04-index
clustered 英 [ˈklʌstəd] 美 [ˈklʌstərd] adj. 成群的;成簇的, v. 群聚;聚集。cluster的过去分词和过去式
cardinality 英 [kɑːdɪˈnælɪti] n. 基数;集的势
straight 英 [streɪt] adj. 直的;直筒型(非紧身)的;准的;正中目标的; adv. 直;直接;径直;笔直地
- 数据结构和算法动态可视化
- 印度学习网站
- 95_sakila说明.md
- 探索HyperLogLog算法(含Java实现)
- join官网——算法
- join官网——优化
- Use of Index Extensions
- Server Status Variables
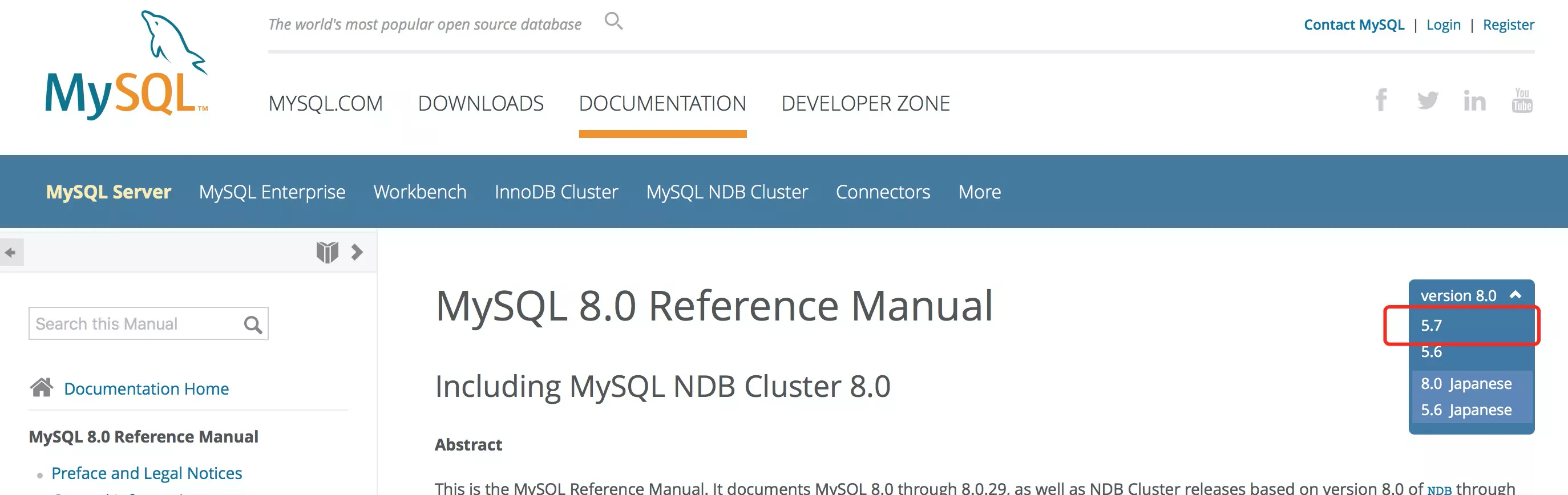
1. explain
- explain_官网地址
- 83_explain.md
- 重要属性
- id:执行顺序
- select_type:查询类型
- table:表
- type:访问类型。一般情况下,得保证查询至少达到range级别,最好能达到ref
- key:实际使用的索引
- key_len:长度越短越好
- extra:额外信息

2. Structure
- 数据结构学习网站
- index本质为数据
- 定位文件
- 定位offset(偏移量)。cursor游标,
seek()移动cursor到指定offset

1. hash表
哈希表可以完成索引的存储,每次在添加索引的时候,需要计算指定列的hash值,取模运算后计算出下标,将元素插入下标位置即可
- 优点:
- 等值查询很快
- 缺点:
- 所有data需要加载到内存,比较耗费内存空间(Memory存储引擎用Hash_index)
- data无序,范围查询要全遍历,效率低。企业或者实际工作环境中范围查询更多,而不是等值查询

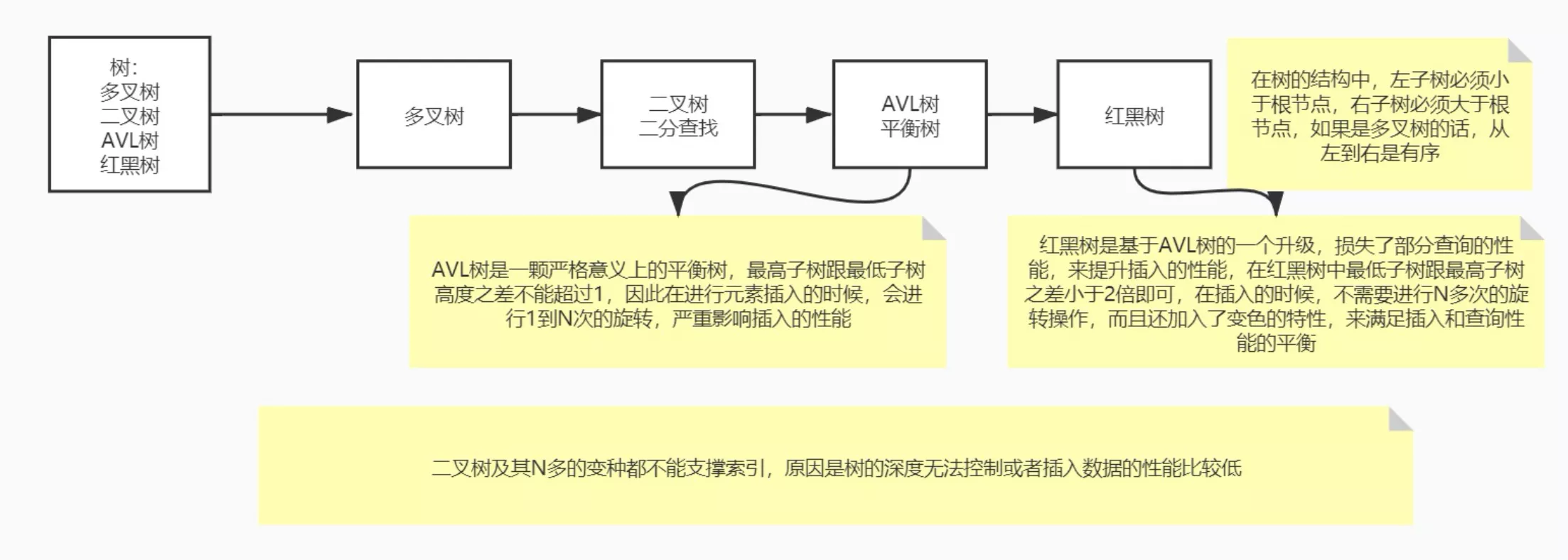
2. 二叉树
- 数据倾斜
3. BST
- 二叉搜索树(Binary_Search_Tree),又称为二叉排序树,属于树的一种,通过二叉树将数据组织起来
- 内置排序,支持二分查找
- 数据倾斜
特点:
- 左右子树也分别是二叉搜索树
- 左子树的所有节点key值都小于它的根节点的key值
- 右子树的所有节点key值都大于他的根节点的key值
- 二叉搜索树可以为一棵空树
- 一般来说,树中的每个节点的key值都不相等,但根据需要也可以将相同的key值插入树中
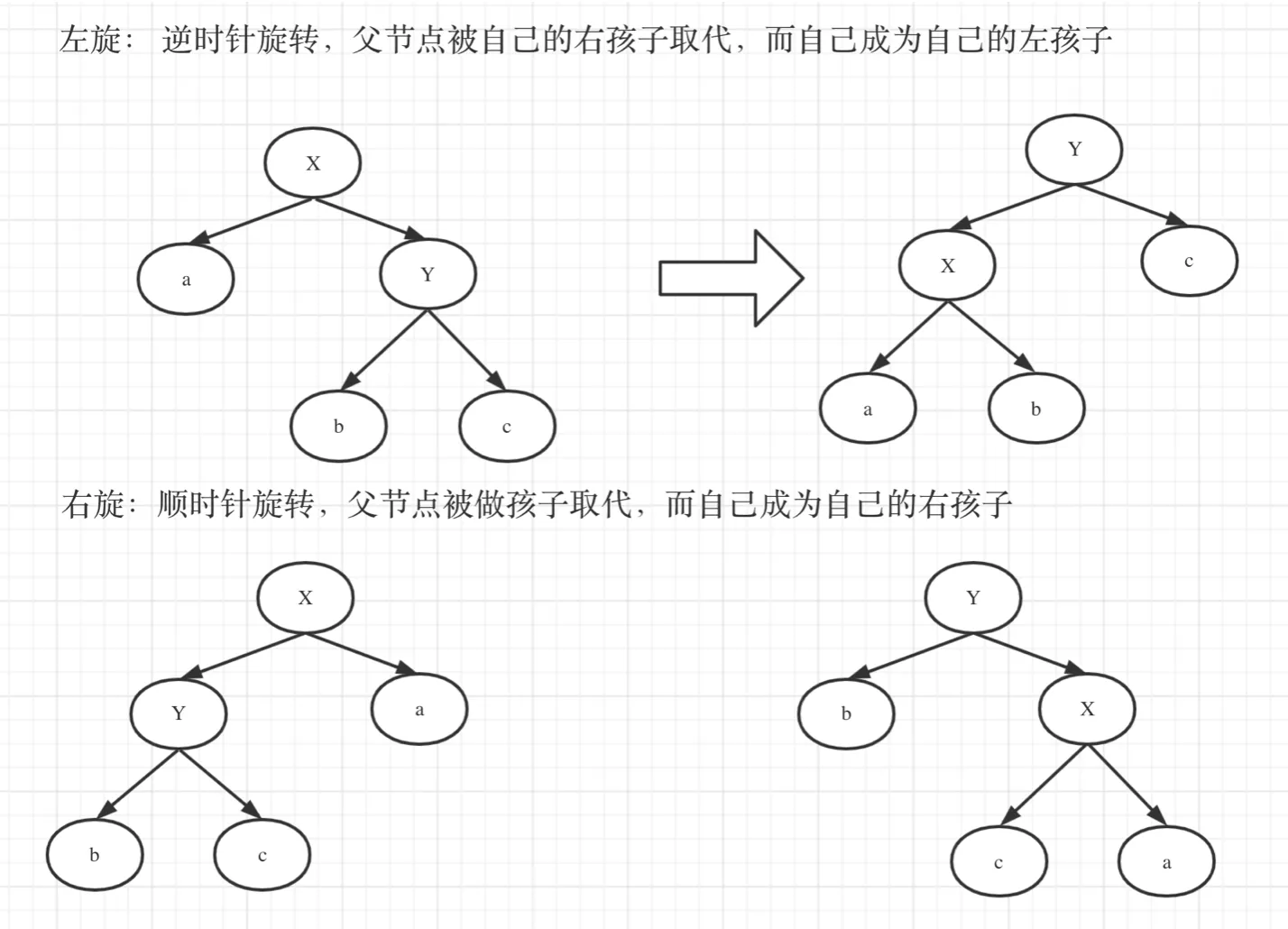
4. AVL树
- 平衡BST,AVL是其发明者姓名简写
- 通过一定机制保证AVL平衡,查询效率更高
1. 特点
- 为BST
- 左右子节点也是AVL树
- 子树高度差
<= 1,即平衡因子为范围为[-1,1] - 维持平衡:左右旋转。消耗性能,删、插慢
2. 左右旋
5. Red_Blank树
- AVL树
- 子树高度差
<= 2倍 - O(logn) 时间内做查找、插入和删除
- 相较于AVL树,牺牲了部分平衡性以换取插入、删除操作时少量的旋转操作,整体来说性能要优于AVL树
- 维持平衡:左右旋转、颜色反转
- 变化规律总结:根节点必黑,新增是红色,只能黑连黑,不能红连红; 爸叔通红就变色,爸红叔黑就旋转,哪边黑往哪边转
1. 特点
- 节点分红、黑色,用以减少旋转次数
- 根节点是黑色,每个叶子节点(NIL节点)是黑色
- 每个红色节点的两个子节点都为黑色(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
- 新插入节点默认为红色,插入后需要校验红黑树是否符合规则,不符合则需要进行平衡
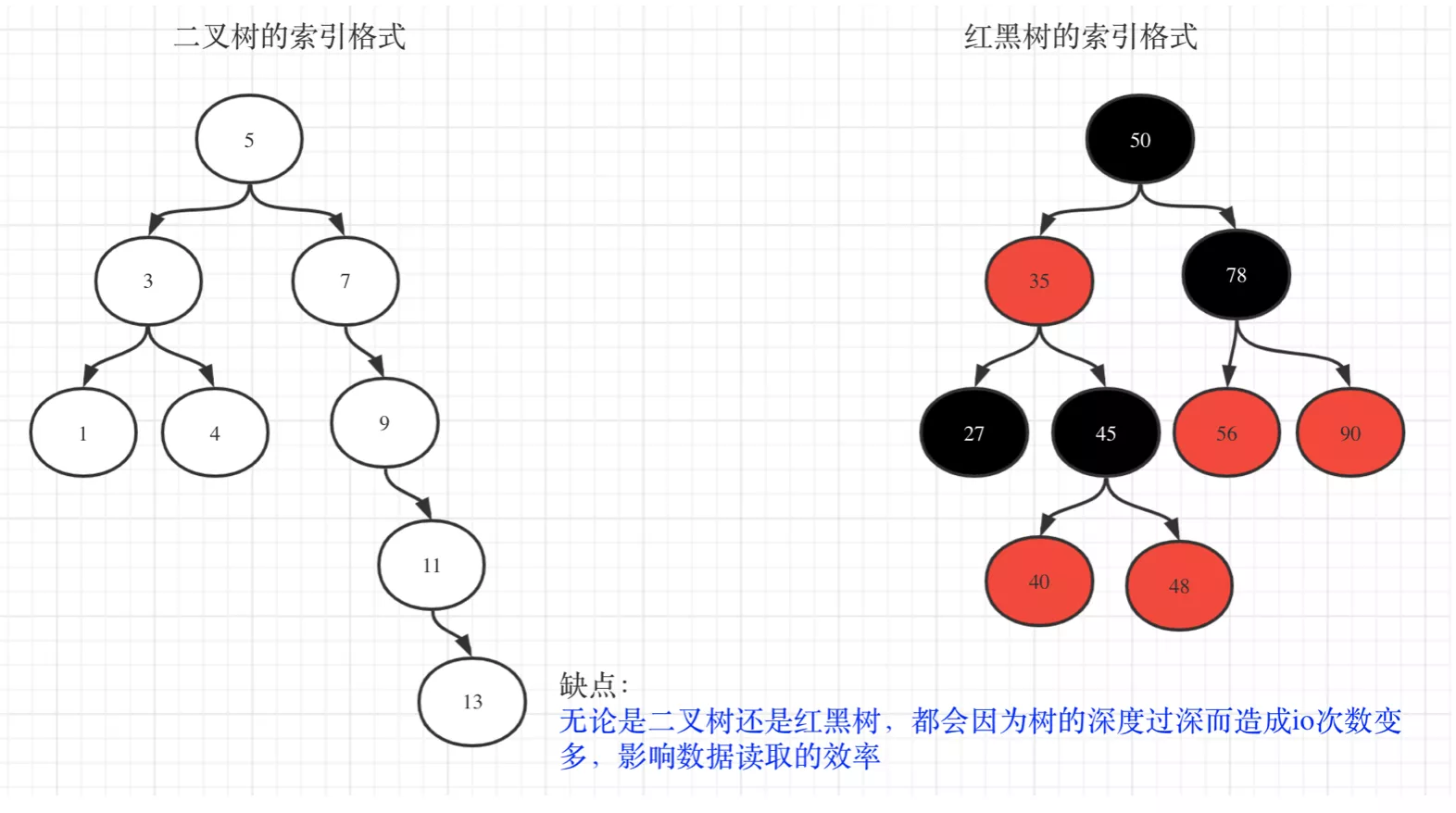
2. 缺点
无论是二叉树还是红黑树
- 深度不可控。导致IO次数变多,读取性能低
- 维持平衡。左右旋,插入、删除性能低
- 不支持index
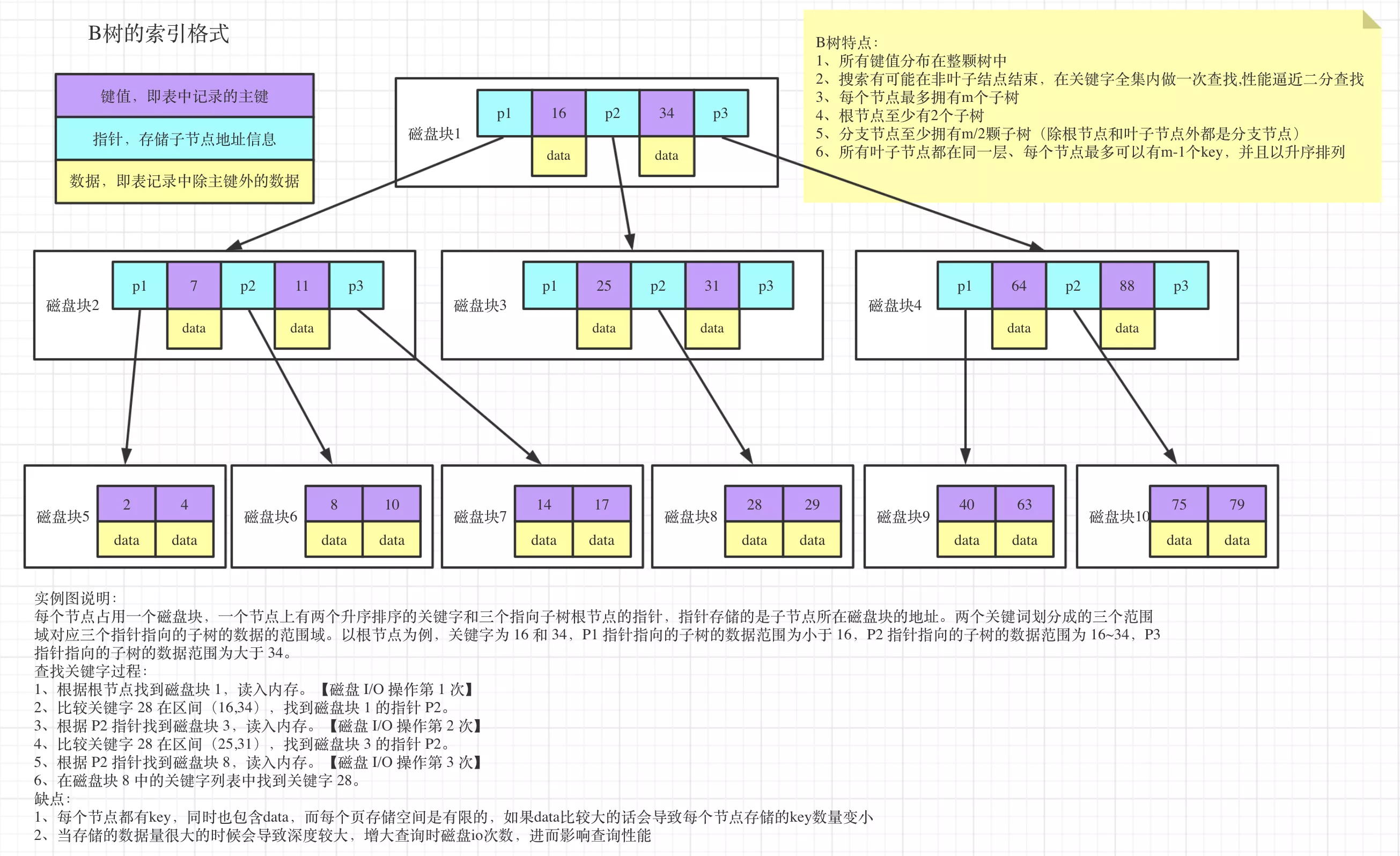
6. B树
1. 特点
- 所有键值分布在整颗树中
- 搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找
- 每个节点最多拥有m个子树
- 根节点至少有2个子树,分支节点至少拥有(m/2)颗子树(除根节点和叶子节点外都是分支节点)
- 所有叶子节点都在同一层,每个节点最多可以有(m-1)个key,并且以升序排列
2. 缺点
- 每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小
- 当存储的数据量很大的时候会导致深度较大,增大查询时磁盘IO次数,进而影响查询性能
- MySQL磁盘预读方式,按页读4K的整数倍。InnoDB,默认读取
(4页 * 4K = 16K) - eg:一条数据1K,一个磁盘块只能装16条记录,一共才能装
(16 * 16 * 16)数据
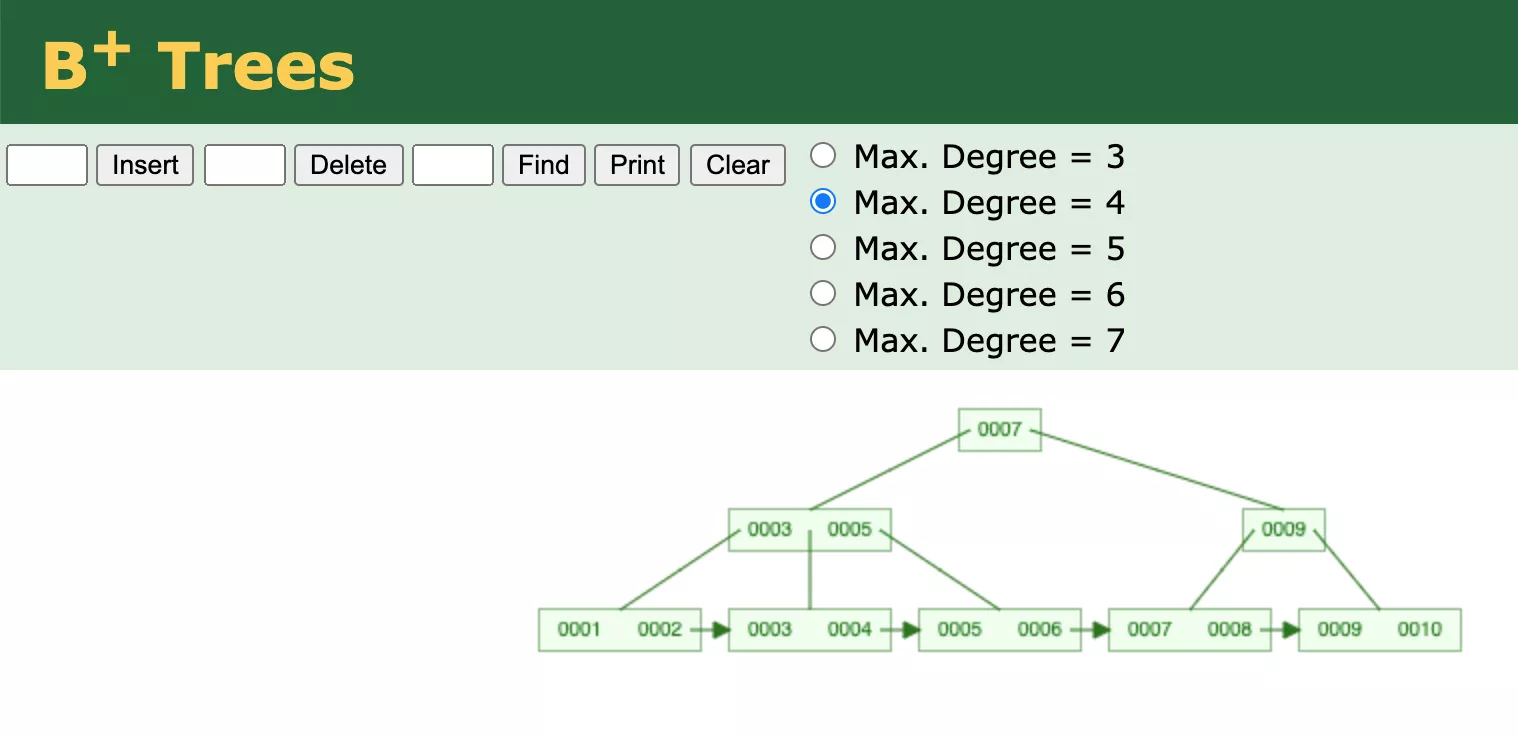
7. B+树
- B+Tree每个节点可以包含更多的节点
- 为了降低树的高度
- 将数据范围变为多个区间,区间越多,数据检索越快
- 非叶子节点存储key,叶子节点存储key+data
- 叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查找性能更高
- B+Tree有两个头指针。可以进行两种查找运算
- 一个指向根节点 => 从根节点开始,进行随机查找
- 另一个指向关键字最小的叶子节点,所有叶子节点(即数据节点)之间是一种链式环结构 => 对应主键的范围查找和分页查找

1. 存储数据量
- 默认的话,一个数据页的大小是
(4 * 4K = 16K) - 单个叶子节点(数据页)中的记录数:
(16K / 1K=16)。(假设一行记录的数据大小为1k,实际上很多互联网业务数据记录大小通常就是1K左右) - 非叶子节点
- 假设主键ID为bigint类型,长度为8B,而指针大小在InnoDB源码中为6B,这样一个判断指针为14B
- 一个数据页判断指针数为
(16K * 1024) / 14B = 1170 - 高度为2的B+Tree,能存放
(1170 * 16 = 18720)条记录。高度为3的B+树可以存放:(1170 * 1170 * 16 = 21902400)条记录
- InnoDB中B+树高度一般为1-3层,能满足千万级的数据存储
- 一次数据页的查找代表一次 IO,所以通过primary查询通常只需要1-3次 IO 操作即可查找到数据
2. why不用B*树?
- 非叶子节点间也建立了指针,非叶子节点没有数据块,所以没必要
3. Engine
- Mysql8已经没有查询缓存了
- 一个index对应一个index_tree,index_tree一般三层,四层数据量就太大了
- table尽量都有主键
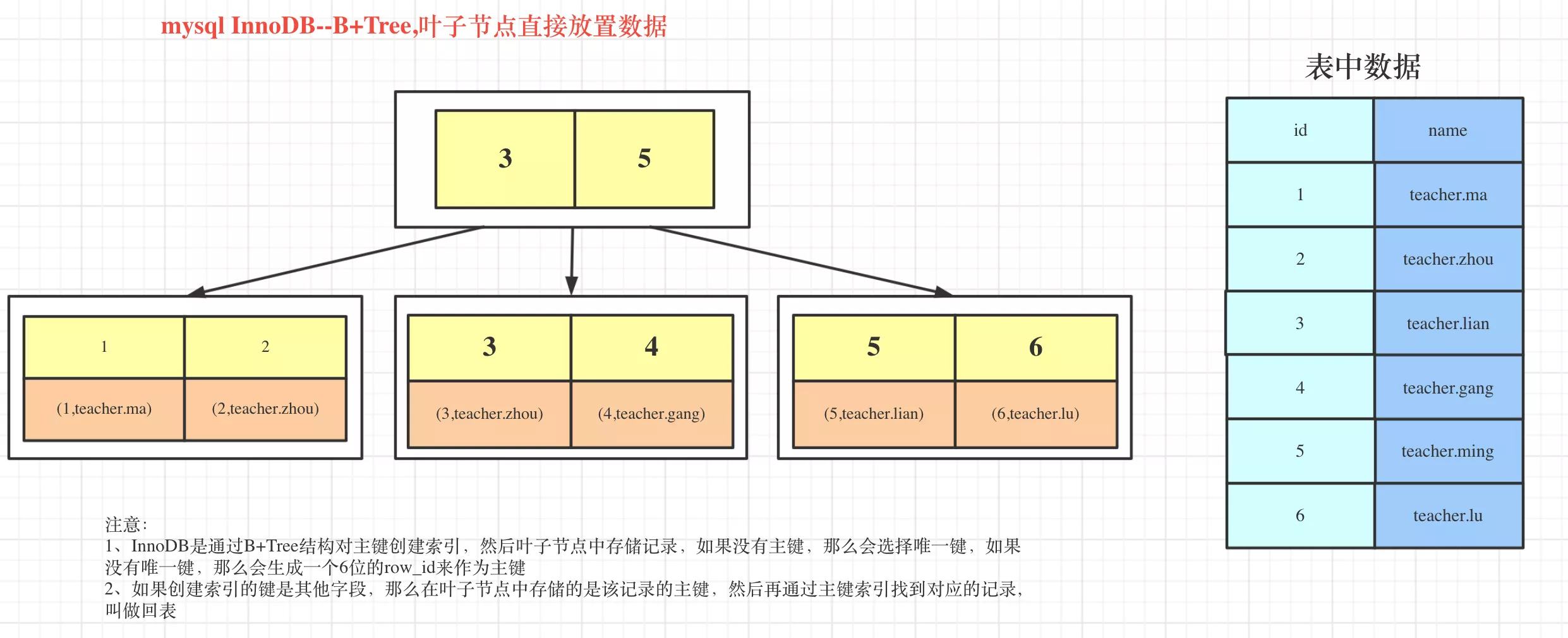
1. InnoDB
- InnoDB的数据是面向主键索引进行数据存储
- InnoDB中,B+Tree索引又可以分为聚簇索引与辅助索引
- 聚簇索引:通过primary来构造一棵B+Tree,同时叶子节点中存储的是整张表的行记录信息。数据也是索引的一部分
- 辅助索引:非主键索引。回表
- B+Tree结构对主键创建索引,然后叶子节点中存储data
- 如果没有主键,那么会选择唯一键
- 如果没有唯一键,那么会生成一个6位的row_id来作为主键
- 回表:辅助索引的叶子节点中,存储的是该row的primary,通过primary找到对应的row
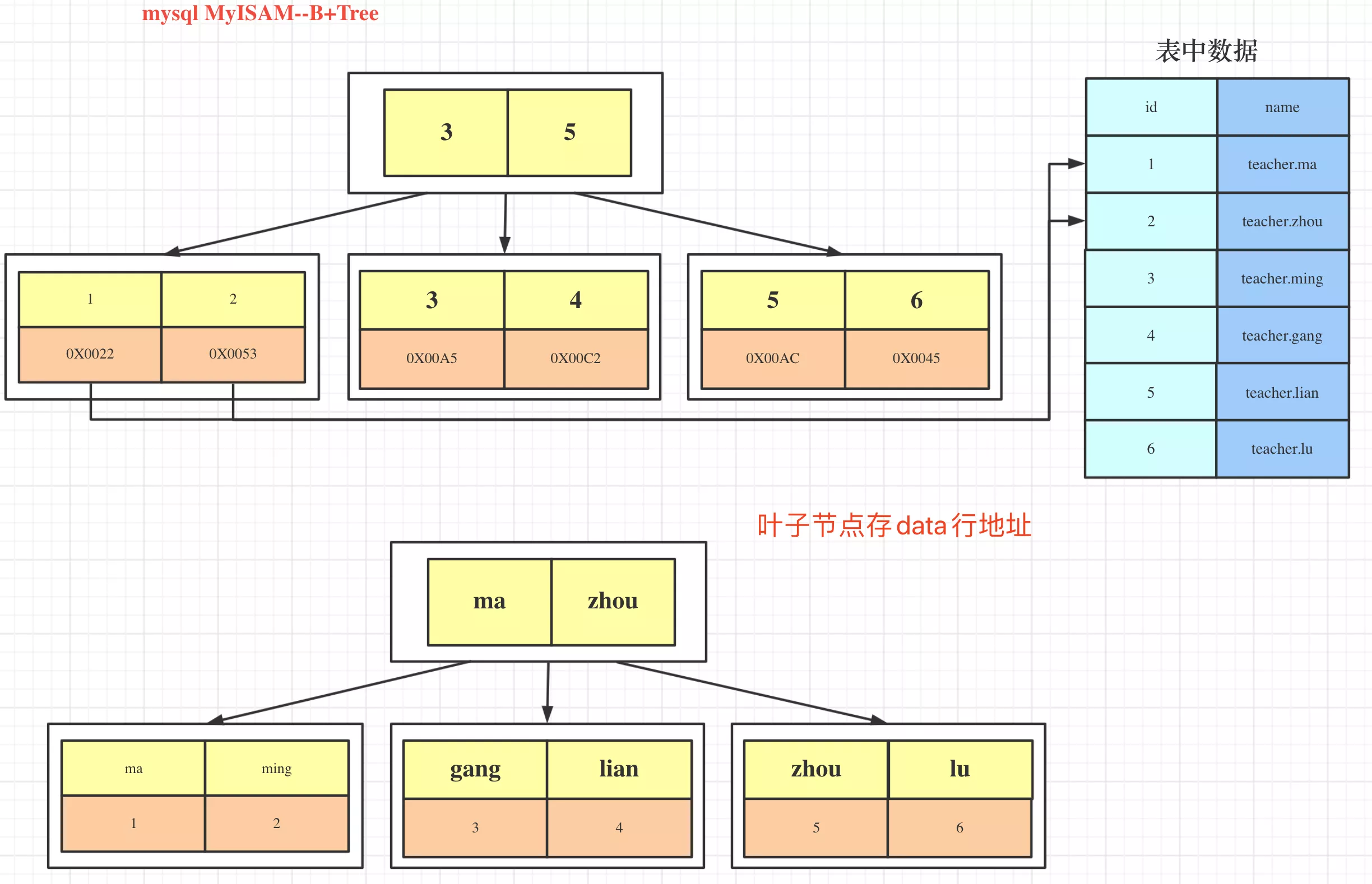
2. MyISAM
- data和index分开文件存储。primary叶子节点存一整行data的指针
- normal_index叶子节点存primary。进行回表
4. 索引
1. 优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
order by会进行全排序,index是排好序的
- 将随机IO变成顺序IO
2. 用处
- 快速查找匹配
where子句的行 - 从consideration中消除行,如果多个索引之间进行选择,Mysql通常会使用最少行的索引
- 表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
3. 分类
- 主键索引(Primary)
- 唯一索引(Unique_Index)
- 普通索引(Normal_Index)
- 组合索引(Combined_Index)
- 全文索引(Fulltext_Index)
4. Concept
- 回表:非聚簇索引,在叶子节点中存储的是该row的primary值,通过primary找到对应的row
- 覆盖索引:通过非聚簇索引查询primary时,没有回表的过程
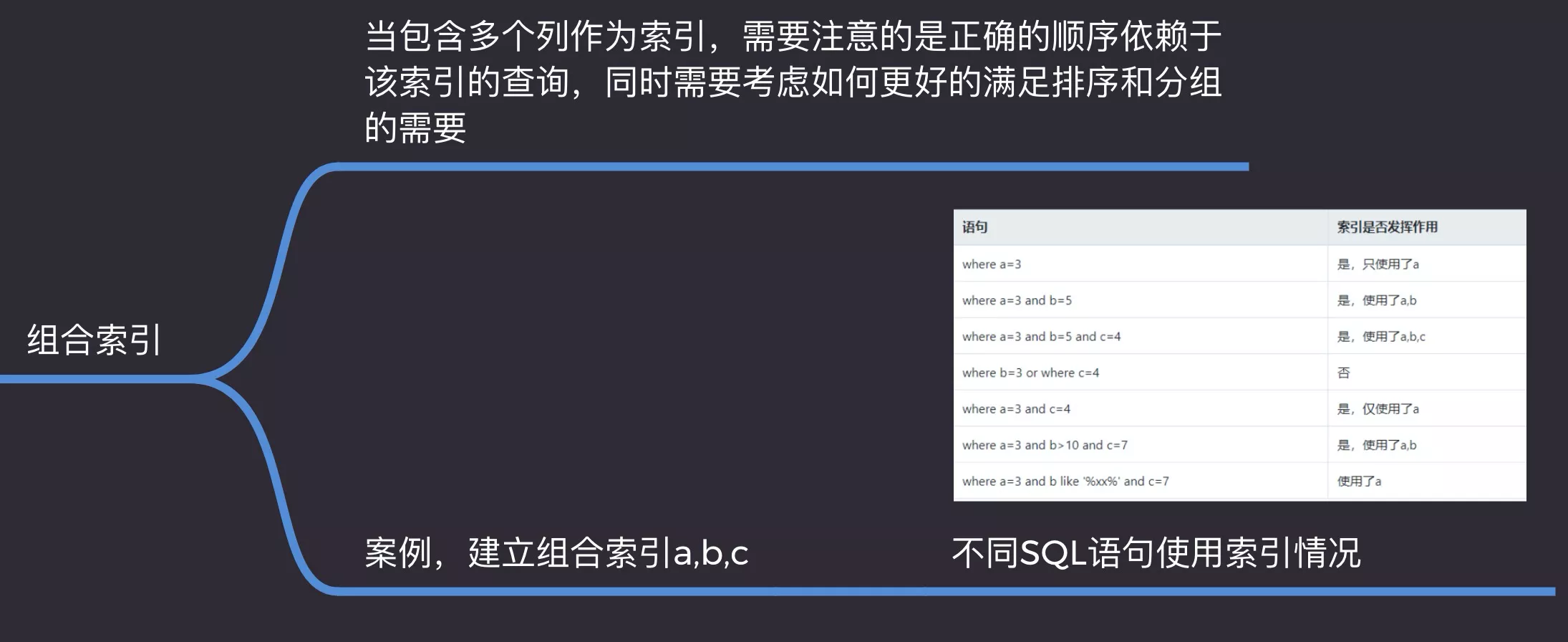
- 最左匹配
- 组合索引(name_age_index)name查询启用索引,age索引无效
- (name_age_index + age_index)优于(age_name_index + name_index),age索引更短
- age_index + name_index:涉及索引合并(了解)
- 页分裂、页合并(了解)
- 索引下推
- 组合索引(name_age_index)前提
- 在通过name取数据的时,直接把age过滤掉,减少回表次数。低版本,name过滤,再age过滤
# name_age_index
EXPLAIN SELECT * from t_user where name like '李%' and age = 22;
- 谓词下推
# 谓词下推(减少IO量)
# 把2张表(删除只剩4个字段再关联)比(先关联表再删字段)效率高
select t1.name, t2.name
from t1, t2
where t1.id = t2.id;
select count(0) from A Join B on A.id = B.id
where A.a > 10 and B.b < 100;
# 谓词下推,优化后的sql。先过滤再join
select count(0) from (select * from A where a>10) A1
Join (
select * from B where b<100
)B1 on A1.id = B1.id;
5. sakila_db
# .sql文件导入库
source /Users/listao/mca/05_mysql/sakila-db/sakila-schema.sql
6. 匹配方式
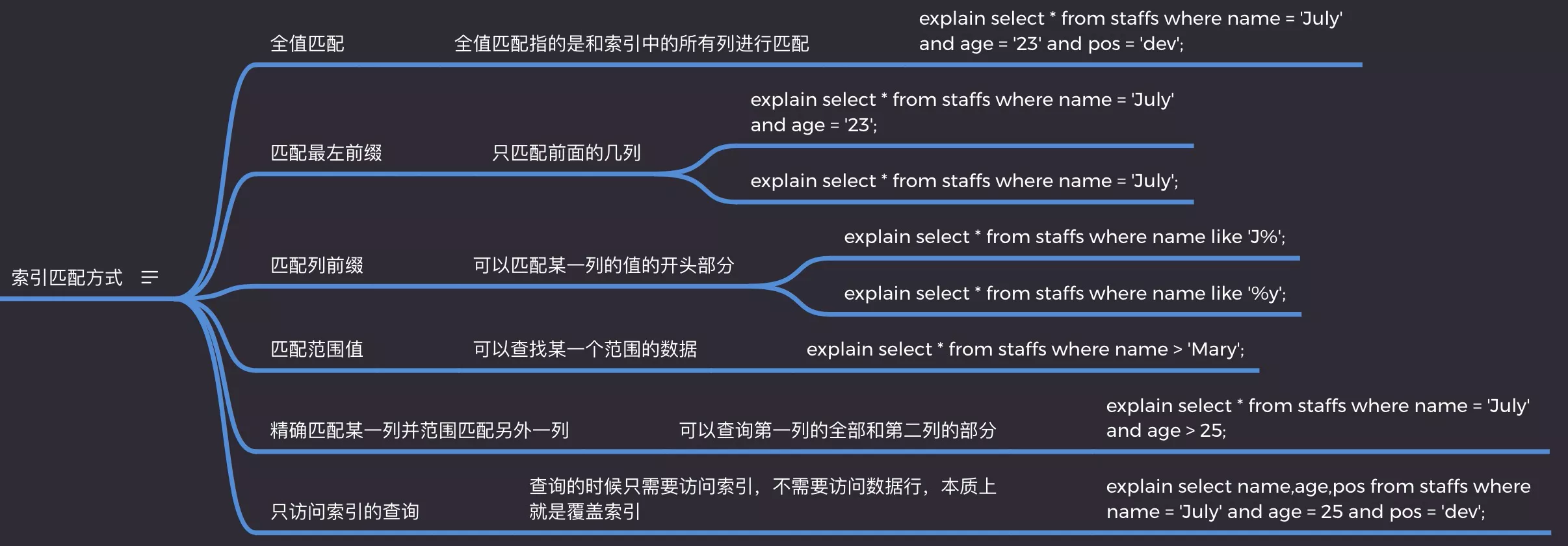
- 全值匹配
- 最左前缀
- 范围
- 等值 + 范围
- 列前缀
- 覆盖索引
create table mysql_index (
id int auto_increment primary key,
name varchar(24) default '' not null comment '姓名',
age int default 0 not null comment '年龄',
pos varchar(20) default '' not null comment '职位',
upd_time datetime default CURRENT_TIMESTAMP not null comment '入职时间'
)
comment 'mysql索引匹配表';
create index idx_nap on mysql_index (name, age, pos);
# 查看组合索引
show index from mysql_index;
# 1. 全值匹配
explain select * from mysql_index where name = 'July' and age = '23' and pos = 'dev';
+--+-----------+----+-------------+-------+-------+-----------------+-----+
|id|select_type|type|possible_keys|key |key_len|ref |Extra|
+--+-----------+----+-------------+-------+-------+-----------------+-----+
|1 |SIMPLE |ref |idx_nap |idx_nap|140 |const,const,const|NULL |
+--+-----------+----+-------------+-------+-------+-----------------+-----+
# 2. 最左前缀
explain select * from mysql_index where name = 'July' and age = '23';
+--+-----------+----+-------------+-------+-------+-----------+-----+
|id|select_type|type|possible_keys|key |key_len|ref |Extra|
+--+-----------+----+-------------+-------+-------+-----------+-----+
|1 |SIMPLE |ref |idx_nap |idx_nap|78 |const,const|NULL |
+--+-----------+----+-------------+-------+-------+-----------+-----+
# ref只有name列,没有age列
explain select * from mysql_index where name = 'July' and pos = '23';
+--+-----------+----+-------------+-------+-------+-----+---------------------+
|id|select_type|type|possible_keys|key |key_len|ref |Extra |
+--+-----------+----+-------------+-------+-------+-----+---------------------+
|1 |SIMPLE |ref |idx_nap |idx_nap|74 |const|Using index condition|
+--+-----------+----+-------------+-------+-------+-----+---------------------+
explain select * from mysql_index where name = 'July';
+--+-----------+----+-------------+-------+-------+-----+-----+
|id|select_type|type|possible_keys|key |key_len|ref |Extra|
+--+-----------+----+-------------+-------+-------+-----+-----+
|1 |SIMPLE |ref |idx_nap |idx_nap|74 |const|NULL |
+--+-----------+----+-------------+-------+-------+-----+-----+
# 3. 匹配范围值
explain select * from mysql_index where name > 'Mary';
+--+-----------+-----+-------------+-------+-------+----+---------------------+
|id|select_type|type |possible_keys|key |key_len|ref |Extra |
+--+-----------+-----+-------------+-------+-------+----+---------------------+
|1 |SIMPLE |range|idx_nap |idx_nap|74 |NULL|Using index condition|
+--+-----------+-----+-------------+-------+-------+----+---------------------+
# 4. 等值 + 范围
explain select * from mysql_index where name = 'July' and age > 25;
+--+-----------+-----+-------------+-------+-------+----+---------------------+
|id|select_type|type |possible_keys|key |key_len|ref |Extra |
+--+-----------+-----+-------------+-------+-------+----+---------------------+
|1 |SIMPLE |range|idx_nap |idx_nap|78 |NULL|Using index condition|
+--+-----------+-----+-------------+-------+-------+----+---------------------+
# 5. 匹配列前缀
explain select * from mysql_index where name like 'J%';
+--+-----------+-----+-------------+-------+-------+----+---------------------+
|id|select_type|type |possible_keys|key |key_len|ref |Extra |
+--+-----------+-----+-------------+-------+-------+----+---------------------+
|1 |SIMPLE |range|idx_nap |idx_nap|74 |NULL|Using index condition|
+--+-----------+-----+-------------+-------+-------+----+---------------------+
explain select * from mysql_index where name like '%y';
+--+-----------+----+-------------+----+-------+----+-----------+
|id|select_type|type|possible_keys|key |key_len|ref |Extra |
+--+-----------+----+-------------+----+-------+----+-----------+
|1 |SIMPLE |ALL |NULL |NULL|NULL |NULL|Using where|
+--+-----------+----+-------------+----+-------+----+-----------+
# 6. 覆盖索引
explain select name, age, pos from mysql_index where name = 'July' and age = 25 and pos = 'dev';
+--+-----------+----+-------------+-------+-------+-----------------+-----------+
|id|select_type|type|possible_keys|key |key_len|ref |Extra |
+--+-----------+----+-------------+-------+-------+-----------------+-----------+
|1 |SIMPLE |ref |idx_nap |idx_nap|140 |const,const,const|Using index|
+--+-----------+----+-------------+-------+-------+-----------------+-----------+
# *
explain select * from mysql_index where name = 'July' and age = 25 and pos = 'dev';
+--+-----------+----+-------------+-------+-------+-----------------+-----+
|id|select_type|type|possible_keys|key |key_len|ref |Extra|
+--+-----------+----+-------------+-------+-------+-----------------+-----+
|1 |SIMPLE |ref |idx_nap |idx_nap|140 |const,const,const|NULL |
+--+-----------+----+-------------+-------+-------+-----------------+-----+
5. Hash_index
- 基于哈希表实现,只有精确匹配索引所有列的查询才有效
- 只有Memory的存储引擎显式支持Hash_index
- Hash_index自身只需存储对应的hash值,所以索引的结构十分紧凑,查找的速度非常快
1. 限制
- 无Covering_index
- 数据并不是按照索引值顺序存储的,所以无法进行排序
- 不支持部分列匹配查找(最左前缀),使用索引列的全部内容来计算哈希值
- 支持等值比较查询,不支持范围查询
- 访问哈希索引的数据非常快。除非有很多哈希冲突,哈希冲突时,存储引擎必须遍历链表中的所有行指针,逐行比较,直到找到所有符合条件的行
- 哈希冲突比较多的话,维护的代价会很高
2. CRC32
# 当需要存储大量的URL,并且根据URL进行搜索查找。如果使用B+树,存储的内容就会很大
select id from url where url = "";
# 将url进行CRC32哈希,可以使用以下查询方式
select id from url where url = "" and url_crc = crc32("url");
# 此查询性能较高:使用体积很小的索引来完成查找
6. Combined_index
- 《匹配最左前缀》
7. 聚簇, 非聚簇索引
数据存储方式
- InnoDB:.ibd = 数据文件 + 索引文件
- MyISAM:.MYD数据文件;.MYI索引文件
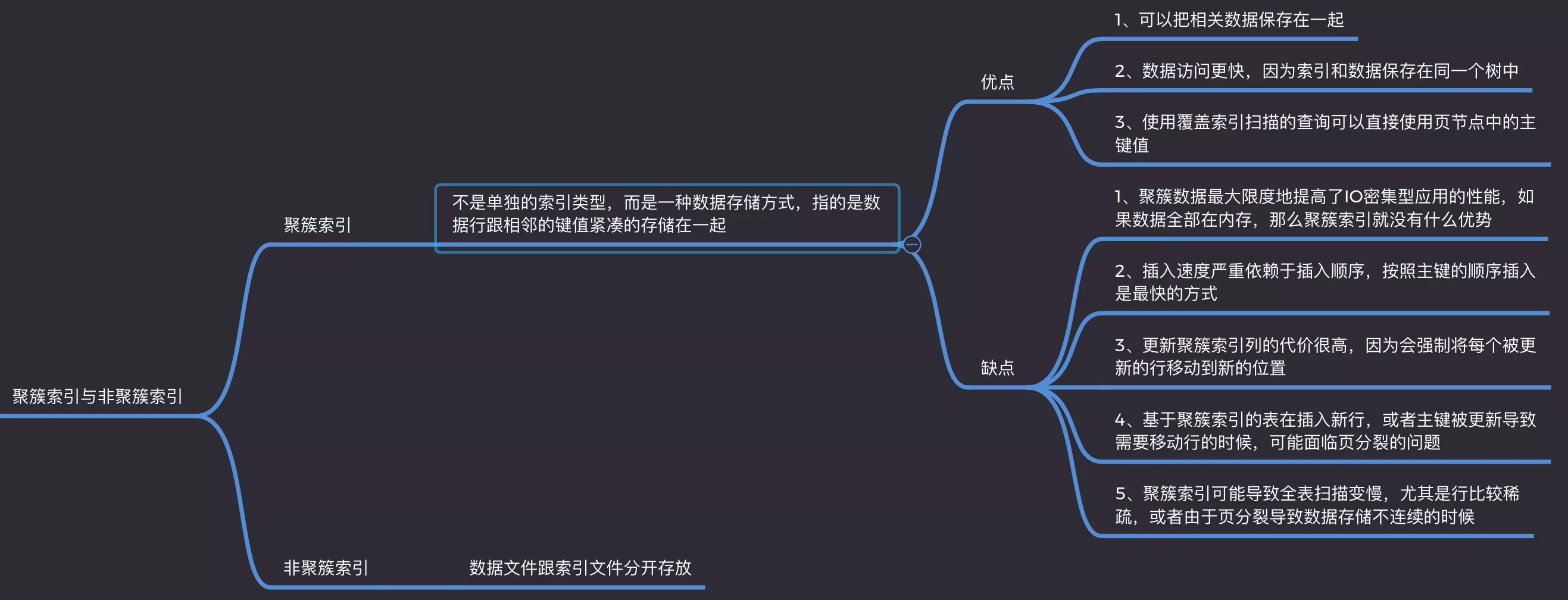
1. clustered_index
- InnoDB:index和data在一个文件里,叶子节点存row_data
- primary是clustered_index
- 非primary是non_clustered_index
- 优点:
- index和data保存在同一个树中,访问更快
- covering_index
- 缺点:
- 插入速度严重依赖插入顺序(最快primary顺序)
- 索引块大小是固定的,增、删、改代价高。涉及《页分裂》《页合并》
- 导致全表扫描变慢
- 进行数据迁移,可以先把index关掉,迁移结束了,再打开。避免index一直进行更新
2. non_clustered_index
- MyISAM:index和data不在一个文件里,叶子节点存row_data指针
8. covering_index
- index包含了要查询的数据
- InnoDB、MyISAM支持,Memory不支持
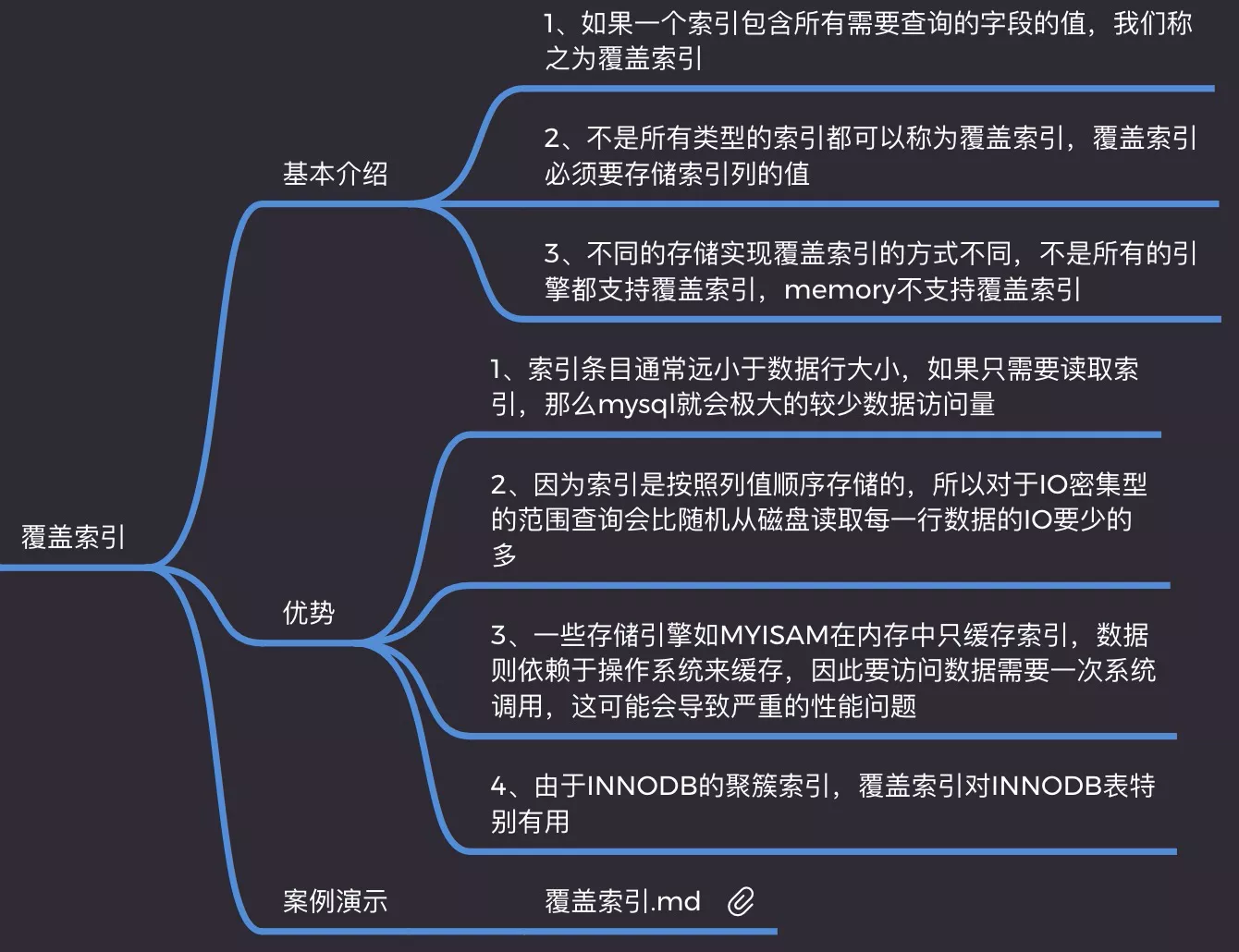
# Extra: Using index
# 二级index的叶子节点,存储primary的值
explain
select empno, deptno from emp where deptno = '10';
+--+-----------+-----+----+-------------+----------+-------+-----+-----------+
|id|select_type|table|type|possible_keys|key |key_len|ref |Extra |
+--+-----------+-----+----+-------------+----------+-------+-----+-----------+
|1 |SIMPLE |emp |ref |idx_deptno |idx_deptno|5 |const|Using index|
+--+-----------+-----+----+-------------+----------+-------+-----+-----------+
9. optimize_detail
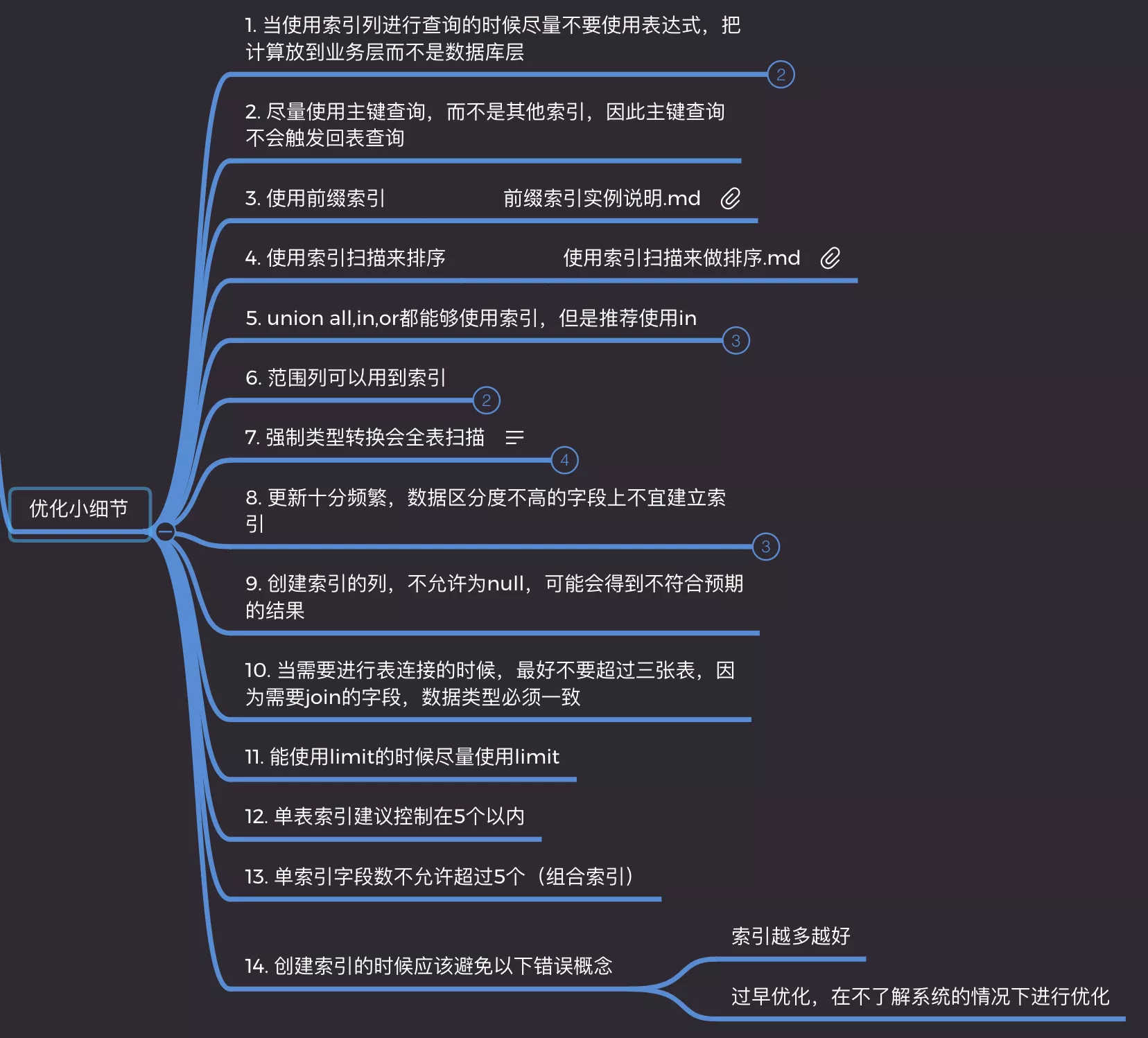
1. 不要表达式
- 使用索引列进行查询不要使用表达式,把计算放到业务层而不是数据库层
explain select *
from emp where deptno = 20;
+--+-----------+-----+----+-------------+----------+-------+-----+----+-----+
|id|select_type|table|type|possible_keys|key |key_len|ref |rows|Extra|
+--+-----------+-----+----+-------------+----------+-------+-----+----+-----+
|1 |SIMPLE |emp |ref |idx_deptno |idx_deptno|5 |const|5 |NULL |
+--+-----------+-----+----+-------------+----------+-------+-----+----+-----+
# 表达式,index失效
explain select *
from emp where deptno + 1 = 20;
+--+-----------+-----+----+-------------+----+-------+----+----+-----------+
|id|select_type|table|type|possible_keys|key |key_len|ref |rows|Extra |
+--+-----------+-----+----+-------------+----+-------+----+----+-----------+
|1 |SIMPLE |emp |ALL |NULL |NULL|NULL |NULL|14 |Using where|
+--+-----------+-----+----+-------------+----+-------+----+----+-----------+
2. 尽量使用主键
- 尽量使用主键查询,不会触发回表
3. 列前缀优化
- 很长字符串,索引变得大且慢。使用列开始的部分字符串,大大的节约索引空间,提高索引效率,降低索引的选择性
- 索引的选择性:不重复的索引值和数据表记录总数的比值,范围从(1/#T)~ 1 之间。选择性越高则查询效率越高,因为可以让Mysql过滤掉更多的行
- BLOB,TEXT,VARCHAR类型的列,必须要使用前缀索引。mysql不允许索引这些列的完整长度,要选择足够长的前缀以保证较高的选择性,又不能太长
- 无法使用前缀索引做
order by和group by
use sakila;
# 创建数据表
create table citydemo(city varchar(50) not null);
insert into citydemo(city) select city from city;
# 重复执行5次
insert into citydemo(city) select city from citydemo;
# 更新城市表的名称
# `order by rand() limit 1` 随机排序并取出一个
update citydemo set city = (select city from city order by rand() limit 1);
# 查找最常见的城市列表,发现每个值都出现45-65次
select count(1) as cnt, city from citydemo
group by city order by cnt desc limit 10;
# 查找最频繁出现的城市前缀,先从3个前缀字母开始,发现比原来出现的次数更多,可以分别截取多个字符查看城市出现的次数
select count(1) as cnt,
left(city, 3) as pref
from citydemo
group by pref order by cnt desc limit 10;
# 列前缀的选择性接近于完整列的选择性
select count(1) as cnt,
left(city, 7) as pref
from citydemo
group by pref order by cnt desc limit 10;
# 另一种方式计算列前缀选择性。当前缀长度到达7之后,再增加前缀长度,选择性提升的幅度已经很小
select count(distinct left(city, 3)) / count(*) as sel3,
count(distinct left(city, 4)) / count(*) as sel4,
count(distinct left(city, 5)) / count(*) as sel5,
count(distinct left(city, 6)) / count(*) as sel6,
count(distinct left(city, 7)) / count(*) as sel7,
count(distinct left(city, 8)) / count(*) as sel8,
count(distinct left(city, 9)) / count(*) as sel9,
count(distinct left(city, 10)) / count(*) as sel10,
count(distinct left(city, 11)) / count(*) as sel11,
count(distinct left(city, 12)) / count(*) as sel12,
count(distinct left(city, 13)) / count(*) as sel13,
count(distinct left(city, 14)) / count(*) as sel14
from citydemo;
# 通过city列前7个字符创建索引
alter table citydemo add key(city(7));
show index from citydemo;
+----------+--------+------------+-----------+---------+-----------+--------+------+----+----------+
|Non_unique|Key_name|Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|
+----------+--------+------------+-----------+---------+-----------+--------+------+----+----------+
|1 |city |1 |city |A |596 |7 |NULL | |BTREE |
+----------+--------+------------+-----------+---------+-----------+--------+------+----+----------+
# 和Cardinality大体一致 => 599
select count(distinct city) from citydemo;
Cardinality:基数。该列的唯一值有多少个
- 如果唯一值多,索引的检索就效率越高
- 如果唯一值越少,效率越低。重复的值越多,那么索引匹配的时候就会有更多的重复数据,这个是不利于索引的检索的
- hyperloglog去重算法,kylin也用到了,底层的思想都是一样的 —— 计算统计
- 探索HyperLogLog算法(含Java实现)
4. order by
explain Extra列
- 有《Using filesort》文件排序
- 没有《Using filesort》index_scan
1. sort_buffer
- 每个查询线程分配一块小内存,用于排序,称为sort_buffer
# 256KB
show variables like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
临时文件排序(归并排序)
sort_buffer装不下
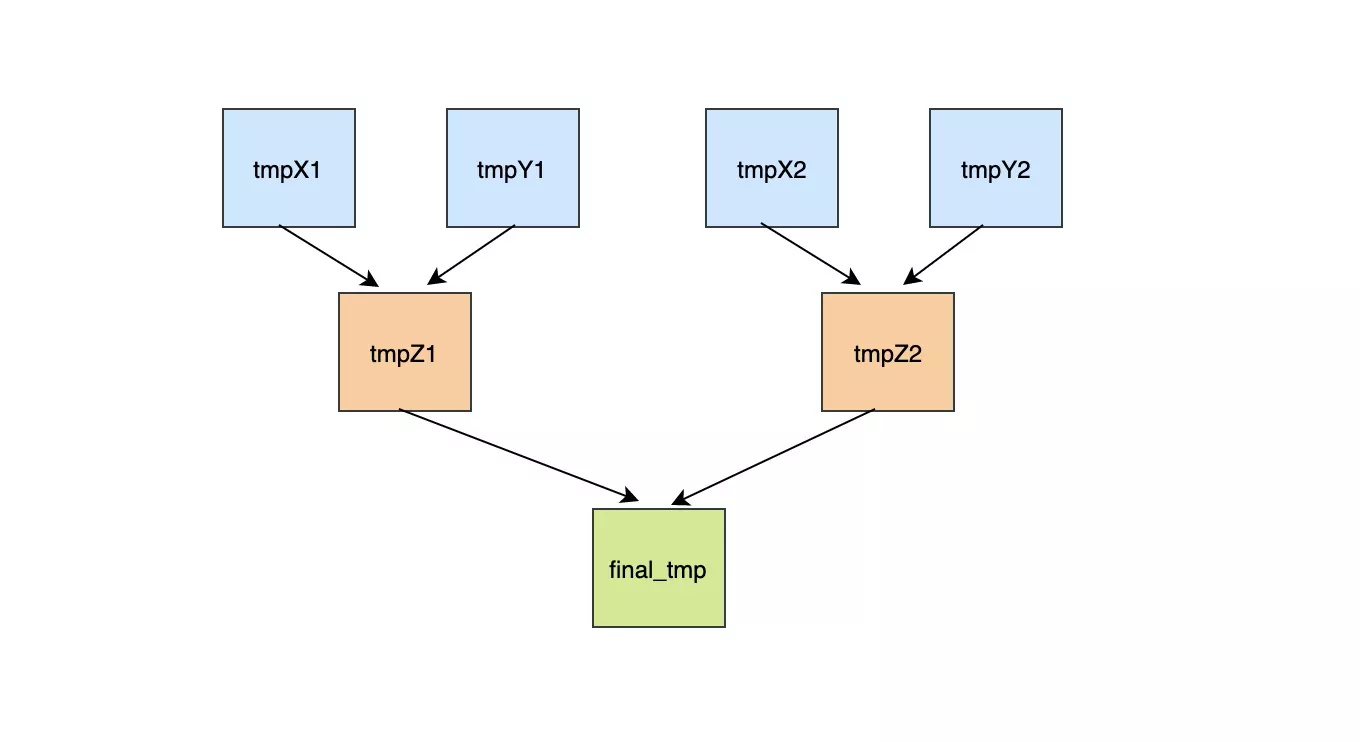
2. 全字段排序
一次回表:普通索引where过滤行。回表取行全字段,放到sort_buffer进行排序
- 优点
- 只需要一次回表读取数据,而减少随机IO
- 缺点
- 查询列特别多的时候,分多次sort_buffer,再进行归并排序
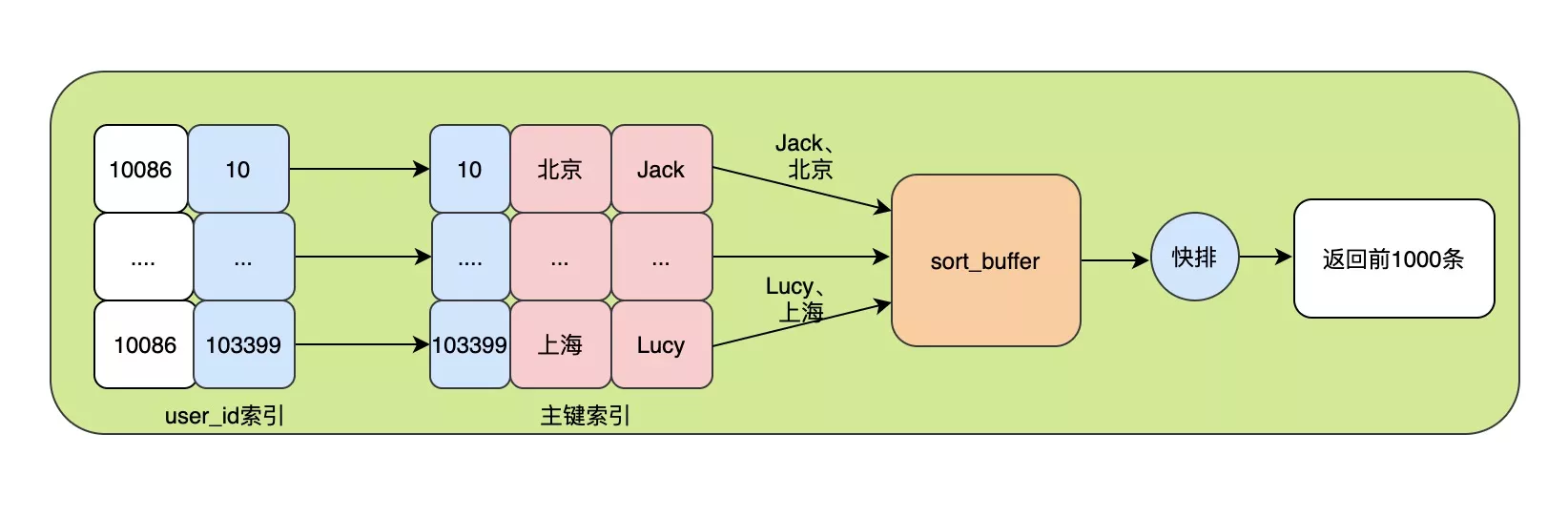
3. rowId排序
- 两次回表:普通索引where过滤行。回表取行(rowId + order by)字段,放到sort_buffer进行排序,再回表
- combined_index取消了第一次回表操作,如果是covering_index,第二次回表也取消了
# 排序的列的总大小超过`max_length_for_sort_data`定义byte,选择rowId排序,反之使用全字段排序
show variables like 'max_length_for_sort_data';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| max_length_for_sort_data | 1024 |
+--------------------------+-------+
- 优点
- sort_buffer尽可能多的容纳行数来进行排序操作
- 缺点
- 效率低,第二次回表需要更多的随机IO
4. index_scan, filesort
- 两种方式排序
- filesort(文件排序)Extra 有 Using filesort
- full_table_scan(table_data):全表扫描
- index_scan(索引扫描)Extra 没有 Using filesort
- full_index_scan(index_tree):索引扫描
- filesort(文件排序)Extra 有 Using filesort
- 查询需要关联多张表,当
order by子句引用的字段全部为第一张表时,才能使用索引做排序 - (where + order by)=>《最左前缀》
- 没有where
- 默认filesort,mysql优化器认为普通二级索引,回表成本比全表扫描排序更高
- index_scan比filesort慢:不能covering_index,就回表,随机IO
- 表数据量大时
limit n,会进行index_scan。有限次的回表成本 << table_scan
# 《name, age, address》联合索引
create table mysql_orderBy (
id varchar(36) not null primary key,
name varchar(50) null,
age int null,
address varchar(255) null,
upd_time datetime null
)
comment 'mysql_orderBy表';
create index idx_naa on mysql_orderBy (name, age, address);
# ------------------------------- covering_index ----------------------------------
# 1. 使用covering_index,必经过index_tree,type至少index,不会回表
# type: ref; Extra: Using index
explain select id, name, age from mysql_orderBy where name = '';
# type: index; Extra: Using where; Using index
explain select id, name, age from mysql_orderBy where age = '';
# type: index; Extra: Using index
explain select id, name, age from mysql_orderBy order by name, age;
# type: index; Extra: Using index
explain select id, name, age from mysql_orderBy order by name;
# type: index; Extra: Using index; Using filesort
explain select id, name, age from mysql_orderBy order by age;
# type: ref; Extra: Using where; Using index
explain select id, name, age from mysql_orderBy where name = '' order by name, age;
# type: ref; Extra: Using index
explain select id, name, age from mysql_orderBy where name = '' order by name;
# (where + order by)==>《最左前缀》
# type: ref; Extra: Using where; Using index
explain select id, name, age from mysql_orderBy where name = '' order by age;
# type: index; Extra: Using where; Using index; Using filesort
explain select id, name, age from mysql_orderBy where age = '' order by name, age;
# type: index; Extra: Using where; Using index(name应用了index)
explain select id, name, age from mysql_orderBy where age = '' order by name;
# type: index; Extra: Using where; Using index; Using filesort
explain select id, name, age from mysql_orderBy where age = '' order by age;
# ------------------------------- 全字段查询 ------------------------------------
# 2. 必经过table_data,经过index_tree的,需要回表
# type: ref; Extra: null
explain select * from mysql_orderBy where name = '';
# type: ALL; Extra: Using where
explain select * from mysql_orderBy where age = '';
# 单纯的`order by`并不使用index,filesort比index_scan性能高
# type: ALL; Extra: Using filesort
explain select * from mysql_orderBy order by name, age;
# 强制使用index
explain select * from mysql_orderBy force index(idx_naa) order by name, age;
+--+-----------+-------------+-----+-------------+-------+-------+----+----+--------+-----+
|id|select_type|table |type |possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-------------+-----+-------------+-------+-------+----+----+--------+-----+
|1 |SIMPLE |mysql_orderBy|index|NULL |idx_naa|1231 |NULL|1 |100 |NULL |
+--+-----------+-------------+-----+-------------+-------+-------+----+----+--------+-----+
# type: ALL; Extra: Using filesort
explain select * from mysql_orderBy order by name;
# type: ALL; Extra: Using filesort
explain select * from mysql_orderBy order by age;
# type: ref; Extra: Using index condition
explain select * from mysql_orderBy where name = '' order by name, age;
# type: ref; Extra: null
explain select * from mysql_orderBy where name = '' order by name;
# type: ref; Extra: Using index condition(最左前缀)
explain select * from mysql_orderBy where name = '' order by age, address;
# 1. desc asc,filesort
# type: ref; Extra: Using index condition; Using filesort
explain select * from mysql_orderBy where name = '' order by age desc, address;
# type: ref; Extra: Using where
explain select * from mysql_orderBy where name = '' order by age desc;
# type: range; Extra: Using index condition
explain select * from mysql_orderBy where name > '' order by name, age ;
# 2. order by不再索引中的列,filesort
# type: ref; Extra: Using index condition; Using filesort
explain select * from mysql_orderBy where name = '' order by age, upd_time;
# type: ALL; Extra: Using where; Using filesort
explain select * from mysql_orderBy where age = '' order by name, age;
# type: ALL; Extra: Using where; Using filesort
explain select * from mysql_orderBy where age = '' order by name;
# type: ALL; Extra: Using where; Using filesort
explain select * from mysql_orderBy where age = '' order by age;
5. Extra
# 1. Using index
# 使用covering_index,不回表
explain select id, name, age from mysql_orderBy;
# 2. Using where; Using index
explain select id, name, age from mysql_orderBy where age > '';
# 3. Using where
# 回表(使用index)
explain select id, address from mysql_orderBy where id > '';
# 不回表(没用index)不进行index_scan,直接table_scan
explain select id from mysql_orderBy where address > '';
# 4. Using index condition
# 首先index_scan,然后Using index condition,最后回表
explain select * from mysql_orderBy where name = '1';
5. union all, in, or
union all代替union。union会去重,会创建临时表Using temporary。影响性能union all,in,or都能够使用index,推荐使用in
explain
select * from mysql_standard ms1 where id = '1'
union
select * from mysql_standard ms2 where id = '2';
+----+------------+----------+-----+-------------+-------+-------+-----+----+--------+---------------+
|id |select_type |table |type |possible_keys|key |key_len|ref |rows|filtered|Extra |
+----+------------+----------+-----+-------------+-------+-------+-----+----+--------+---------------+
|1 |PRIMARY |ms1 |const|PRIMARY |PRIMARY|146 |const|1 |100 |NULL |
|2 |UNION |ms2 |const|PRIMARY |PRIMARY|146 |const|1 |100 |NULL |
|NULL|UNION RESULT|<union1,2>|ALL |NULL |NULL |NULL |NULL |NULL|NULL |Using temporary|
+----+------------+----------+-----+-------------+-------+-------+-----+----+--------+---------------+
explain
select * from mysql_standard ms1 where id = '1'
union all
select * from mysql_standard ms2 where id = '2';
+--+-----------+-----+-----+-------------+-------+-------+-----+----+--------+-----+
|id|select_type|table|type |possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-----+-----+-------------+-------+-------+-----+----+--------+-----+
|1 |PRIMARY |ms1 |const|PRIMARY |PRIMARY|146 |const|1 |100 |NULL |
|2 |UNION |ms2 |const|PRIMARY |PRIMARY|146 |const|1 |100 |NULL |
+--+-----------+-----+-----+-------------+-------+-------+-----+----+--------+-----+
explain
select * from mysql_standard ms where id in ('1', '2');
+--+-----------+-----+-----+-------------+-------+-------+----+----+--------+-----------+
|id|select_type|table|type |possible_keys|key |key_len|ref |rows|filtered|Extra |
+--+-----------+-----+-----+-------------+-------+-------+----+----+--------+-----------+
|1 |SIMPLE |ms |range|PRIMARY |PRIMARY|146 |NULL|2 |100 |Using where|
+--+-----------+-----+-----+-------------+-------+-------+----+----+--------+-----------+
explain
select * from mysql_standard ms where id = '1' or id = '2';
+--+-----------+-----+-----+-------------+-------+-------+----+----+--------+-----------+
|id|select_type|table|type |possible_keys|key |key_len|ref |rows|filtered|Extra |
+--+-----------+-----+-----+-------------+-------+-------+----+----+--------+-----------+
|1 |SIMPLE |ms |range|PRIMARY |PRIMARY|146 |NULL|2 |100 |Using where|
+--+-----------+-----+-----+-------------+-------+-------+----+----+--------+-----------+
1. exists
- 子查询有结果外层即可显示
- 查询结果不能出现子查询的字段
- 效率很高比
in()都高
# exists相当于外层for(),子查询只要有结果外层即可显示
# 所以会查询出外层的全部
explain
select * from emp
where exists(select deptno from dept where deptno = 20 or deptno = 30);
+--+-----------+-----+-----+-------+-------+----+----+--------+------------------------+
|id|select_type|table|type |key |key_len|ref |rows|filtered|Extra |
+--+-----------+-----+-----+-------+-------+----+----+--------+------------------------+
|1 |PRIMARY |emp |ALL |NULL |NULL |NULL|14 |100 |NULL |
|2 |SUBQUERY |dept |index|PRIMARY|4 |NULL|4 |50 |Using where; Using index|
+--+-----------+-----+-----+-------+-------+----+----+--------+------------------------+
# 优先级:and > or
explain
select * from emp e
where exists(select deptno from dept d where (deptno = 20 or deptno = 30) and e.deptno = d.deptno);
+--+------------------+-----+------+-------+-------+------------+----+--------+------------------------+
|id|select_type |table|type |key |key_len|ref |rows|filtered|Extra |
+--+------------------+-----+------+-------+-------+------------+----+--------+------------------------+
|1 |PRIMARY |e |ALL |NULL |NULL |NULL |14 |100 |Using where |
|2 |DEPENDENT SUBQUERY|d |eq_ref|PRIMARY|4 |mca.e.deptno|1 |100 |Using where; Using index|
+--+------------------+-----+------+-------+-------+------------+----+--------+------------------------+
6. 范围列索引
- index最多用于一个范围列

# > >= < <= between,使用index
explain select * from t_temp where name >= '';
# age不使用index
explain select * from t_temp where name >= '' and age = '';
7. 不要类型转换
- java.int = BD.varchar(index失效)
- java.String = BD.int(index有效)
# 1. java.String = BD.int(index有效)
explain
select * from mysql_index where id = '1';
+--+-----------+-----------+-----+-------------+-------+-------+-----+----+--------+-----+
|id|select_type|table |type |possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-----------+-----+-------------+-------+-------+-----+----+--------+-----+
|1 |SIMPLE |mysql_index|const|PRIMARY |PRIMARY|4 |const|1 |100 |NULL |
+--+-----------+-----------+-----+-------------+-------+-------+-----+----+--------+-----+
# 2. java.int = BD.varchar(index失效)
explain
select * from mysql_index where name = 1;
+--+-----------+-----------+----+-------------+----+-------+----+----+--------+-----------+
|id|select_type|table |type|possible_keys|key |key_len|ref |rows|filtered|Extra |
+--+-----------+-----------+----+-------------+----+-------+----+----+--------+-----------+
|1 |SIMPLE |mysql_index|ALL |idx_nap |NULL|NULL |NULL|1 |100 |Using where|
+--+-----------+-----------+----+-------------+----+-------+----+----+--------+-----------+
8. 更新频繁,区分度小
- upd频繁不建
- 更新会变更B+树,更新频繁的字段建立index会大大降低数据库性能
- 区分度小不建
- 类似于性别这类区分不大的属性,建立index是没有意义的,不能有效的过滤数据,
- 一般区分度在80%以上的时候就建立index,区分度可以使用
count(distinct(列名)) / count(*)来计算
9. index不为null
- 创建index列,不允许为null,可能得到不合预期的结果,null自己都不等于null
10. join < 3, 类型一致
- join官网——算法
- join官网——优化
- 小表(10)join大表(1000),效率高。大表匹配到了就结束loop,小表下一个,减少开销
# straight_join左表始终在右表前读取
select * from emp e straight_join dept d on e.deptno = d.deptno;
# 256K
show variables like '%join_buffer%';
# 以下两个sql等价
select * from emp e join dept d on e.deptno = d.deptno;
select * from emp e inner join dept d on e.deptno = d.deptno;
1. on, where
# 1. 内接连,一样
explain
select * from emp e inner join dept d on d.deptno = e.deptno and e.deptno = 20;
+--+-----------+-----+-----+-------------+----------+-------+-----+----+--------+-----+
|id|select_type|table|type |possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-----+-----+-------------+----------+-------+-----+----+--------+-----+
|1 |SIMPLE |d |const|PRIMARY |PRIMARY |4 |const|1 |100 |NULL |
|1 |SIMPLE |e |ref |idx_deptno |idx_deptno|5 |const|5 |100 |NULL |
+--+-----------+-----+-----+-------------+----------+-------+-----+----+--------+-----+
explain
select * from emp e inner join dept d on d.deptno = e.deptno where e.deptno = 20;
+--+-----------+-----+-----+-------------+----------+-------+-----+----+--------+-----+
|id|select_type|table|type |possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-----+-----+-------------+----------+-------+-----+----+--------+-----+
|1 |SIMPLE |d |const|PRIMARY |PRIMARY |4 |const|1 |100 |NULL |
|1 |SIMPLE |e |ref |idx_deptno |idx_deptno|5 |const|5 |100 |NULL |
+--+-----------+-----+-----+-------------+----------+-------+-----+----+--------+-----+
# 2. left join:会显示左表的全部数据
# and:条件对右表进行限制
# where:对join的结果集进行过滤
select * from emp e left join dept d on e.deptno = d.deptno and e.deptno = 20;
select * from emp e left join dept d on e.deptno = d.deptno where e.deptno = 20;
select * from emp e join dept d on 1 != 1;
select * from emp e left join dept d on 1 != 1;
11. limit提高效率
- 能使用limit,尽量使用
- limit不应该叫分页,应该要限制输出
12. 单表索引 <= 5
- 增加IO
13. 组合索引字段 <= 5
- Combined_index
14. 错误概念
- index越多越好
- 过早优化。在不了解系统的情况下进行优化
10. index_monitor

# Handler_read_key、Handler_read_rnd_next:越大越好,意味着index生效
show status like 'Handler_read%';
+---------------------+-----+
|Variable_name |Value|
+---------------------+-----+
|Handler_read_first |4 | -- 读取索引第一个条目的次数
|Handler_read_key |10 | -- 1. 通过index获取数据的次数
|Handler_read_last |0 | -- 读取索引最后一个条目的次数
|Handler_read_next |5 | -- 通过索引读取下一条数据的次数
|Handler_read_prev |0 | -- 通过索引读取上一条数据的次数
|Handler_read_rnd |0 | -- 从固定位置读取数据的次数
|Handler_read_rnd_next|1079 | -- 2. 从数据节点读取下一条数据的次数
+---------------------+-----+