个,可以认为是一个指纹
2. 不包含静态变量
Java 序列化不包含静态变量
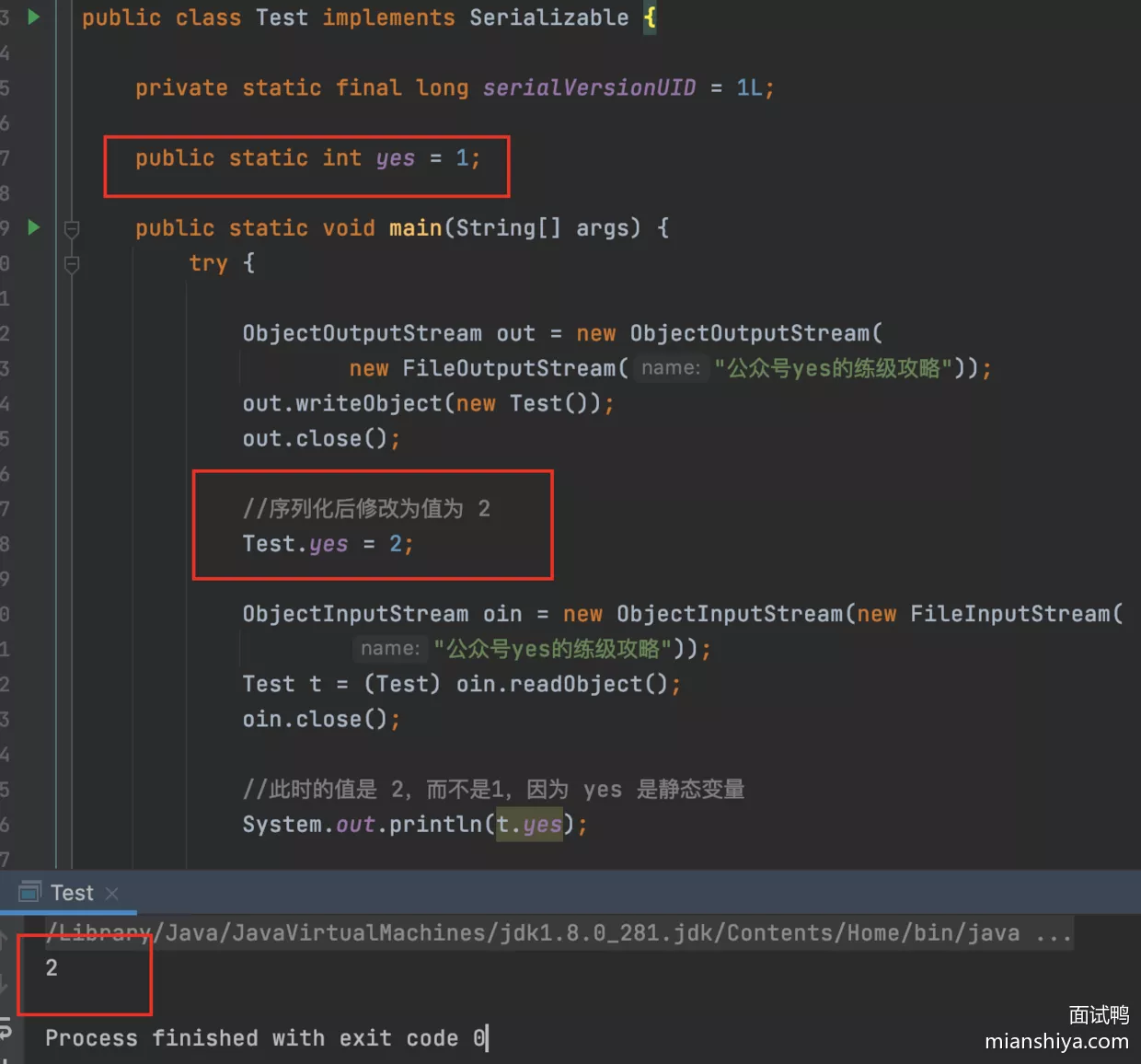
7. 什么是不可变类
- 不可变类指的是无法修改对象的值,eg:String 就是典型的不可变类,创建一个 String 对象之后,这个对象就无法被修改。
- 因为无法被修改,所以像执行
s += "a";其实返回的是一个新建的 String 对象,老的 s 指向的对象不会发生变化,只是 s 的引用指向了新的对象而已。
好处就是安全,在多线程环境下也是线程安全的
如何实现一个不可变类?
String 类用 final 修饰,表示无法被继承。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
- String 本质是一个 char 数组,然后用 final 修饰,不过 final 限制不了数组内部的数据,所以这还不够
- 所以 value 是用 private 修饰的,并且没有暴露出 set 方法,这样外部其实就接触不到 value 所以无法修改
- 当然还是有修改的需求,eg:
replace(),返回一个新对象来作为结果
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
总结:私有化变量,不要暴露setter(),即使有修改需求也是返回一个新对象
8. Exception、Error区别
Exception:程序正常运行过程中可以预料到的意外情况,应该被开发者捕获并且进行相应的处理Error:正常情况下,不太可能出现的情况,绝大部分的Error都会导致程序处于不正常、不可恢复的状态,也就是挂了
都继承了Throwable类,Java中只有继承了Throwable类的实例才可以被throw或被catch
- 尽量不要捕获类似Exception这样通用异常,而应该捕获特定异常
- 不要 “吞” 了异常
- 捕获了异常,不抛出,也没写日志。会莫名其妙的没有任何的信息
catch之后e.printStackTrace(),通常不推荐用这种方法,一般情况下,没有问题,这方法输出的是个标准错误流。最好是输入到日志里,自定义一定的格式,将详细的信息输入到日志系统中,适合清晰高效的排查错误
- 不要延迟处理异常。方法嵌套调用了几层才异常
try-catch的范围能小则小。影响JVM对代码的优化,eg:重排序- 尽量不要通过异常来控制程序流程
- 低效的,有 CPU 分支预测的优化等
- 每实例化一个
Exception都会对栈进行快照,相对而言是一个比较重的操作,数量过多,开销就不能被忽略了
- 不要在
finally中处理返回值或直接return- 会让发生很诡异的事情,eg:覆盖
try中的return
- 会让发生很诡异的事情,eg:覆盖
9. 面向对象、过程编程区别
- 面向对象编程(Object Oriented Programming,OOP):一种编程范式或编程风格。把类或对象作为基本单元来组织代码。封装、继承、多态作为代码设计指导
- 面向过程编程:以过程作为基本单元来组织代码,过程其实就是动作,就是函数,面向过程中函数和数据是分离的,数据就是成员变量
- 面向过程是很直接的思维,一步步的执行,一条道走到底
- 面向对象是先抽象,把事物分类得到不同的类,划分每个类的职责。暴露出每个类所能执行的动作,然后按逻辑执行时调用每个类的方法,不关心内部的逻辑
eg:咖啡机煮咖啡,面向过程:
- 执行加咖啡豆方法
- 执行加水方法
- 执行煮咖啡方法
- 执行喝咖啡方法
抽象出:人、咖啡机(分类),开始执行:
- 人.加咖啡豆
- 人.加水
- 咖啡机.煮
- 人.喝咖啡
- 面向对象编程执行的步骤没有变少,整体执行流程还是一样的,都是先加咖啡豆、加水、煮咖啡、喝,这个逻辑没有变
- 无非就是划分了类,把每一步骤具体的实现封装了起来,散布在不同的类中
- 对于程序员来说最直接的感受:变的其实就是代码的分布,煮咖啡的代码实现被封装在咖啡机内部,喝咖啡的代码实现被封装在人内部,而不是在一个方法中写出来
- 计算机思维到人类思维的变化
- 面向对象思想就类似人类面对复杂场景时的分析思维:归类、汇总
10. 重载与重写的区别
- 重载:在同一个类中定义多个方法,它们具有相同的名字但参数列表不同。主要用于提供相同功能的不同实现
- 构造函数的重载、不同类型输入的处理等
- 重写:在子类中定义一个与父类方法具有相同签名的方法(不包括返回值),以便提供子类的特定实现。主要用于实现运行时多态性
- 方法返回类型与父类一致,或者是其子类(协变返回类型)
- 子类方法定义的访问修饰符,不能比父类更严格。eg:父类是
protected,子类不能是private,可以是public - 子类方法抛出的异常必须与父类一致,或是其父类异常的子类
11. 内部类作用
- 定义在一个类的内部的类。作用:为了封装和逻辑分组,提供更清晰的代码组织结构
- 通过内部类,可以把逻辑上相关的类组织在一起,提升封装性和代码的可读性。后期维护时都在一个类里面,不需要在各地方找来找去
1. 成员内部类
- 定义在另一个类中的类,可以使用外部类的所有成员变量、方法,包括
private
public class OuterClass {
private String outerField = "Outer Field";
class InnerClass {
void display() {
System.out.println("Outer Field: " + outerField);
}
}
public void createInner() {
InnerClass inner = new InnerClass();
inner.display();
}
}
2. 静态内部类
- 只能访问外部类的静态成员变量、方法,其实它就等于一个顶级类,可以独立于外部类使用,所以更多的只是表明类结构和命名空间
public class OuterClass {
private static String staticOuterField = "Static Outer Field";
static class StaticInnerClass {
void display() {
System.out.println("Static Outer Field: " + staticOuterField);
}
}
public static void createStaticInner() {
StaticInnerClass staticInner = new StaticInnerClass();
staticInner.display();
}
}
3. 局部内部类
- 指在方法中定义的类,只在该方法内可见,可以访问外部类的成员及方法中的局部变量(需要声明为
final或effectively final)
public class OuterClass {
void outerMethod() {
final String localVar = "Local Variable";
class LocalInnerClass {
void display() {
System.out.println("Local Variable: " + localVar);
}
}
LocalInnerClass localInner = new LocalInnerClass();
localInner.display();
}
}
4. 匿名类
- 没有类名的内部类。用于简化实现接口和继承类的代码,仅在创建对象时使用。eg:回调逻辑定义场景
public class OuterClass {
interface Greeting {
void greet();
}
public void sayHello() {
Greeting greeting = new Greeting() {
@Override
public void greet() {
System.out.println("Hello, World!");
}
};
greeting.greet();
}
}
- 局部内部类用的比较少,常用成员内部类、静态内部类和匿名内部类
- 实际上内部类是一个编译层面的概念,像一个语法糖一样,经过编译器之后其实内部类会提升为外部顶级类,和外部类没有任何区别
- JVM中没有内部类的概念
12. JDK8新特性
- 用元空间替代了永久代
- 引入了
Lambda表达式 - 引入了日期类、接口默认方法、静态方法
- 新增
Stream流式接口 - 引入
Optional类 - 新增了
CompletableFuture、StampedLock等并发实现类 - 修改了
HashMap、ConcurrentHashMap实现(等着八股文之问)
1. 元空间替代永久代
- JDK8 把
JRockit和Hotspot融合,而JRockit没有永久代,所以把Hotspot永久代给去了(本质也是永久代回收效率太低)
2. lambda
- Lambda 是 Java8 引入的一种匿名函数,其本质是作为函数式接口的实例
// 传统方式
Runnable runnable1 = new Runnable() {
@Override
public void run() {
System.out.println("mianshiya.com");
}
};
// Lambda 表达式
Runnable runnable2 = () -> System.out.println("mianshiya.com");
3. 日期类
- Java8引入了新的日期和时间API(位于
java.time包中),它们更加简洁和易于使用,解决了旧版日期时间 API 的许多问题 Date、Calendar都是可变类且线程不安全。而新的是不可变的,一旦创建就不能修改,可以避免意外的修改,提升代码的安全性、可维护性
LocalDate date = LocalDate.now();
LocalTime time = LocalTime.now();
LocalDateTime dateTime = LocalDateTime.now();
Date本身不包含时区信息,必须使用Calendar类来处理时区,但使用起来非常复杂且容易出错- 新API提供了专门的时区类(
ZonedDateTime、OffsetDateTime、ZoneId等),简化了时区处理,并且这些类的方法更加直观易用
4. 接口默认方法、静态
- 默认方法允许在接口中定义方法的默认实现,实现类不需要再实现这些方法
- 提供静态方法,是为了将相关的方法内聚在接口中,不必创建新的对象
interface MyInterface {
default void defaultMethod() {
System.out.println("Default Method");
}
static void hello() {
System.out.println("Hello, New Static Method Here");
}
}
5. Stream流式接口
- Stream_API提供了一种高效且易于使用的方式来处理数据集合。它支持链式操作、惰性求值和并行处理
List<String> list = Arrays.asList("a", "b", "c", "d");
List<String> result = list.stream()
.filter(s -> s.startsWith("a"))
.collect(Collectors.toList());
6. Optional
Optional类用来解决可能出现的NullPointerException问题,提供了一种优雅的方式来处理可能为空的值
Optional<String> optional = Optional.of("mianshiya.com");
optional.ifPresent(System.out::println);
7. CompletableFuture
CompletableFuture提供了一个新的异步编程模型,简化了异步任务的编写和管理
CompletableFuture.supplyAsync(() -> "Hello")
.thenApply(s -> s + " World")
.thenAccept(System.out::println);
13. String, SBuffer, SBuilder
String是Java中基础且重要的类,并且String也是Immutable类的典型实现,被声明为final class,除了hash这个属性其它属性都声明为final- 不可变性,拼接字符串时会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响
StringBuffer和StringBuilder二者都继承了AbstractStringBuilder,底层都是利用可修改的char数组(JDK9以后是byte数组)
StringBuffer:本质是一个线程安全的可修改的字符序列,所有方法都加上了synchronized。保证了线程安全,牺牲部分性能StringBuilder:JDK1.5发布的,它和StringBuffer本质上没什么区别,去掉了synchronized,线程不安全,减少性能开销
大量的字符串拼接,能预知大小的话StringBuffer或StringBuilder初始化capacity,避免多次扩容的开销(扩容要抛弃原有数组,还要进行数组拷贝创建新的数组)
1. 选择建议
String:适用于少量字符串操作或需要字符串常量池优化的场景StringBuffer:适用于多线程环境下频繁的字符串操作StringBuilder:适用于单线程环境下频繁的字符串操。
14. StringBuilder内部实现
StringBuilder都用了哪些方法- append
- insert
- delete
- replace
- charAt
- ...
StringBuilder主要用于动态拼接字符串,大致需要实现 append、insert...等功能- 然后底层使用
char[]来存储字符(默认16),用count来记录存放的字符数 - 数组是连续内存结构,为了防止频繁地复制和申请内存,提供
capacity初始化数组的大小,在预先知晓大字符串的情况下,可以减少数组的扩容次数,有效的提升效率!- 一定要点破:数组是连续内存的结构,并且要体现出自己有节省内存和提高效率的意识
面试官插入问:String底层不也是用的char[]存放吗?两者有啥区别?
String被final修饰,且内部的char也被private final修饰了,所以是不可变的,是典型的Immutable类,因此其不可变性,保证了线程安全,能实现字符串常量池等
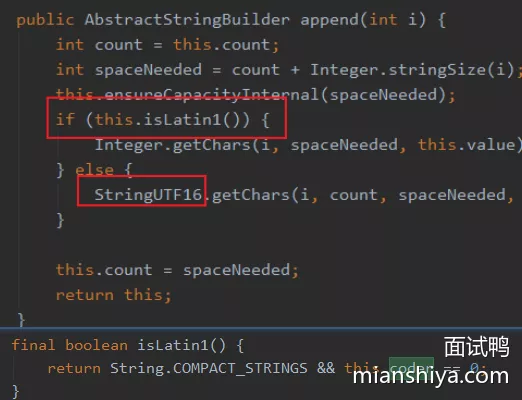
1. append

append()的int值转成char需要占数组的几位,计算一下现在的数组够不够放,如果不够就扩容一下,然后再把int转成char放进去,再更新现有的字符数int计算所占的字符位数?即上面代码的Integer.stringSize()
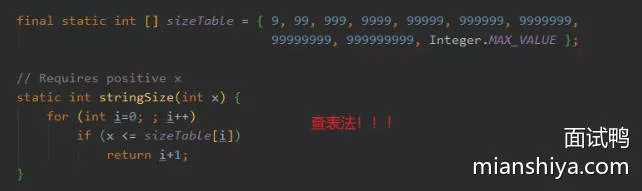
- 查表法!直接列了各个位数的边界值依次存放在数组中,然后判断大小再根据数组下标算出位数。简单、方便、高效
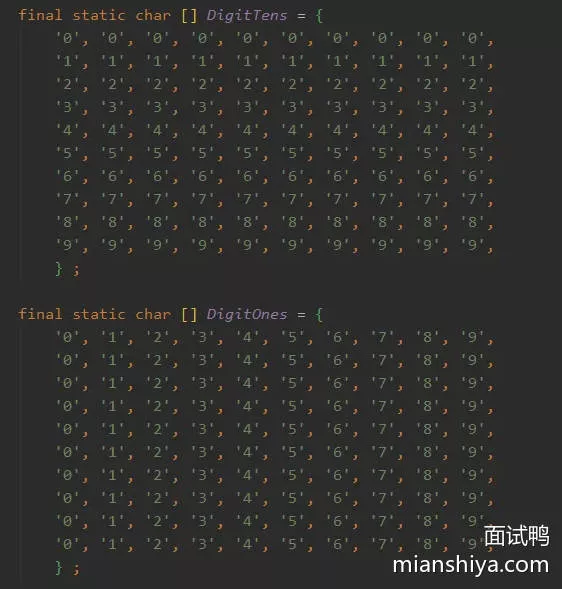
int是如何转换成char然后插入到数组中的,即Integer.getChars()

DigitOnes、DigitTens这两个数组,还是熟悉的查表法!
- 其实常用的
String.valueOf(int i),内部也是通过Integer.stringSize和Integer.getChars来完成
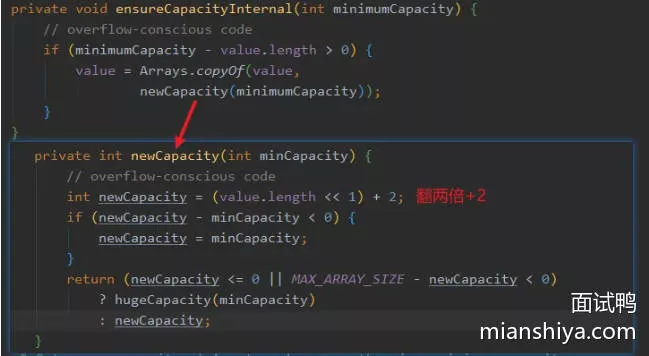
2. 怎么扩容
ensureCapacityInternal()方法实现。直接Arrays.copyOf,进行一波扩容加拷贝,扩容之后的数组容量为之前的两倍+2
3. insert

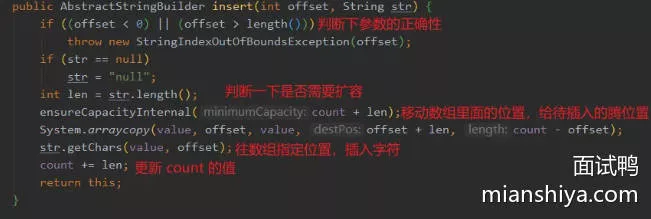
- 插入前先判断下数组长度足够,若不够就扩容,然后移动字符,给待插入的位置腾出空间,然后往对应位置插入字符,最后更新已有字符数
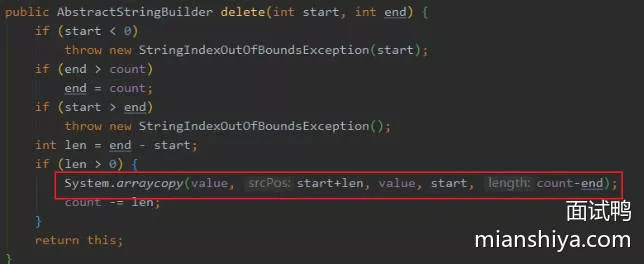
4. delete
5. 总结
StringBuilder内部实现!就是对数组的操作,而数组的特性就是内存连续,下标访问快- 回答这个设计题时,先说下需要实现哪些关键方法:
append, delete等,然后点明底层是char[]实现,在执行append, insert等操作时,判断是否需要扩容,然后调用System.arraycopy来完成字符串的变更 - 原生的
StringBuilder没有实现缩容操作,delete时,如果删除的字符过多,为了节省内存,实现缩容的操作
char[]是可以优化的,底层可以用byte[] + byte标志位(coder)来实现,更节省内存。因为char占用两个字节,对于latin系的字符来说,太大了,很浪费- 其实 jdk9 之后就是这样实现的

append()实现
15. 包装类、基本类型
- Java 中有 8 种基本数据类型,这些基本类型又有对应的包装类。
| 分类 | 基本数据类型 | 包装类 | 长度 | 表示范围 |
|---|---|---|---|---|
| 布尔型 | boolean | Boolean | / | / |
| 整型 | byte | Byte | 1 字节 | -128 ~127 |
| short | Short | 2 字节 | -32768 ~·32767 | |
| int | Integer | 4 字节 | -2,147,483,648 ~ 2,147,483,647 | |
| long | Long | 8 字节 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | |
| 字符型 | char | Character | 2 字节 | Unicode字符集中的任何字符 |
| 浮点型 | float | Float! | 4 字节 | 约-3.4E38~3.4E38 |
| double | Double | 8 字节 | 约-1.7E308~17E308 |
- Java是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。eg:在集合类中,无法将
int, double等类型放进去的。因为集合的容器要求元素是Object类型 - 为了让基本类型也具有对象的特征,就出现了包装类型,相当于将基本类型“包装起来”,使其具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作
1. 区别
- 默认值不同:基本类型的默认值是
0,false等,包装类默认为null - 初始化的方式不同:一个
new方式创建,一个则不需要 - 存储方式有所差异:基本类型主要保存在栈上面,包装类对象保存在堆上(成员变量的话,在不考虑JIT优化的栈上分配时,都是随着对象一起保存在堆上的)
16. JDK和JRE区别
JRE(Java Runtime Environment)指的是 Java 运行环境,包含了 JVM、核心类库和其他支持运行 Java 程序的文件
- JVM(Java Virtual Machine):执行 Java 字节码,提供了 Java 程序的运行环境
- 核心类库:一组标准的类库(如
java.lang、java.util等),供 Java 程序使用 - 其他文件:如配置文件、库文件等,支持 JVM 的运行
JDK(Java Development Kit)可以视为 JRE 的超集,是用于开发 Java 程序的完整开发环境,它包含了 JRE,以及用于开发、调试和监控 Java 应用程序的工具
- JRE:JDK 包含了完整的 JRE,因此它也能运行 Java 程序
- 开发工具:如编译器(javac)、调试器(jdb)、打包工具(jar)等,用于开发和管理 Java 程序
- 附加库和文件:支持开发、文档生成和其他开发相关的任务
17. JDK提供的工具
- 平日里面是否有过利用 JDK 的工具进行问题的分析、排查(注意,不要说什么 javac 之类的命令,主要想考察的是问题分析、排查方面的内容)
- eg:排查内存问题的时候,利用 jmap 生成堆转储文件,下载后利用 Eclipse 的 MAT 工具进行分析
如果大家没有排查经验,强烈建议去尝试一下,难度不高
列几个常见工具,建议可以用用
- javac:Java 编译器,用于将 Java 源代码(.java 文件)编译成字节码(.class 文件)
- java:Java 应用程序启动器,用于运行 Java 应用程序
- javadoc:文档生成器,用于从 Java 源代码中提取注释并生成 HTML 格式的 API 文档
- jar:归档工具,用于创建和管理 JAR(Java ARchive)文件
- jdb:Java 调试器,用于调试 Java 程序
- jps:JVM 进程状态工具,用于列出当前所有的 Java 进程
- jstat:JVM 统计监视工具,用于监视 JVM 统计信息
- jstatd:JVM 统计监视守护进程,用于在远程监视 JVM 统计信息
- jmap:内存映射工具,用于生成堆转储(heap dump)、查看内存使用情况
- jhat:堆分析工具,用于分析堆转储文件
- jstack:线程栈追踪工具,用于打印 Java 线程的栈追踪信息
- javap:类文件反汇编器,用于反汇编和查看 Java 类文件
- jdeps:Java 类依赖分析工具,用于分析类文件或 JAR 文件的依赖关系
- jinfo:Java配置信息工具
- VisualVM:图形化工具,可以得到虚拟机运行时的一些信息:内存分析、CPU 分析等等,在 jdk9 开始不再默认打包进 jdk 中
- 这属于线上排查能力,要实践,解决问题能力掌握
18. hashCode、equals、==区别
hashCode、equals、== 都是 Java 中比较对象的三种方式
hashCode:用于散列存储结构中确定对象的存储位置。用于快速比较两个对象是否不同。哈希码不同,它们肯定不相等equals:用于比较两个对象的内容是否相等,通常需要重写自定义比较逻辑==:用于比较两个引用是否指向同一个对象(即内存地址)。对于基本数据类型,比较值
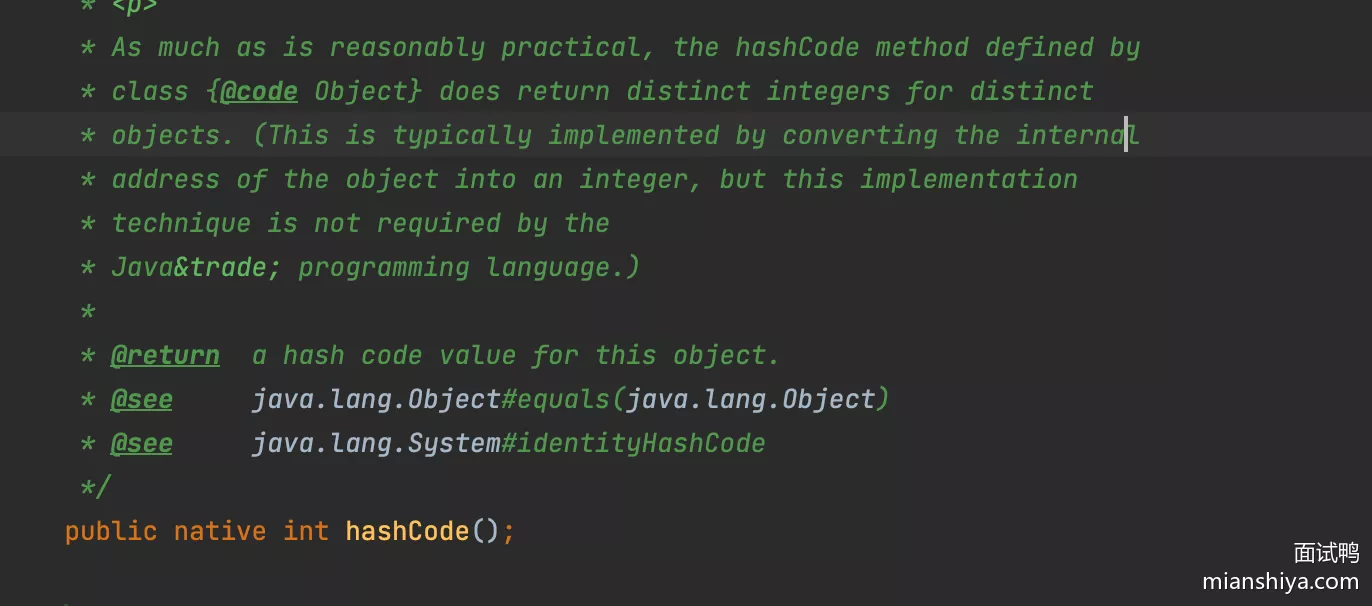
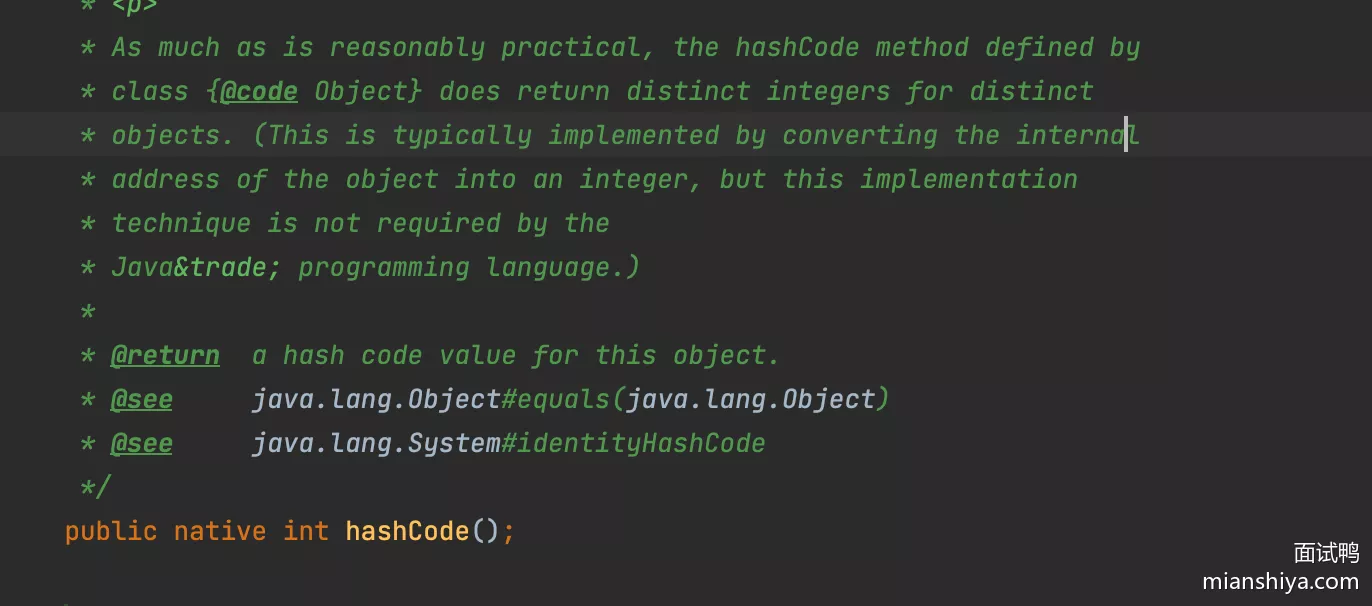
1. hashCode
方法返回对象的哈希码(整数),主要用于支持基于哈希表的集合,用来确定对象的存储位置,eg:HashMap、HashSet 等。
Object类中的默认实现会根据对象的内存地址生成哈希码(native方法)
- 两个对象
equals相等,那么它们必须具有相同的哈希码 - 两个对象哈希码相同,并不一定相等,被放在同一个哈希桶中
2. equals
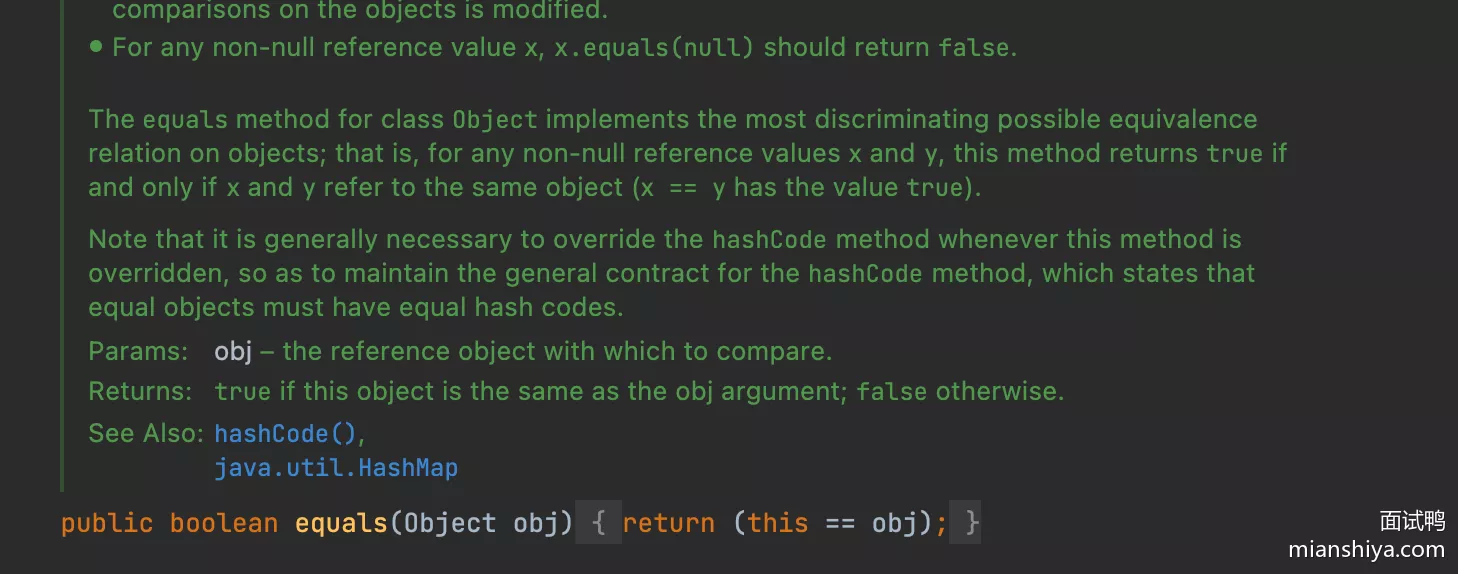
用于比较两个对象内容是否相等。Object 类中的默认实现会使用 == 操作符比较对象的内存地址
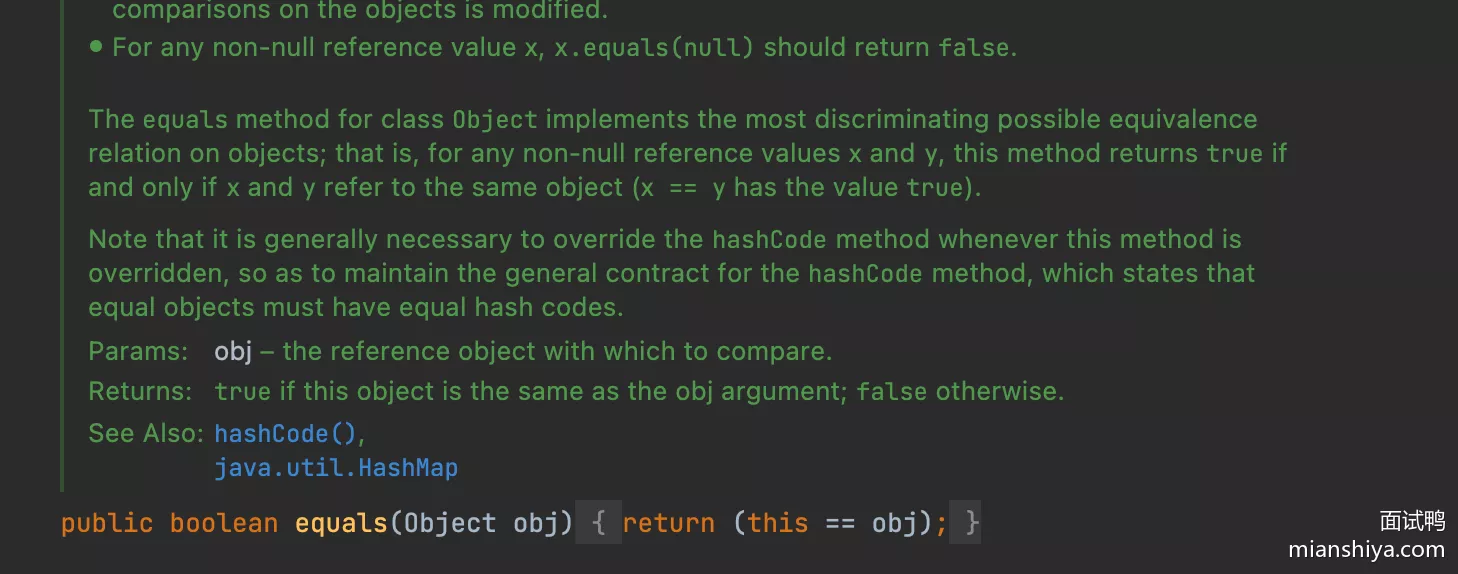
对于 equals 定义的比较,实际上还有以下五个要求:
- 自反性:对于任何非空引用值
x,x.equals(x)必须返回true - 对称性:对于任何非空引用值
x, y,如果x.equals(y)返回true,则y.equals(x)也必须返回true - 传递性:对于任何非空引用值
x, y, z,如果x.equals(y) == true且y.equals(z) == true,则x.equals(z) == true - 一致性:对于任何非空引用值
x, y,只要对象在比较中没有被修改,多次调用x.equals(y)应返回相同的结果 - 对于任何非空引用值
x,x.equals(null)必须返回false
3. ==
== 操作符用于比较两个引用是否指向同一个对象(即比较内存地址),如果是基本数据类型,== 直接比较它们的值
19. hashCode、equals关系
hashCode 是属于 Object 的一个方法,并且是个 native 方法,本质就是返回一个哈希码,即一个 int 值,一般是一个对象的内存地址转成的整数
equals,用来判断两个对象是否相同的,也是属于 Object 的一个方法,并且默认比较地址
一般情况下两者是没啥关系。但是将一个对象用在散列表的相关类时,是有关系的
1. HashSet
HashSet,常用来得到一个不重复的集合
- 因为 HashSet 是复用 HashMap 的能力存储对象。两个Obj的
equals()相等,hashCode()不等
建议不管会不会用到散列表,只要重写
equals()就一起重写hashCode(),肯定不会出错
20. 动态代理是什么
动态代理是 Java 提供的一种强大机制,用于在运行时创建代理类或代理对象,以实现接口的行为,而不需要提前在代码中定义具体的类。动态是相对于静态来说的,之所以动态就是因为动作发生在运行时
代理可以看作是调用目标的一个包装,通常用来在调用真实的目标之前进行一些逻辑处理,消除一些重复的代码。代理也是一种解耦,目标类和调用者之间的解耦,因为多了代理类这一层
- 静态代理:预先编码好一个代理类
- 动态代理:运行时生成代理类
主要用途:
- 简化代码:通过代理模式,可以减少重复代码,尤其是在横切关注点(如日志记录、事务管理、权限控制等)方面
- 增强灵活性:动态代理使得代码更具灵活性和可扩展性,因为代理对象是在运行时生成的,可以动态地改变行为
- 实现AOP:动态代理是实现面向切面编程(AOP, Aspect-Oriented Programming)的基础,可以在方法调用前后插入额外的逻辑
21. JDK、CGLIB动态代理区别
JDK 动态代理是基于接口的,所以要求代理类一定是有定义接口的
CGLIB 基于 ASM 字节码生成工具,通过继承的方式来实现代理类,所以要注意 final 方法
之间的性能随着 JDK 版本的不同而不同,以下内容取自:haiq的博客
- jdk6 下。运行次数较少,jdk 与 cglib 差距不明显,甚至更快一些;而当调用次数增加之后,cglib 表现稍微更快一些
- jdk7 下。逆转!在运行次数较少(1,000,000),jdk 比 cglib 快了差不多30%;而当调用次数增加(50,000,000),jdk 比 cglib 快了接近1倍
- jdk8 表现和 jdk7 基本一致
1. JDK动态代理
JDK 动态代理是基于接口的代理,使用 java.lang.reflect.Proxy 类和 java.lang.reflect.InvocationHandler 接口实现
// 接口
public interface Service {
void perform();
}
// 需要被代理的实现类
public class ServiceImpl implements Service {
@Override
public void perform() {
System.out.println("mianshiya.com");
}
}
JDK 动态代理处理类:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class ServiceInvocationHandler implements InvocationHandler {
private final Object target;
public ServiceInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("Before method invoke");
Object result = method.invoke(target, args);
System.out.println("After method invoke");
return result;
}
}
import java.lang.reflect.Proxy;
public class DynamicProxyDemo {
public static void main(String[] args) {
Service target = new ServiceImpl();
Service proxy = (Service) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
new ServiceInvocationHandler(target)
);
proxy.perform();
}
}
2. CGLIB
CGLIB 基于 ASM 字节码生成工具,通过继承的方式来实现代理类,所以不需要接口,可以代理普通类,但需要注意 final 方法(不可继承)
public class Service {
public void perform() {
System.out.println("mianshiya.com");
}
}
CGLIB 动态代理处理类:
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class ServiceMethodInterceptor implements MethodInterceptor {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before method invoke");
Object result = proxy.invokeSuper(obj, args);
System.out.println("After method invoke");
return result;
}
}
创建并使用动态代理对象:
import net.sf.cglib.proxy.Enhancer;
public class CglibDynamicProxyDemo {
public static void main(String[] args) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Service.class);
enhancer.setCallback(new ServiceMethodInterceptor());
Service proxy = (Service) enhancer.create();
proxy.perform();
}
}
22. 注解是什么原理
注解其实就是一个标记,可以标记在类上、方法上、属性上等,标记自身也可以设置一些值
- 有了标记之后,可以在解析时得到这个标记,然后做一些特别的处理,这就是注解的用处
- 没写具体是解析啥,因为不同的生命周期的解析动作是不同的
- eg:可以定义一些切面,在执行一些方法时,看下方法上是否有某个注解标记,如果是的话可以执行一些特殊逻辑(RUNTIME类型的注解)
注解生命周期有三大类,分别是:
RetentionPolicy.SOURCE:给编译器用的,不会写入 class 文件RetentionPolicy.CLASS:会写入 class 文件,在类加载阶段丢弃,也就是运行的时候就没这个信息了RetentionPolicy.RUNTIME:会写入 class 文件,永久保存,可以通过反射获取注解信息
1. @Override
给编译器用的,编译器编译的时候检查没问题就over了,class文件里面不会有 Override 这个标记
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
2. @Autowired
Spring 常见的 Autowired ,就是 RUNTIME 的,所以在运行时可以通过反射得到注解的信息,还能拿到标记的值 required
@Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Autowired {
boolean required() default true;
}
23. 反射用过吗
反射:Java 提供的能在运行期得到对象信息的能力,包括属性、方法、注解等,也可以调用其方法
- 一般在业务编码中不会用到反射,在框架上用的较多,因为很多场景需要很灵活,不确定目标对象的类型,届时只能通过反射动态获取对象信息
- eg:Spring 使用反射机制来读取和解析配置文件,从而实现依赖注入和面向切面编程等功能
- eg:动态代理场景可以使用反射机制在运行时动态地创建代理对象
优点:
- 动态地获取类的信息,不需要在编译时就知道类的信息
- 动态地创建对象,不需要在编译时就知道对象的类型
- 动态地调用对象的属性和方法,在运行时动态地改变对象的行为
缺点:
- 性能问题。正常调用没影响,但是在高并发场景下就一点性能问题就会放大
- 因为反射是在运行时进行的,程序每次反射解析检查方法的类型等都需要从 class 的类信息加载进行运行时的动态检查
- 所以 Apache BeanUtils 的 copy 在高并发下就有性能问题
优化:
- 缓存。eg:把第一次得到的 Method 缓存起来,后续就不需要再调用
Class.getDeclaredMethod进行动态加载了,避免反射性能问题
24. SPI有了解过吗
SPI(Service Provider Interface)服务提供接口是 Java 的机制,主要用于实现模块化开发和插件化扩展。SPI 机制允许服务提供者通过特定的配置文件将自己的实现注册到系统中,然后系统通过反射机制动态加载这些实现,而不需要修改原始框架的代码,从而实现了系统的解耦、提高了可扩展性
- 一个典型的 SPI 应用场景是 JDBC(Java 数据库连接库),不同的数据库驱动程序开发者可以使用 JDBC 库,然后定制自己的数据库驱动程序
- 主流 Java 开发框架中,几乎都使用到了 SPI 机制,eg:Servlet 容器、日志框架、ORM 框架、Spring 框架。所以这是 Java 开发者必须掌握的一个重要特性!
1. 如何实现SPI
1. 系统实现
其实 Java 内已经提供了 SPI 机制相关的 API 接口,可以直接使用,这种方式最简单
- 首先在
resources资源目录下创建META-INF/services目录,并且创建一个名称为要实现的接口的空文件 - 在文件中填写自己定制的接口实现类的完整类路径
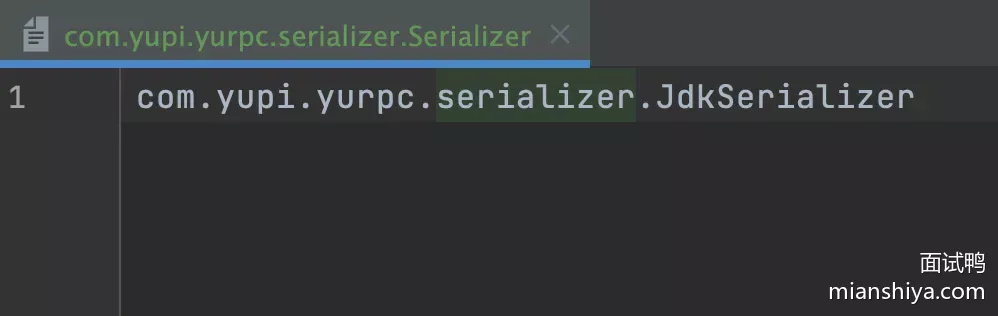
- 直接使用系统内置的
ServiceLoader动态加载指定接口的实现类
// 指定序列化器
Serializer serializer = null;
ServiceLoader<Serializer> serviceLoader = ServiceLoader.load(Serializer.class);
for (Serializer service : serviceLoader) {
serializer = service;
}
上述代码能够获取到所有文件中编写的实现类对象,选择一个使用即可
2. 自定义实现
系统实现 SPI 虽然简单,但是想定制多个不同的接口实现类,就没办法在框架中指定使用哪一个,也就无法实现 “通过配置快速指定序列化器” 的需求
- 所以需要自定义 SPI 机制的实现,只要能够根据配置加载到类即可
- eg:读取如下配置文件,能够得到一个《序列化器名称 => 序列化器实现类对象》的映射,之后就可以根据用户配置的序列化器名称动态加载指定实现类对象
jdk=com.yupi.yurpc.serializer.JdkSerializer
hessian=com.yupi.yurpc.serializer.HessianSerializer
json=com.yupi.yurpc.serializer.JsonSerializer
kryo=com.yupi.yurpc.serializer.KryoSerializer
25. 泛型作用, 泛型擦除是什么
泛型:可以把类型当作参数一样传递,使得像一些集合类可以明确存储的对象类型,不用显示地强制转化(在没泛型之前只能是Object,然后强转)
- 并且在编译期就能识别类型,类型错误则会提醒,增加程序的健壮性和可读性
泛型擦除:指参数类型其实在编译之后就被抹去了,也就是生成的 class 文件是没有泛型信息的
- 泛型擦除是为了向后兼容的实现手段,因为 JDK5 之前是没有泛型的,所以要保证 JDK5 之前编译的代码可以在高版本上跑
- 其实 Java 也可以搞别的手段来实现泛型兼容,只是擦除比较容易实现
- 擦除有个细节
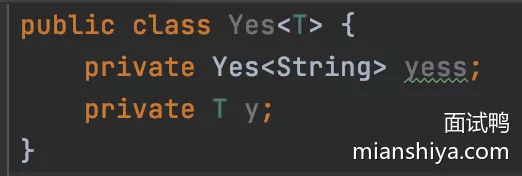
- 编译后的 class 文件
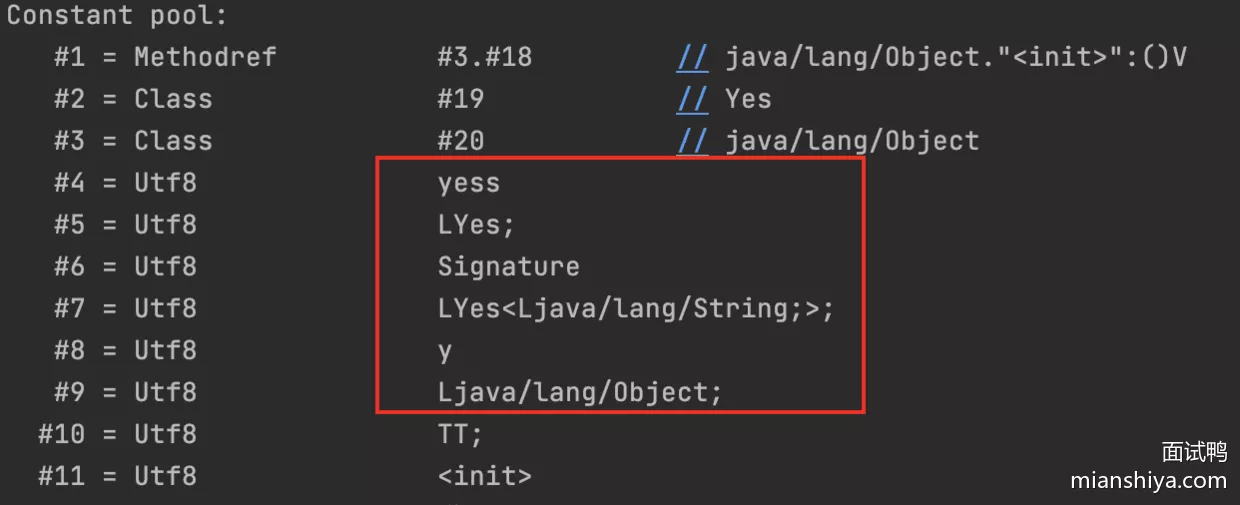
- yess 是有类型信息的,所以在代码里写死的泛型类型是不会被擦除的
- 解释了为什么根据反射是可以拿到泛型信息的,因为写死泛型没有被擦除!
26. 泛型的上下界限定符
上界限定符:extends,下界限定符:super
<? extends T>表示类型的上界,?要么是 T ,要么是 T 的子类
// 定义一个泛型方法,接受任何继承自Number的类型
public <T extends Number> void processNumber(T number) {
// 在这个方法中,可以安全地调用Number的方法
double value = number.doubleValue();
// 其他操作...
}
<? super T>表示类型的下界(也叫做超类型限定),?这个类型是 T 的超类型(父类型),直至 Object
// 定义一个泛型方法,接受任何类型的List,并向其中添加元素
public <T> void addElements(List<? super T> list, T element) {
list.add(element);
// 其他操作...
}
使用上下界通配符时,需要遵循 pecs 原则(Producer Extends, Consumer Super)。即上界生产,下界消费
- 如果要从集合中读取类型 T 的数据,并且不能写入,可以使用
? extends- eg:
processNumber(),从方法中得到 T 类型,也就是方法给生产
- eg:
- 如果要从集合中写入类型 T 的数据,并且不需要读取,可以使用
? super- eg:
addElements(),往方法中传入 T 类型,也就是方法进行消费
- eg:
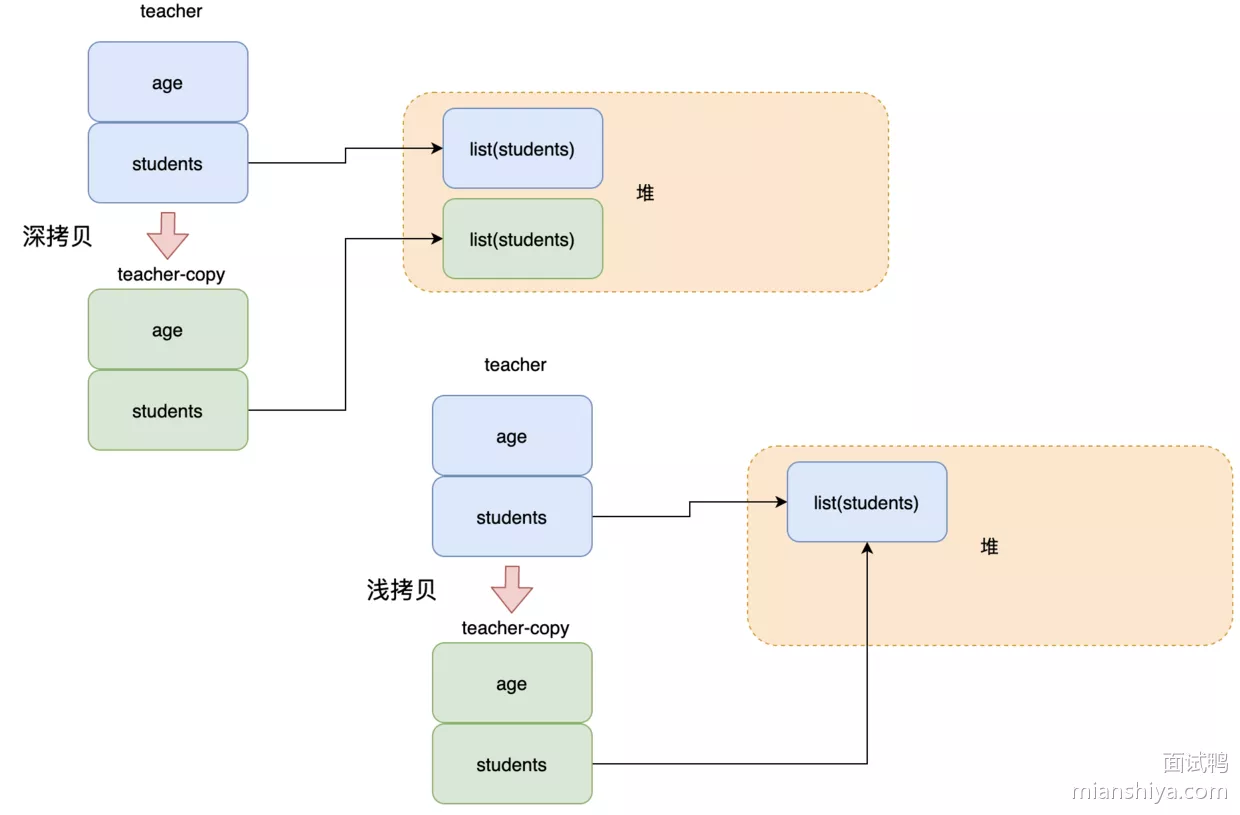
27. 深拷贝、浅拷贝
深拷贝是安全的,浅拷贝如果有引用对象则原先和拷贝对象修改引用对象的值会相互影响
- 深拷贝:完全拷贝一个对象,包括基本类型、引用类型,堆内的引用对象也会复制一份
- 浅拷贝:仅拷贝基本类型和引用,堆内的引用对象和被拷贝的对象共享
eg:现在 teacher 对象,然后成员里面有一个 student 列表
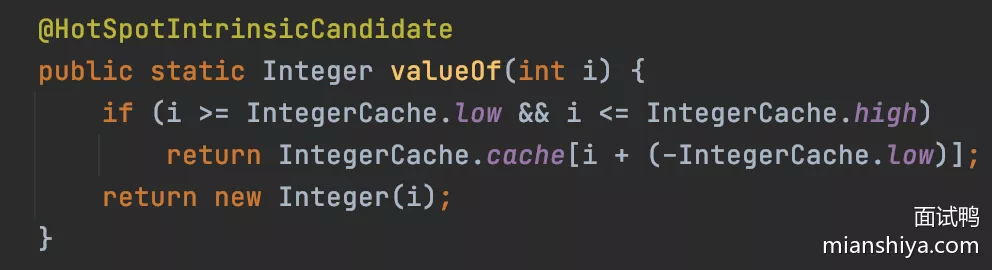
28. Integer缓存池知道吗
根据实践发现大部分的数据操作都集中在值比较小的范围,因此 Integer 搞了个缓存池,默认范围是 [-128, 127],可以根据通过设置 JVM-XX:AutoBoxCacheMax=<size> 来修改缓存的最大值,最小值改不了
- 原理:int 在自动装箱的时候会调用
Integer.valueOf,进而用到了IntegerCache - 就是判断下值是否在范围之内,如果是的话去
IntegerCache中取
IntegerCache在静态块中会初始化好缓存值
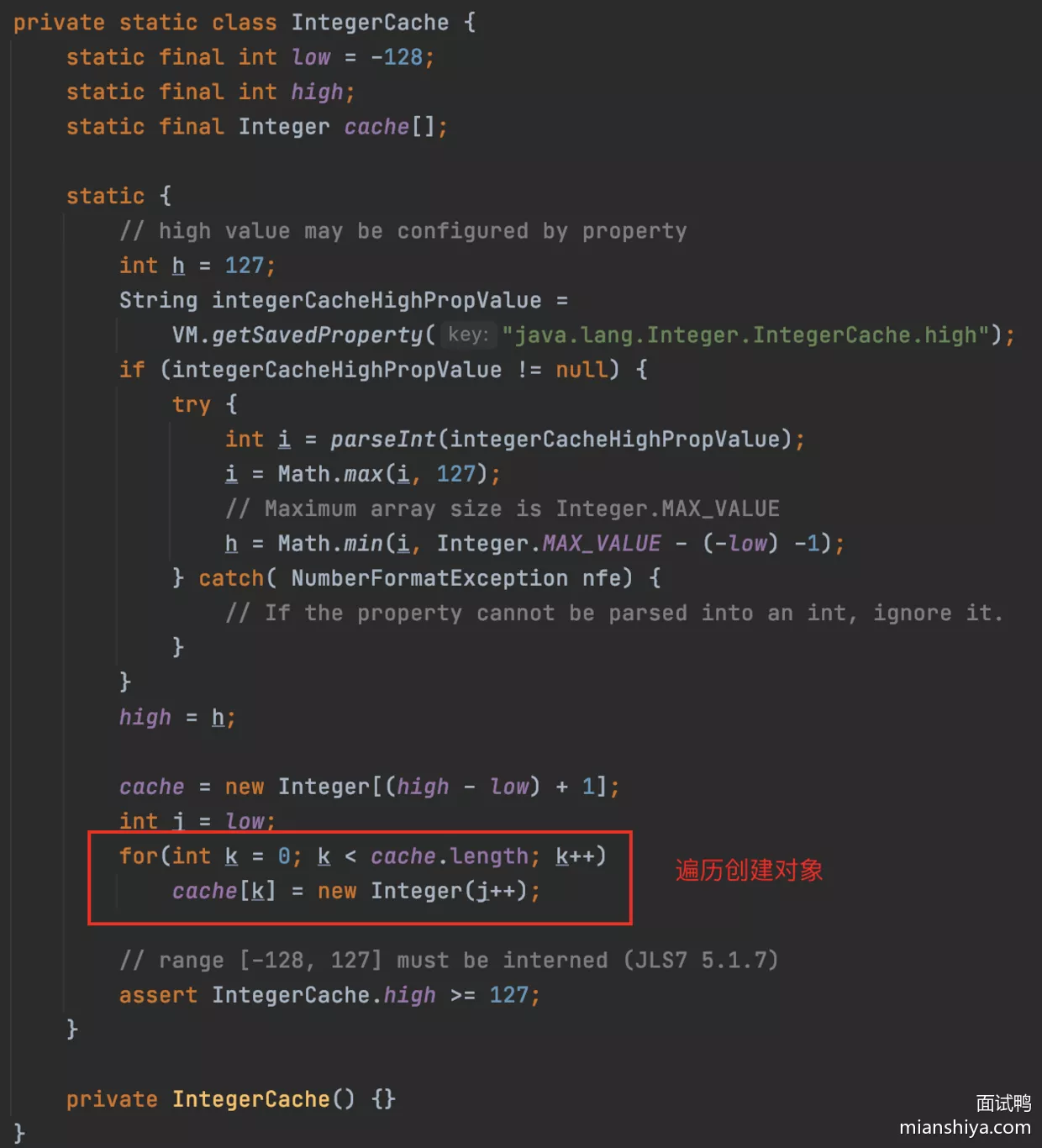
所以这里还有个面试题,就是啥 Integer 127 之内的相等,而超过 127 的就不等了,因为 127 之内的就是同一个对象,所以当然相等。
- Long 也是有的,范围是写死的
[-128, 127]
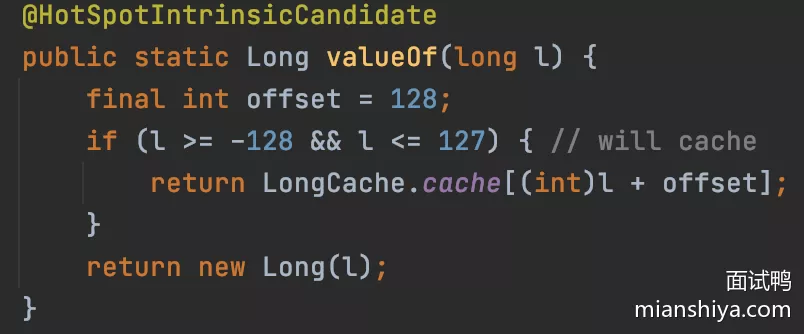
- 对 Float 和 Double 是没有滴,毕竟是小数,能存的数太多
29. 类加载过程
类加载:把类加载到 JVM 中,而输入一段二进制流到内存,之后经过一番解析、处理转化成可用的 class 类
类加载流程分为加载、连接、初始化三个阶段,连接还能拆分为:验证、准备、解析三个阶段。
所以总的来看可以分为 5 个阶段:
- 加载:将二进制流搞到内存中来,生成一个 Class 类
- 连接
- 验证:主要是验证加载进来的二进制流是否符合一定格式,是否规范,是否符合当前 JVM 版本等等之类的验证
- 准备:为静态变量(类变量)赋初始值,也即为它们在方法区划分内存空间。注意:静态变量,并且是初始值。eg:int 的初始值是 0
- 解析:将常量池的符号引用转化成直接引用。符号引用就是一个字面量,没有什么实质性的意义,只是一个代表。直接引用指的是一个真实引用,在内存中可以通过这个引用查找到目标
- 初始化:执行一些静态代码块,为静态变量赋值,这里的赋值才是代码里面的赋值,准备阶段只是设置初始值占个坑
30. 双亲委派知道不
- 类加载机制后基本上就会接着问双亲委派
双亲委派:如果一个类加载器需要加载类,那么首先它会把这个类加载请求委派给父类加载器去完成,如果父类还有父类则接着委托,每一层都是如此。一直递归到顶层,当父加载器无法完成这个请求时,子类才会尝试去加载
在 JDK9 之前,Java 自身提供了 3 种类加载器:
- 启动类加载器(
Bootstrap ClassLoader):属于JVM自身的一部分,用 C++ 实现,主要负责加载<JAVA_HOME>\lib目录中或被-Xbootclasspath指定路径中的并且文件名是被JVM识别的文件。它是所有类加载器的父亲 - 扩展类加载器(
Extension ClassLoader):Java 实现的,独立于JVM,负责加载<JAVA_HOME>\lib\ext目录中或被java.ext.dirs系统变量所指定路径的类库 - 应用程序类加载器(
Application ClassLoader):Java 实现的,独立于JVM。负责加载用户类路径(classPath)上的类库,程序中的默认加载器
双亲委派模型不是一种强制性约束,它是一种JAVA设计者推荐使用类加载器的方式
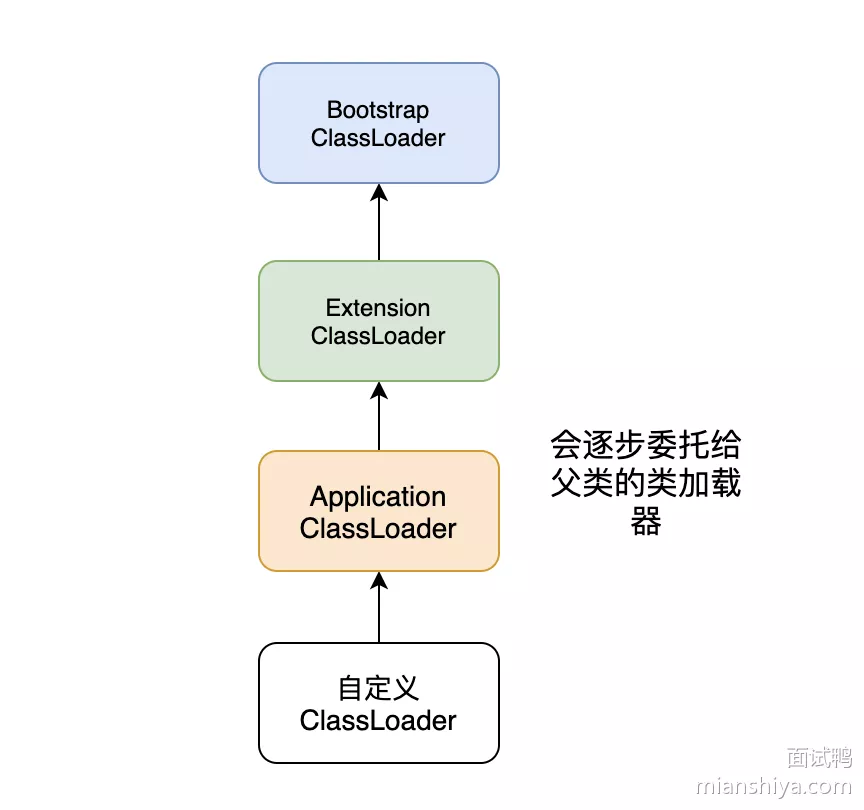
1. 为什么双亲委派机制
- 使得类有了层次的划分。
java.lang.Object加载它经过一层层委托,最终由Bootstrap ClassLoader加载,也就是最终由Bootstrap ClassLoader去找\lib中rt.jar里的java.lang.Object加载到JVM - 核心的基础类得到了保护。不法分子自定义
java.lang.Object,里面嵌了违规代码。按照双亲委派模型来实现的话,最终加载到JVM中的只会是rt.jar里的
2. 违反双亲委派的例子
典型的例子就是:JDBC
JDBC的接口是类库定义的,实现是在各大数据库厂商提供的jar包中,通过Bootstrap是找不到实现类的,所以就需要App ClassLoader去完成这个任务,这就违反了自下而上的委托机制了- 具体做法是搞了个线程上下文类加载器,通过
setContextClassLoader()默认设置了App ClassLoader,然后通过Thread.current.currentThread().getContextClassLoader()获得类加载器来加载
31. BigDecimal有了解过吗
BigDecimal是Java中提供的一个用于高精度计算的类,属于java.math包。它提供对浮点数、定点数的精确控制,特别适用于金融和科学计算等需要高精度的领域
- 通常情况下,大部分需要浮点数精确运算结果的业务场景(eg:涉及到钱的场景)都是通过 BigDecimal 来做的
主要特点:
- 高精度:
BigDecimal可以处理任意精度的数值,而不像float和double存在精度限制 - 不可变性:
BigDecimal是不可变类,所有的算术运算都会返回新的BigDecimal对象,而不会修改原有对象(注意性能问题) - 丰富的功能:提供了加、减、乘、除、取余、舍入、比较等多种方法,并支持各种舍入模式
《阿里巴巴 Java 开发手册》中提到:浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断
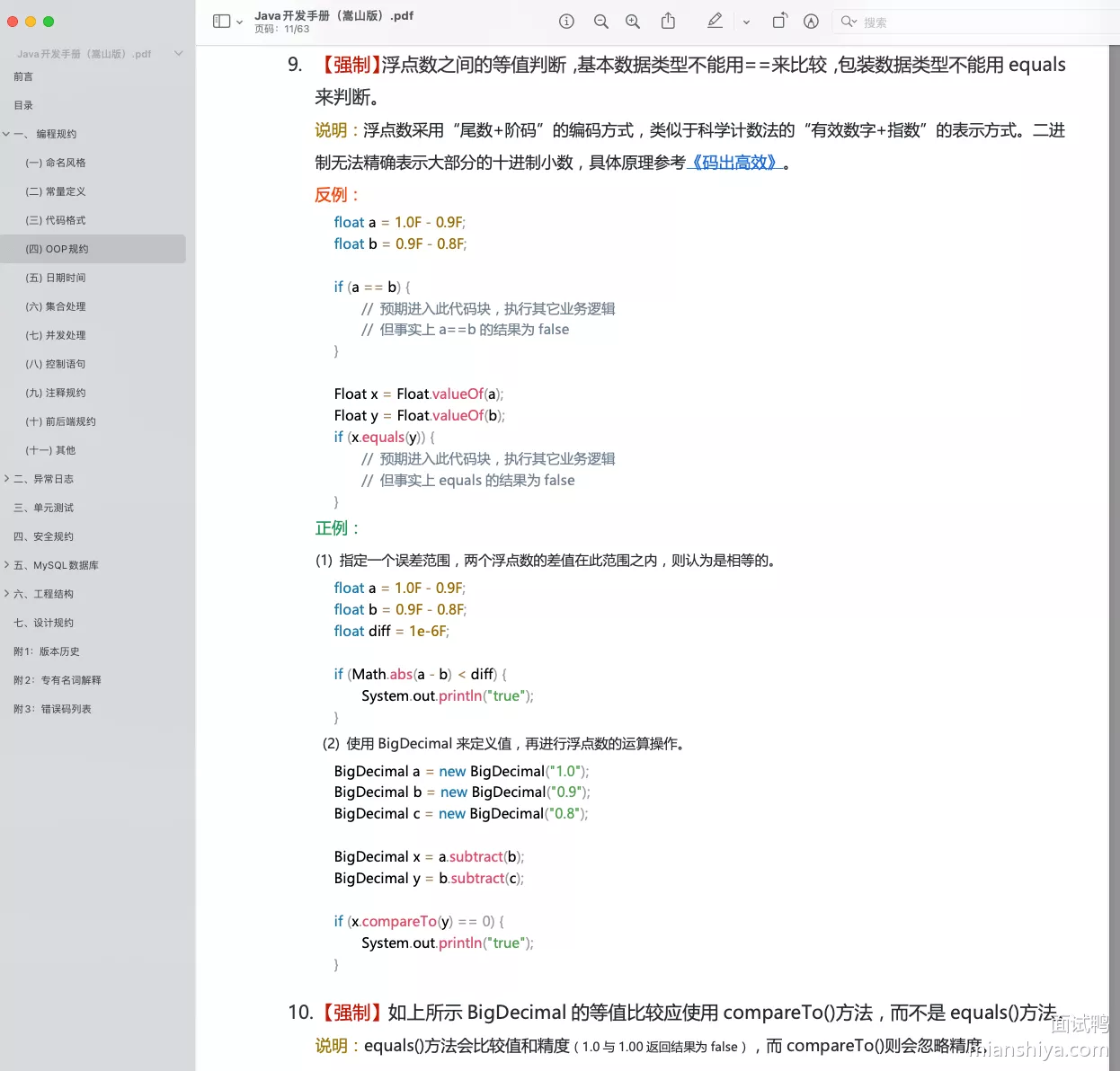
解决浮点数运算精度丢失问题。可以直接使用 BigDecimal 来定义浮点数的值,然后再进行浮点数的运算操作即可
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract(c);
System.out.println(x.compareTo(y)); // 0
1. 创建BigDecimal
1)使用字符串(推荐方式,因为字符串可以精确表示数值):
BigDecimal bd1 = new BigDecimal("123.45");
2)使用数值(不推荐,因为 double 和 float 有精度问题)
BigDecimal bd2 = new BigDecimal(123.45); // 可能会引入精度问题
3)使用 BigDecimal.valueOf 方法(推荐方式):
BigDecimal bd3 = BigDecimal.valueOf(123.45);
2. 四舍五入模式
RoundingMode.UP:向远离零的方向舍入RoundingMode.DOWN:向接近零的方向舍入RoundingMode.CEILING:向正无穷方向舍入RoundingMode.FLOOR:向负无穷方向舍入RoundingMode.HALF_UP:向“最近”的数字舍入,如果有两个相等的最近数字,则向上舍入RoundingMode.HALF_DOWN:向“最近”的数字舍入,如果有两个相等的最近数字,则向下舍入RoundingMode.HALF_EVEN:向“最近”的数字舍入,如果有两个相等的最近数字,则向相邻的偶数舍入
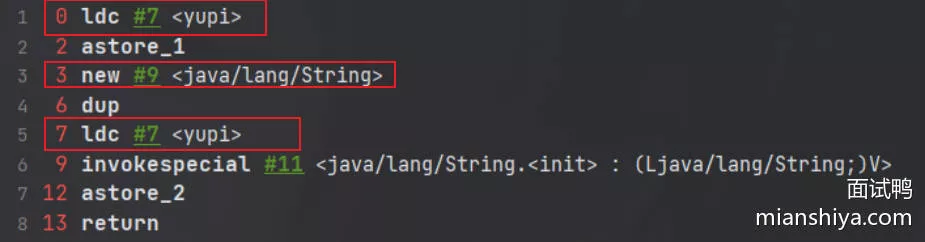
32. new String("")创建几个对象
1)如果字符串常量池中不存在字符串对象“yupi”的引用。那么它会在堆上创建两个字符串对象,其中一个字符串对象的引用会被保存在字符串常量池中
String s = new String("yupi");
对应的字节码:
ldc命令用于判断字符串常量池中是否保存了对应的字符串对象的引用- 如果保存了的话直接返回
- 如果没有保存的话,会在堆中创建对应的字符串对象并将该字符串对象的引用保存到字符串常量池中

2)如果字符串常量池中已存在字符串对象“yupi”的引用,则只会在堆中创建 1 个字符串对象“yupi”
// 字符串常量池中已存在字符串对象“yupi”的引用
String s1 = "yupi";
// 下面这段代码只会在堆中创建 1 个字符串对象“yupi”
String s2 = new String("yupi");
对应的字节码:
- 7 这个位置的
ldc命令不会在堆中创建新的字符串对象“yupi”,因为 0 这个位置已经执行了一次ldc命令。 7 的ldc命令会直接返回字符串常量池中字符串对象“yupi”对应的引用
33. final,finally,finalize区别
final:用于类、方法、变量,表示不可改变、不可继承finally:用于try-catch块中,无论是否抛出异常,finally块中的代码总会执行finalize:Object 类中的方法,供GCtor在回收对象之前调用,但由于其局限性和不确定性,不推荐使用
1. final
1. 修饰变量
被修饰的变量不可以被二次修改,即变成常说的常量
final int x = 10;
x = 20; // 这一部分如果修改的的话会报错 Cannot assign a value to final variable 'x'
2. 修饰方法
无法被子类进行重写(编译异常)
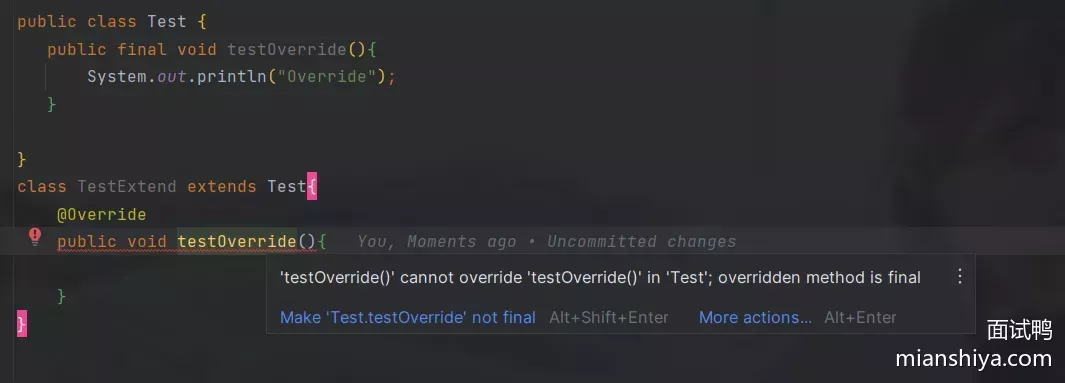
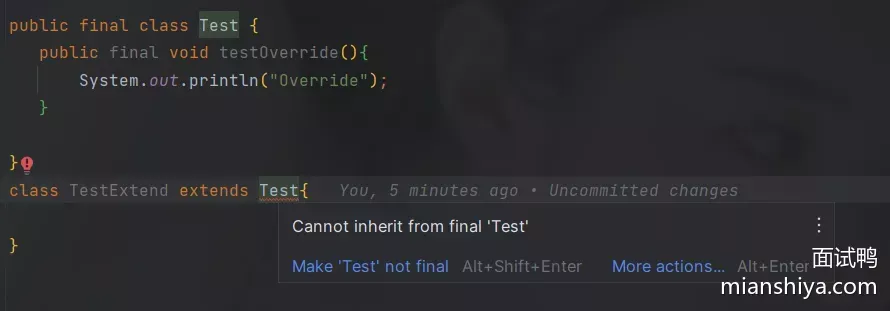
3. 修饰类
类无法被子类继承
2. finally
主要应用于异常处理,它经常和try、catch块一起搭配使用。无论是否捕获或处理异常,finally 块中的代码总是会执行
- 通常用于关闭资源,eg:输入/输出流、数据库连接等
try {
// 可能产生异常的代码
} catch (Exception e) {
// 异常处理代码
} finally {
// 正常情况下总是执行的代码块,常用于关闭资源
}
3. finalize
finalize 是 Object 类的一个方法,用于GC过程中的资源回收。在对象被垃圾收集器回收之前,finalize 方法会被调用,用于执行清理操作(eg:释放资源)
- finalize 方法已经被弃用,且不推荐使用,因为它不保证及时执行,并且其使用可能导致性能问题和不可预测的行为
protected void finalize() throws Throwable {
// 在对象被回收时执行清理工作
}
34. 平时写代码遇到乱码
什么是编解码:
- 编码:将字符按照一定的格式转换成字节流的过程
- 解码:就是将字节流解析成字符
用专业的术语来说,乱码是因为编解码时使用的字符集不一致导致的
- eg:将字符利用 UTF-8 编码后传输,然后用 GBK 来解码
1. 为什么要编解码呢
因为计算机底层的存储都是 0101,它可不认识什么字符。所以我们需要告诉计算机什么数字代表什么字符
2. 标准字符编码
ASCII 是美国国家标准协会 ANSI 就制定的一个标准规定了常用字符集的集合和对应的数字编号
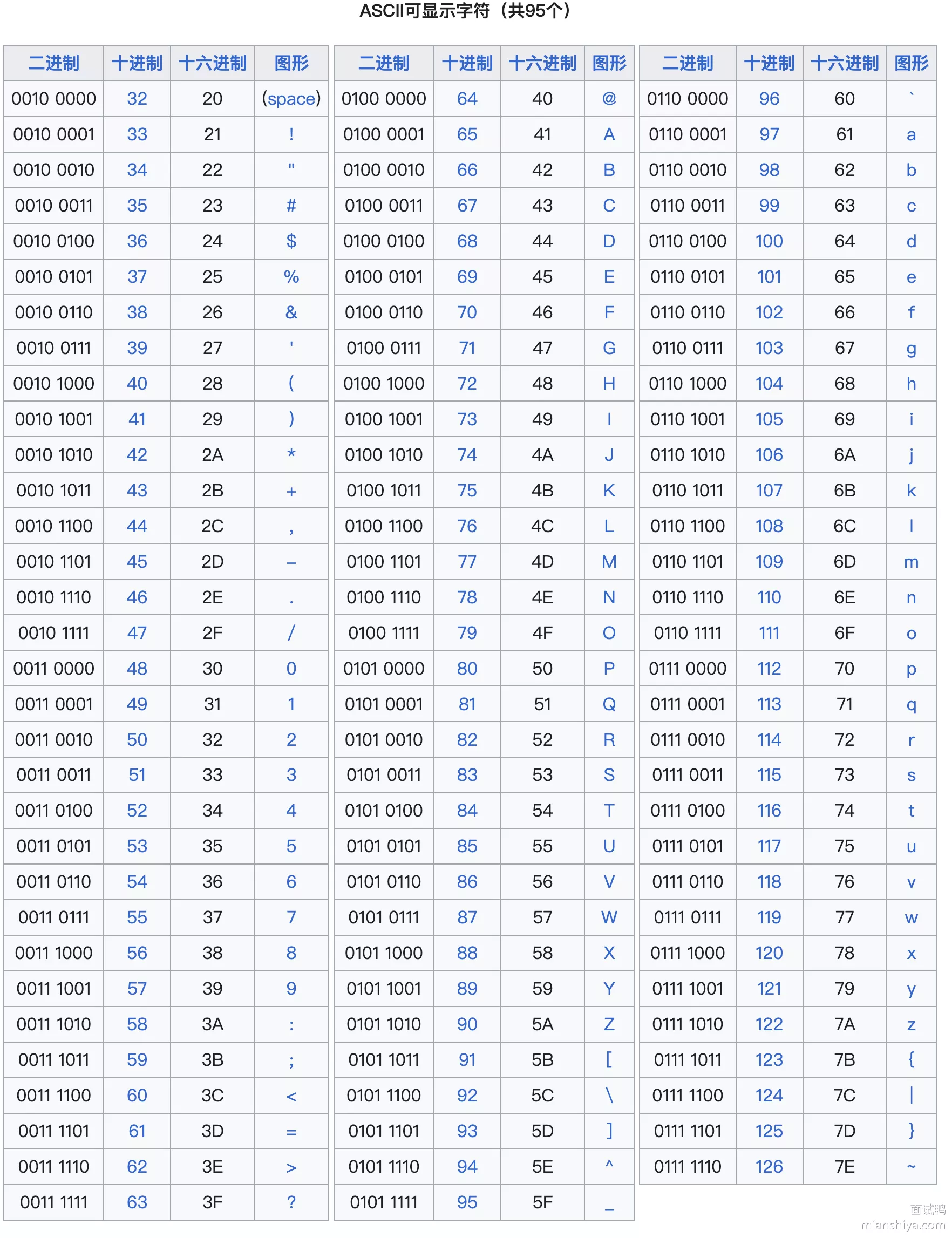
- 共 8 位,但是第一位都是 0,实际上就用了 7 位。可以看到完全就是美国标准,中文完全没有
- 中国制定了 GB2312 字符集,后续由发布了 GBK,基于 GB2312 增加了一些繁体字等字符,K 是扩展的意思
2. Unicode
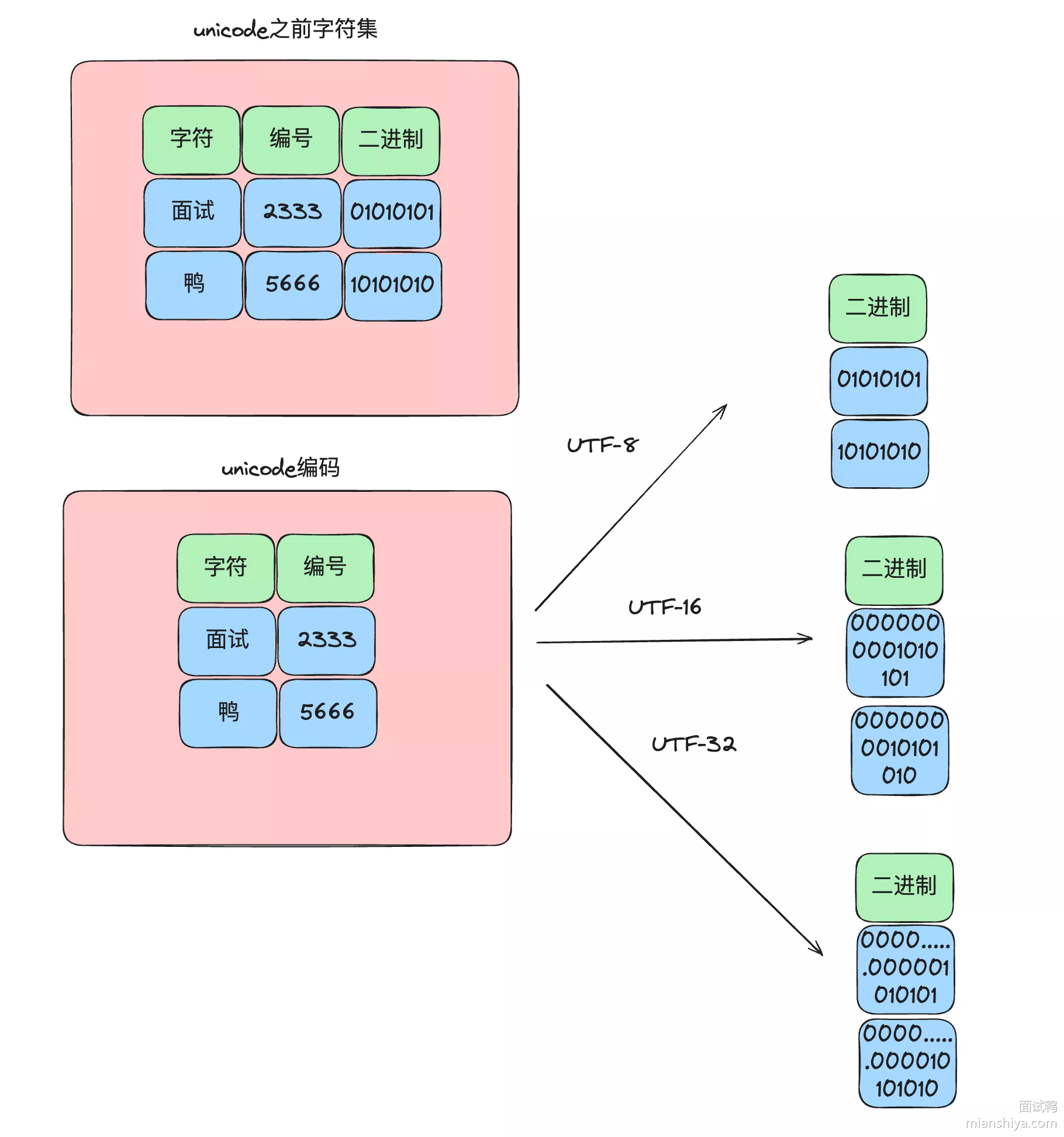
- 中国需要中国的字符编码,美国需要美国的,韩国还需要韩国的,所以每个国家都弄一个无法统一
- 所以就指定了一个统一码 Unicode,又译作万国码、统一字符码、统一字符编码,是信息技术领域的业界标准,其整理、编码了世界上大部分的文字系统,使得电脑能以通用划一的字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案!
Unicode 和之前的编码不太一样,它将字符集和编码实现解耦了
35. String中char[]改成byte[]
JDK9 把 String 中 char 数组改成了 byte 数组,你知道为什么吗?
为了节省内存空间,提高内存利用率
- JDK9之前,String 类是基于
char[]实现的,内部采用 UTF-16 编码,每个字符占用两个字节- 当前的字符仅需一个字节的空间,造成了浪费
- eg:一些
Latin-1字符用一个字节即可表示
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
- JDK9后,做了优化采用
byte数组实现
- 并引入了coder变量来标识编码方式(Latin-1、UTF-16)
- 对于大多数只包含
Latin-1字符(即每个字符可以用一个字节表示)的字符串,内存使用量减半
- JDK9后,做了优化采用
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
/**
* The value is used for character storage.
*/
@Stable
private final byte[] value;
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*/
private final byte coder;
}
1. Latin1
- Latin1 是国际标准编码 ISO-8859-1 的别名。Latin1 也是单字节编码,在 ASCII 编码的基础上,利用了 ASCII 未利用的最高位,扩充了 128 个字符,因此 Latin1 可以表示 256 个字符,并向下兼容 ASCII
- Latin1 收录的字符除 ASCII 收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在 ISO-8859-1 当中,在后来的修订版 ISO-8859-15 加入了欧元符号
- Latin1 编码范围是 0x00-0xFF,ASCII的编码范围是 0x00-0x7F
- Latin1 相对 ASCII 而言,较少被提及,其实 Latin1 的使用还是比较广泛的
- eg:MySQL(8.0之前)的数据表存储默认编码就是 Latin1
36. 调用外部可执行程序或系统命令
面试中一般不会问这题,大家仅做了解即可(除非是特殊岗位的一些场景)
在 Java 中,可以使用 Runtime 类或 ProcessBuilder 类来调用外部可执行程序或执行系统命令。这两种方法都能创建一个子进程来执行指定的命令或程序
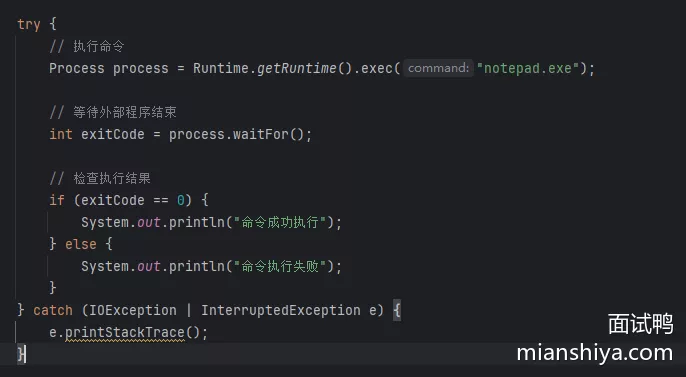
- 使用
Runtime.exec(),它允许你执行外部命令- 执行命令:使用
Runtime.getRuntime().exec方法执行命令 - 等待进程结束:使用
waitFor方法等待进程结束并获取退出码 - 需要获取返回的内容,可以通过 Process 对象中的
getInputStream()来获取字符输入流对象
- 执行命令:使用
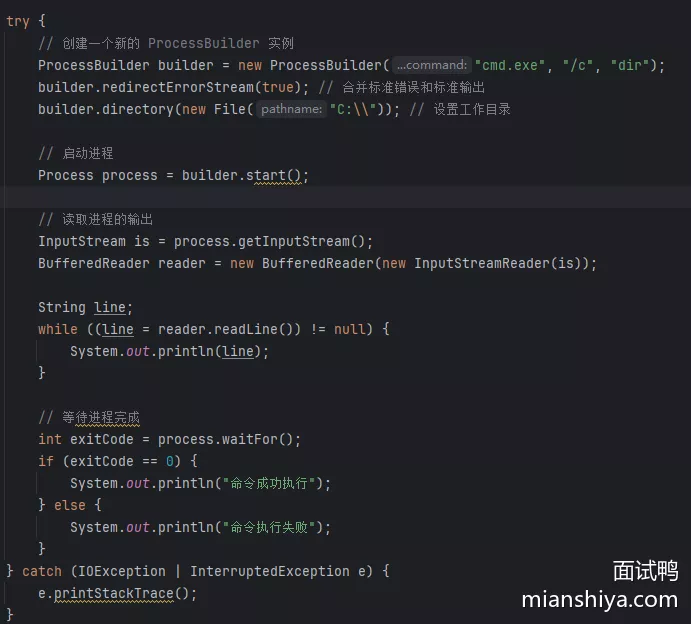
- 使用 ProcessBuilder 类提供了一个更灵活和强大的方式来管理外部进程。它允许你设置环境变量、工作目录,以及重定向输入和输出流
- 使用 ProcessBuilder 创建一个新的进程
- 设置命令:通过
command()指定要执行的命令及其参数或直接在构造函数内写入 - 启动进程:使用
start()启动进程 - 读取输出:通过
getInputStream()获取进程的输入流,并读取输出 - 等待进程结束:使用
waitFor()等待进程结束并获取退出码
37. 两次调用start()
抛出 IllegalThreadStateException 异常!在 Java 中,一个线程只能被启动一次!
- 因为一旦线程已经开始执行,它的状态不能再回到初始状态。线程的生命周期不允许它从终止状态回到可运行状态
1. 线程的生命周期
在 Java 中,线程的生命周期主要包括以下几个状态:
- 新建(New):当一个线程对象被创建时。eg:
Thread t = new Thread(); - 就绪(Runnable):当调用
start()时,线程进入就绪状态,等待 CPU 调度 - 运行(Running):线程被调度并执行
run()的内容 - 阻塞(Blocked):线程因为某些原因(eg:等待资源、锁等)进入阻塞状态
- 终结(Terminated):线程执行完
run()或因异常退出
38. 栈、队列区别
- 顺序不同:队列是先进先出(FIFO)而栈是先进后出(LIFO)
- 操作位置不同: 栈的操作仅限于栈顶,而队列的添加操作发生在队尾,删除操作发生在队头
- 用途不同: 队列通常用于处理需要按顺序处理的任务;栈通常用于处理具有最近相关性的任务,eg:函数调用、撤销操作等
1. 栈
栈:一种后进先出(Last In, First Out)的数据结构。最新添加的元素最先被移除
push:将元素压入栈顶pop:从栈顶弹出元素peek:查看栈顶的元素但不移除它
使用场景:
- 用于回溯算法,eg:深度优先搜索(DFS)
- 表达式求值中的操作符优先级处理
- 递归函数调用的系统栈
2. 队列
队列:一种先进先出(First In, First Out)的数据结构。最早添加的元素最先被移除
offer, add:将元素添加到队列尾部poll, remove:从队列头部移除元素peek, element:查看队列头部的元素但不移除它
使用场景:
- 用于任务调度系统,按顺序处理任务
- 广度优先搜索(BFS)算法
- 消息队列,按顺序处理消息
39. 什么是Optional类
Optional 是 Java8 引入的一个容器类,它用来表示一个值可能存在或不存在
Optional<User> userOption = Optional.ofNullable(userService.getUser(...));
if (!userOption.isPresent()) {....}
Optional 设计出来的意图是什么, Java 语言架构师 Brian Goetz 是这么说的:
- 意思就是:Optional 可以给返回结果提供了一个表示无结果的值,而不是返回 null
- 简单理解下:Optional 其实就是一个壳,里面放着原先的值,至于这个值是不是 null 另说,反正拿到的这个壳肯定不是 null
Our intention was to provide a limited mechanism for library method return types where there needed to be a clear way to represent "no result", and using null for such was overwhelmingly likely to cause errors.

简化平日里一系列判断 null 的操作
Yes yes = getYes();
if (yes != null) {
Address yesAddress = yes.getAddress();
if (yesAddress != null) {
Province province = yesAddress.getProvince();
System.out.println(province.getName());
}
}
throw new NoSuchElementException(); // 如果没找到就抛错
Optional.ofNullable(getYes())
.map(a -> a.getAddress())
.map(p -> p.getProvince())
.map(n -> n.getName())
.orElseThrow(NoSuchElementException::new);
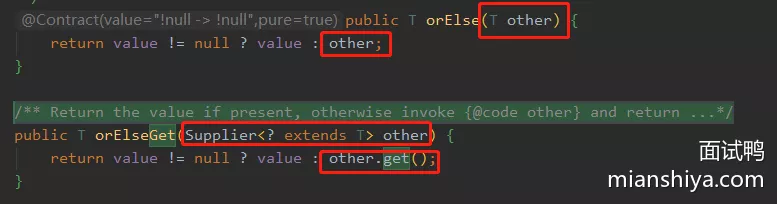
1. orElseGet(), orElse()
- 都是处理当值为
null时的兜底逻辑 orElse(), orElseGet()都会被执行
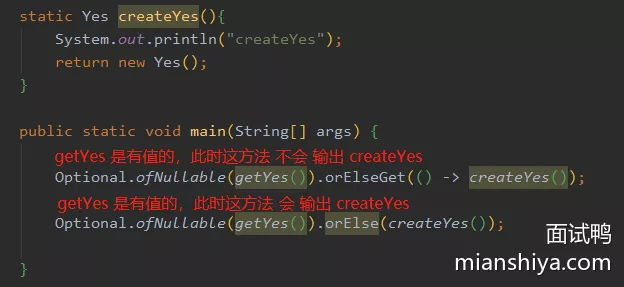
orElse(createYes()),在参数入栈之前,执行了createYes()得到结果,然后入栈orElseGet(Supplier),直接入栈,lambda 的延迟执行特性
40. I/O流
Java 的 I/O 流(Input/Output Streams)是用于处理输入和输出操作的类和接口,主要用于读取和写入数据,可以处理不同类型的数据源和目标。eg:文件、网络连接、内存缓冲区等
I/O 流分为两类:
- 输入流(Input Stream):用于读取数据的流
- 输出流(Output Stream):用于写入数据的流
- 字节流(Byte Streams):用于处理字节数据,适用于所有类型的 I/O 操作
- 输入流(Input Stream)
FileInputStream:从文件中读取字节数据BufferedInputStream:为输入流提供缓冲功能,提高读取性能DataInputStream:读取基本数据类型的数据
- 输出流(Output Stream)
FileOutputStream:将字节数据写入文件BufferedOutputStream:为输出流提供缓冲功能,提高写入性能DataOutputStream:写入基本数据类型的数据
- 输入流(Input Stream)
- 字符流(Character Streams):用于处理字符数据,适用于文本文件
- 输入流(Reader)
FileReader:从文件中读取字符数据BufferedReader:为字符输入流提供缓冲功能,提高读取性能InputStreamReader:将字节流转换为字符流
- 输出流(Writer)
FileWriter:将字符数据写入文件BufferedWriter:为字符输出流提供缓冲功能,提高写入性能OutputStreamWriter:将字符流转换为字节流
- 输入流(Reader)
1. 扩展:I/O必备知识:
- 理解基本的 I/O 类和接口:InputStream、OutputStream、Reader、Writer 及其常见子类
- 理解缓冲流的作用:BufferedReader、BufferedWriter、BufferedInputStream、BufferedOutputStream,它们可以提高 I/O 操作的性能
- 异常处理:I/O 操作容易出现 IOException,需要进行适当的异常处理
- 资源管理:使用 try-with-resources ,确保 I/O 流在使用完毕后正确关闭
- 字符编码:理解和正确使用字符编码(如 UTF-8),避免乱码
- NIO(New I/O):了解 Java NIO(eg:
java.nio包中的类),它提供了更高效的 I/O 操作,适用于需要高性能 I/O 的场景
41. 网络编程
笔试题中,手写一个基于 Java 实现网络通信的代码
Java 的网络编程主要利用 java.net 包,它提供了用于网络通信的基本类和接口
基本概念:
- IP 地址:用于标识网络中的计算机
- 端口号:用于标识计算机上的具体应用程序或进程
- Socket(套接字):网络通信的基本单位,通过 IP 地址和端口号标识
- 协议:网络通信的规则。eg:TCP(传输控制协议)和 UDP(用户数据报协议)
核心类:
Socket:用于创建客户端套接字ServerSocket:用于创建服务器套接字DatagramSocket:用于创建支持 UDP 协议的套接字URL:用于处理统一资源定位符URLConnection:用于读取和写入 URL 引用的资源
以下代码时基于 TCP 通信的,一般笔试考察的都是 TCP
import java.io.*;
import java.net.*;
public class TCPServer {
public static void main(String[] args) {
try (ServerSocket serverSocket = new ServerSocket(8080)) {
System.out.println("Server is listening on port 8080");
while (true) {
Socket socket = serverSocket.accept();
// 异步处理,优化可以用线程池
new ServerThread(socket).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
class ServerThread extends Thread {
private Socket socket;
public ServerThread(Socket socket) {
this.socket = socket;
}
public void run() {
try (PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
// 读取客户端消息
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
String message = in.readLine();
System.out.println("Received: " + message);
// 响应客户端
out.println("Hello, client!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
import java.io.*;
import java.net.*;
public class TCPClient {
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080);
// 发送消息给服务器
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
out.println("Hello, server!");
// 接收服务器的响应
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
String response = in.readLine();
System.out.println("Server response: " + response);
} catch (IOException e) {
e.printStackTrace();
}
}
}
42. Java数据类型
基本数据类型、引用数据类型
- 基本数据类型(Primitive Data Types)
- 整型:byte(8位有符号整数)、short(16位有符号整数)、int(32位有符号整数)、long(64位有符号整数,后缀 L 或 l)
- 浮点型:float(32位浮点数,后缀 F 或 f)、double(64位浮点数,后缀 D 或 d)
- 字符型:char(16位 Unicode 字符)
- 布尔型:boolean(只有两个可能的值:true 或 false)
- 引用数据类型(Reference Data Types)
- 类(Class):用户自定义的类或 Java 内置的类
- 接口(Interface):定义了类必须实现的方法的契约
- 数组(Array):一种容器对象,可以包含固定数量的单一类型值
- 枚举(Enumeration):用于表示一组预定义的常量,使代码更加简洁、可读
- 注解(Annotation):修饰方法或者类或者属性
43. 自动装箱和拆箱
自动装箱(Autoboxing)、拆箱(Unboxing)是 Java 语言中的一种特性,允许自动地在基本数据类型和相应的包装类之间进行转换。极大地简化了代码,使得基本类型和包装类之间的转换更加透明和自然
- 自动装箱(Autoboxing)
- Java 编译器自动将基本数据类型转换为对应的包装类
public class AutoboxingExample {
public static void main(String[] args) {
// 自动装箱:int(10) 转换为 Integer
Integer integerObject = 10;
System.out.println("Integer object: " + integerObject);
}
}
- 自动拆箱(Unboxing)
- Java 编译器自动将包装类转换为对应的基本数据类型
public class UnboxingExample {
public static void main(String[] args) {
// 自动拆箱:Integer 转换为 int
Integer integerObject = 10;
int intValue = integerObject;
System.out.println("int value: " + intValue);
}
}
1. 注意事项
- 性能影响:虽然自动装箱和拆箱提供了方便,但它们会产生额外的对象创建和拆箱操作,可能会影响性能,尤其是在循环或频繁使用的场景中
NullPointerException:在进行拆箱操作时,如果包装类对象为null
44. 什么是迭代器
迭代器(Iterator)其实是一种设计模式,用于遍历集合(例如 List、Set、Map 等)中的元素
- 封装性:它将集合遍历行为和具体的实现分离,使得使用者不需要了解集合具体的内部实现
- 一致性:所有的集合都实现了 Iterator 接口,因此对于不同集合的遍历代码都是一致的
- 灵活性:因为遍历接口一致,使得可以很灵活的替换底层实现的集合而不需要改变上层的遍历代码
Iterator 是一个接口,在 java.util 包中的,常用的方法是:
hasNext():如果迭代器还有更多的元素可以迭代,则返回 true,否则返回 falsenext():返回迭代器的下一个元素。如果没有更多元素,抛出NoSuchElementExceptionremove():从底层集合中移除next()返回的上一个元素。这个方法是可选的,不是所有的实现都支持该操作。如果不支持,调用时会抛出UnsupportedOperationException
Iterator 提供了单向遍历方法,如果需要支持双向遍历,使用 ListIterator 接口
public class IteratorExample {
public static void main(String[] args) {
// 创建一个 List 集合
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Cherry");
// 获取集合的迭代器
Iterator<String> iterator = list.iterator();
// 使用迭代器遍历集合
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
// 移除集合中的元素
iterator = list.iterator(); // 重新获取迭代器
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("Banana")) {
iterator.remove();
}
}
// 再次遍历集合,确认元素已被移除
System.out.println("After removal:");
iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
45. 运行时异常、编译时异常区别
在 Java 中其实分了两大类异常,它们之间的差别主要在于是否是编译时检查
- 受检异常(checked exception)就是编译时异常,继承自
Exception,即在编译阶段检查代码中可能会出现的异常,需要开发者显示的捕获(catch)或声明抛出(throw)这种异常,否则编译就会报错,这是一种强制性规范- 常见的有:
IOException、SQLException、FileNotFoundException等
- 常见的有:
- 非受检异常(unchecked exception)就是运行时异常,继承自
RuntimeException类。是指在运行期间可能会抛出的异常,编译期不强制要求处理,之所以不强制是因为它可以通过完善代码避免报错- 常见的有:
NullPointerException、ArrayIndexOutOfBoundsException、ArithmeticException等
- 常见的有:
46. Java中的继承
Java 中的继承是面向对象编程(OOP)的一个核心概念,它允许新创建的类(称为子类或派生类)继承现有类(称为父类或基类)的属性和方法
- 通过继承,子类可以复用、扩展、修改父类的行为,提高了代码的复用性,实现了多态
- 重写使用
@Override注释来标明,并且方法签名(方法名称、方法参数类型与顺序)必须与父类中的方法相同 - Java 只支持单继承,即一个类只能继承一个直接父类。但是,通过接口,Java 实现了多继承的功能
class Animal {
void breathe() {
System.out.println("Breathing");
}
}
class Dog extends Animal {
void bark() {
System.out.println("Barking");
}
@Override
void breathe() {
System.out.println("Breathing through lungs");
}
}
public class InheritanceExample {
public static void main(String[] args) {
Animal myAnimal = new Dog(); // 多态性
myAnimal.breathe(); // 调用 Dog 类的 breathe()
((Dog) myAnimal).bark(); // 向下转型并调用 Dog 类的 bark()
}
}
47. 什么是封装
封装(Encapsulation)是面向对象编程(OOP)的核心概念之一,它指的是将对象的数据(属性)和行为(方法)组合在一起,并隐藏内部的实现细节
- 数据隐藏
- 封装允许对象隐藏其内部状态和实现细节,只暴露出一个可以被外界访问和操作的接口
- 访问控制
- 通过使用访问修饰符(eg:
private、protected、public),封装可以限制对类成员的访问权限
- 通过使用访问修饰符(eg:
- 创建对象
- 封装使得创建具有复杂内部结构的对象变得简单,因为用户只需要通过公共接口与之交互
- 接口与实现分离
- 封装将对象的接口与其实现分离,这样即使实现改变,接口保持不变,对使用对象的客户代码影响较小
- 数据抽象
- 封装提供了一种抽象,只显示必要的信息,隐藏不必要的实现细节
public class Car {
private String model; // 私有属性,外部无法直接访问
private int year;
// 构造方法
public Car(String model, int year) {
this.model = model;
this.year = year;
}
// getter 方法
public String getModel() {
return model;
}
// setter 方法
public void setModel(String model) {
this.model = model;
}
// 行为方法
public void startEngine() {
System.out.println("Engine started for " + model);
}
}
public class EncapsulationExample {
public static void main(String[] args) {
Car myCar = new Car("Toyota", 2021);
myCar.startEngine(); // 使用公共方法
// 使用 getter 和 setter 方法访问和更新属性
System.out.println("Car model: " + myCar.getModel());
myCar.setModel("Honda");
}
}
48. 访问修饰符有哪些
Java 中的访问修饰符用于控制类、方法和变量的访问级别
public- 最宽松的访问级别,可以被任何其他类访问
- 适用范围:类、接口、字段、方法、构造函数
protected- 成员可以在同一个包中的其他类以及不同包中的子类中访问
- 适用范围:字段、方法、构造函数。不适用于顶级类
default(无修饰符)- 如果没有指定访问修饰符(即默认访问级别),那么类成员只能在同一个包内被访问,不同包中的类不能访问
- 适用范围:类、字段、方法、构造函数
private- 最严格的访问级别,类成员只能在定义它的类内部访问
- 适用范围:字段、方法、构造函数。不适用于顶级类
| 修饰符 | 当前类 | 同一包内 | 子类(不同包) | 其他包 |
|---|---|---|---|---|
| public | 是 | 是 | 是 | 是 |
| protected | 是 | 是 | 是 | 否 |
| 默认 | 是 | 是 | 否 | 否 |
| private | 是 | 否 | 否 | 否 |
修饰符适用范围:
- 顶级类(即不是内部类):不能是
protected, private - 接口和类:可以是
public, default - 方法和构造函数:可以是
public, protected, default, private - 变量(字段):可以是
public, protected, default, private
49. 静态方法、实例方法区别
1. 静态方法
- 使用 static 关键字声明的方法
- 属于类,而不是类的实例
- 可以通过类名直接调用,也可以通过对象调用(这种方式不推荐,因为它暗示了实例相关性)
- 可以访问类的静态变量和静态方法。不能直接访问实例变量和实例方法(因为实例变量和实例方法属于对象)
- 随着类的加载而加载,随着类的卸载而消失
典型用途:
- 工具类方法。eg:Math 类中的静态方法
Math.sqrt(), Math.random() - 工厂方法,用于返回类的实例
2. 实例方法
- 不使用 static 关键字声明的方法
- 属于类的实例
- 必须通过对象来调用
- 可以访问实例变量和实例方法。也可以访问类的静态变量和静态方法
- 随着对象的创建而存在,随着对象的销毁而消失
典型用途:
- 操作或修改对象的实例变量
- 执行与对象状态相关的操作
| 特性 | 静态方法 | 实例方法 |
|---|---|---|
| 关键字 | static | 无 |
| 归属 | 类 | 对象 |
| 调用方式 | 通过类名、对象调用 | 通过对象调用 |
| 访问权限 | 只能访问静态变量、静态方法 | 可以访问实例变量、实例方法、静态变量、静态方法 |
| 典型用途 | 工具类方法、工厂方法 | 操作对象实例变量、与对象状态相关的操作 |
| 生命周期 | 类加载时存在,类卸载时消失 | 对象创建时存在,对象销毁时消失 |
3. 注意事项
- 静态方法中不能使用 this 关键字,因为 this 代表当前对象实例,而静态方法属于类,不属于任何实例
- 静态方法可以被重载(同类中方法名相同,但参数不同),但不能被子类重写(因为方法绑定在编译时已确定)。实例方法可以被重载,也可以被子类重写
- 静态方法不具有多态性,即不支持方法的运行时动态绑定
- 实例方法中可以直接调用静态方法和访问静态变量
50. for、foreach区别
1. for
传统的 for 循环具有更大的灵活性和控制力
- 灵活性:可以控制循环的初始值、终止条件、步进方式。可以使用任何条件和任何步进表达式,通过多种变量进行复杂的控制和操作
- 适用于数组:可以通过索引访问数组的元素
- 支持修改集合:可以在循环体中修改集合中的元素
2. foreach
它提供了一种更简洁的语法来遍历数组和集合
- 简洁性:语法更简单,减少了初始化、条件检查和更新的样板代码。适合用于遍历数组和实现了 Iterable 接口的集合
- 只读访问:不提供对当前索引的访问,因此不适合需要根据索引进行复杂操作的场景
- 安全性:在遍历过程中不能修改集合的结构(eg:不能在遍历 List 的同时添加、删除元素),否则抛出
ConcurrentModificationException