07-Execution_Engine
1. Execution Engine
执行引擎属于JVM底层,包括
- 解释器
- 及时编译器
- 垃圾回收器
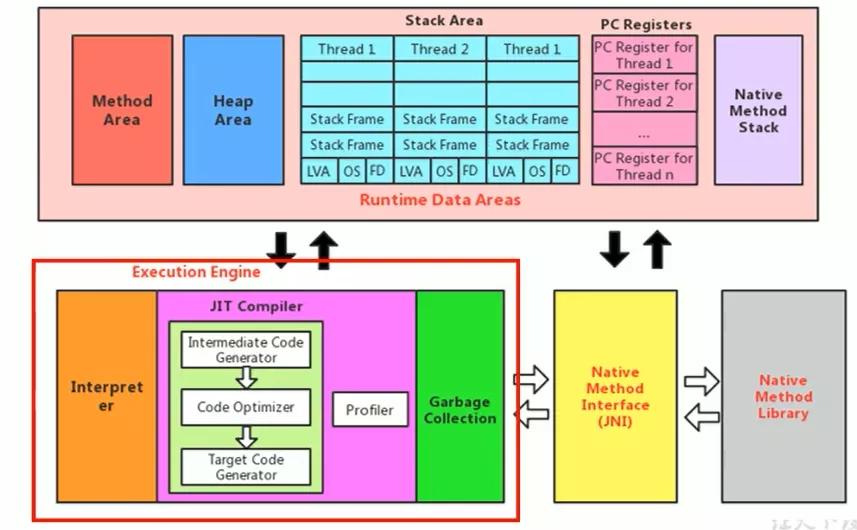
- “虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,区别
- 物理机的执行引擎是直接建立在CPU、缓存、指令集和OS层面上
- 虚拟机的执行引擎则是由软件自行实现的,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,能够执行那些不被硬件直接支持的指令集格式
- JVM主要任务是负责装载字节码到其内部,但字节码并不能够直接运行在OS之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表,以及其他辅助信息
- 执行引擎(Execution Engine):将字节码指令解释/编译为对应平台上的本地机器指令。执行引擎充当翻译家(高级语言翻译为机器语言)
2. 工作流程
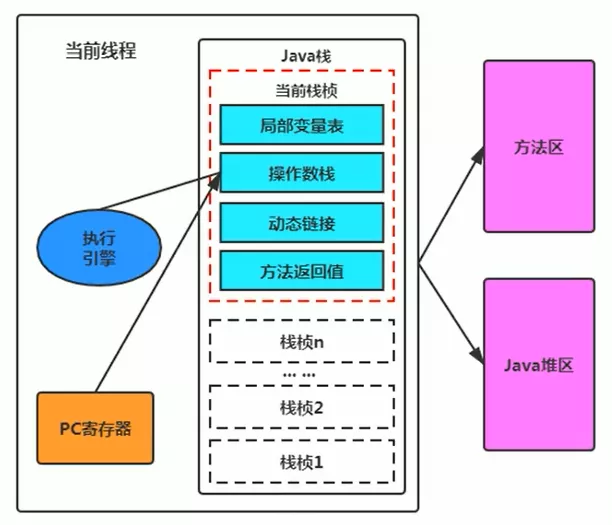
- 执行引擎执行的字节码指令完全依赖于PC,执行完一项指令后,PC就会更新下一条需要被执行的指令地址
- 方法在执行过程中,执行引擎有可能会通过存储在局部变量表中的Obj引用,准确定位到存储在Heap中的Obj实例信息,以及通过Obj头中的元数据指针定位到MethodArea目标Obj的类型信息
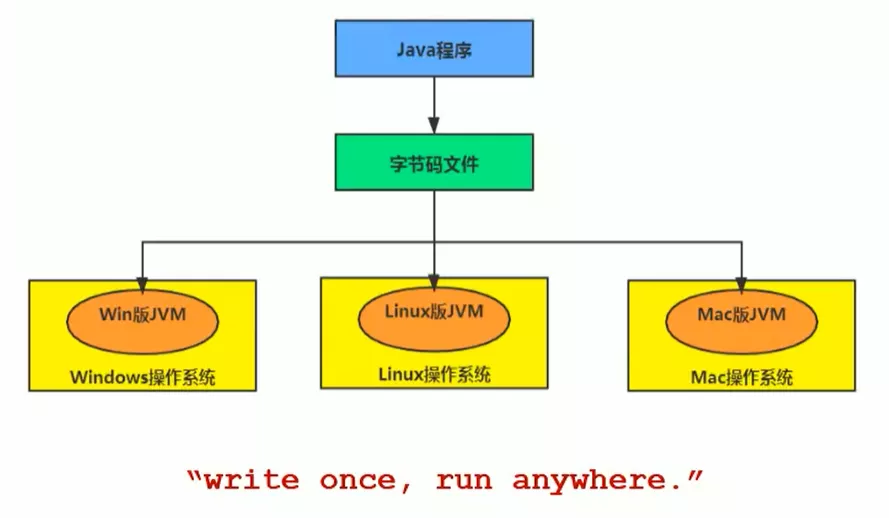
- 从外观上来看,所有的JVM的执行引擎输入、输出都是一致的。输入的是字节码二进制流,处理过程是字节码解析执行的等效过程,输出的是执行过程
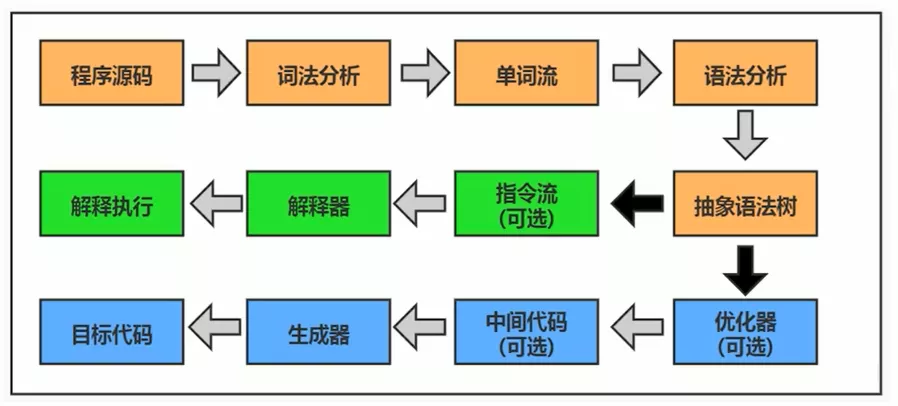
3. 代码编译、执行过程
大部分的程序代码转换成JVM能执行的指令集或物理机的目标代码之前,都需要经过下图步骤
- 橙色部分:字节码文件生成过程,和JVM无关
- 蓝色、绿色:JVM需要考虑的过程
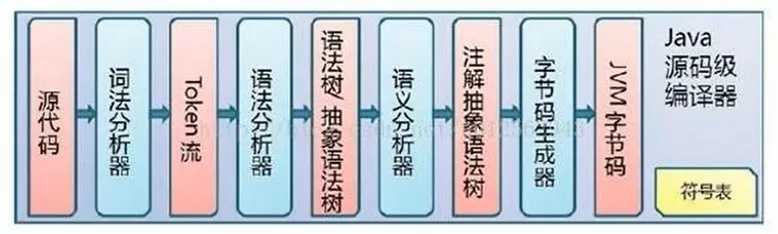
1. 代码编译
由Java源码编译器来完成,流程如下
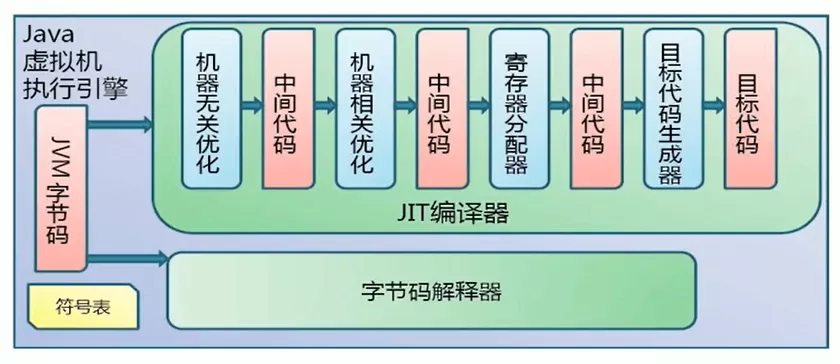
2. 字节码执行
执行引擎来完成,流程如下
3. 解释器、编译器
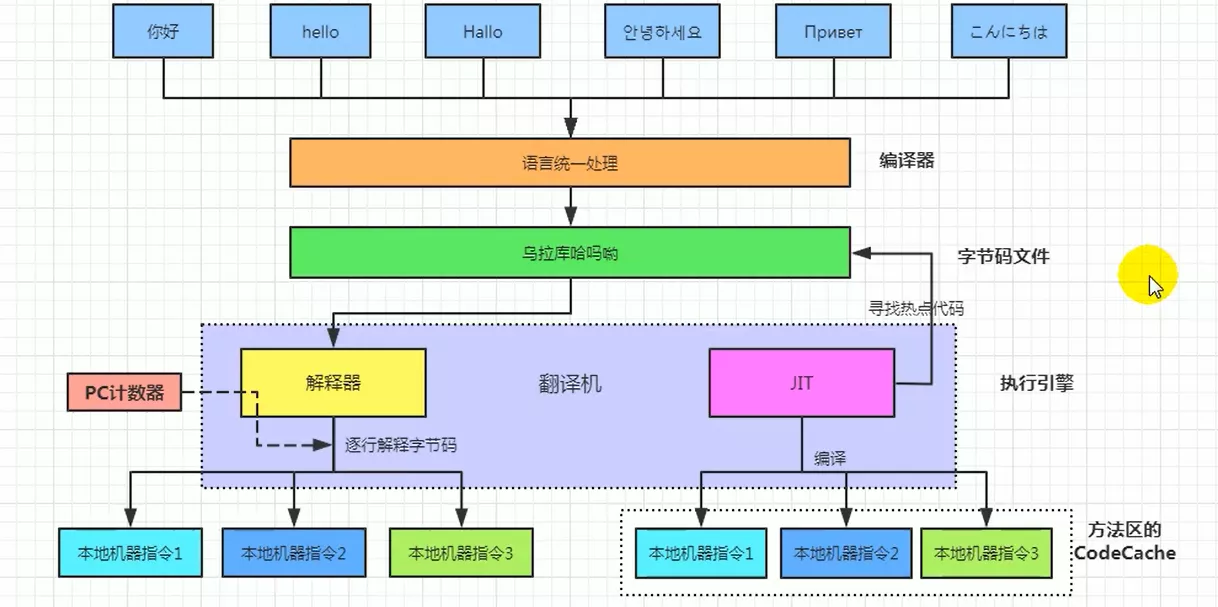
1. Interpreter
解释器:JVM启动时,根据预定义的规范对字节码采用逐行解释执行,将每条字节码“翻译“为对应平台的本地机器指令执行
2. JIT即时编译器
- JIT(Just In Time Compiler):JVM将源代码直接编译成 => 本地机器平台相关的机器语言
- 翻译成本地代码后,可以做一个缓存操作,存储在方法区中
3. 半解释半编译
- JDK1.0时代,将Java语言定位为“解释执行”比较准确。再后来,Java也发展出可以直接生成本地代码的编译器
- 现在JVM在执行Java代码时,通常都会将《解释执行》+《编译执行》二者结合起来进行
4. 机器码、指令、编译
1. 机器码
机器指令码:各种用二进制编码方式表示的指令。初始人们用它编写程序,这就是机器语言
- 机器语言虽然能够被计算机理解和接受,但和人的语言差别太大,不易被人们理解和记忆,并且用它编程容易出差错
- 用它编写的程序一经输入计算机,CPU直接读取运行。和其他语言编写的程序相比,执行速度最快
- 机器指令与CPU紧密相关,不同种类的CPU对应的机器指令不同
2. 指令
- 机器码:由0、1组成的二进制序列,可读性实在太差。于是人们发明了指令
- 指令:把机器码中特定的0、1序列,简化成对应的指令(英文简写,eg:mov,inc等),可读性稍好
- 由于不同的硬件平台,执行同一个操作,对应的机器码可能不同。所以不同的硬件平台的同一种指令,对应的机器码也可能不同
3. 指令集
不同的硬件平台,各自支持的指令,是有差别的。因此各个平台所支持的指令,称之为对应平台指令集
- x86指令集。对应的是x86架构的平台
- ARM指令集。对应的是ARM架构的平台
4. 汇编语言
- 由于指令的可读性还是太差,于是人们又发明了汇编语言
- 汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)、标号(Label)代替指令或操作数地址
- 不同的硬件平台,汇编语言对应着不同的机器语言指令集。由于计算机只认识机器码,所以用汇编语言编写的程序还必须翻译成机器指令码,计算机才能识别和执行
5. 高级语言
- 为了使计算机用户编程更容易些,后来就出现了各种高级计算机语言。高级语言比机器语言、汇编语言更接近人的语言
- 当计算机执行高级语言程序时,仍然需要把程序解释、编译成机器指令码。这个过程叫做解释程序、编译程序
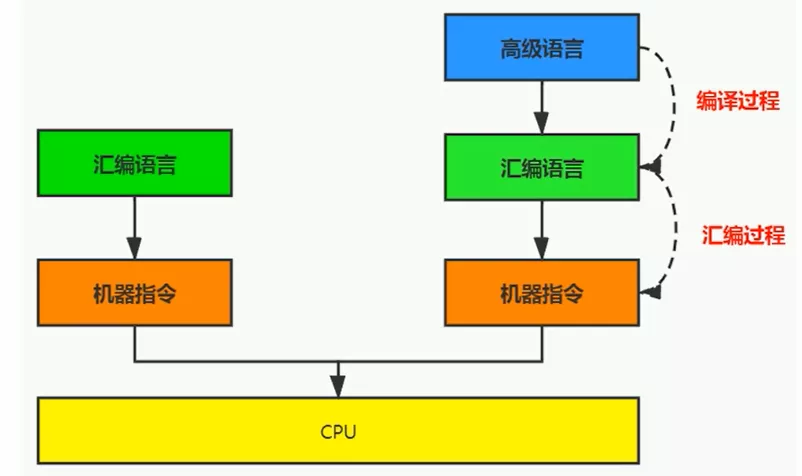
高级语言也不是直接翻译成机器指令,而是翻译成汇编语言码。eg:C、C++
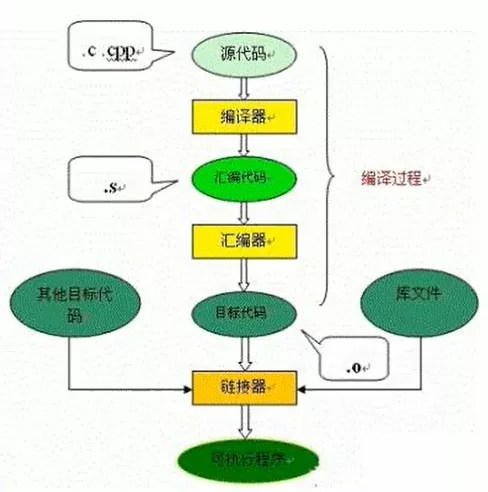
6. C、CPP执行过程
编译过程分成两个阶段:编译、汇编
- 编译过程:读取源程序(字符流),对之进行词法和语法分析,将高级语言指令转换为功能等效的汇编代码
- 汇编过程:实际上指把汇编语言代码翻译成目标机器指令的过程
7. 字节码
- 是一种中间状态(中间码)的二进制代码(文件),它比机器码更抽象,需要直译器转译后才能成为机器码
- 主要为了实现特定软件运行,和软件、硬件环境无关
- 实现方式是通过编译器和VM。编译器将源码编译成字节码,特定平台上的VM将字节码转译为可以直接执行的指令
- 典型的应用为:Java bytecode
5. 解释器
JVM设计者初衷仅仅只是为了满足Java实现跨平台特性,因此避免采用静态编译的方式直接生成本地机器指令,从而诞生了运行时采用逐行解释字节码执行程序的想法——解释器
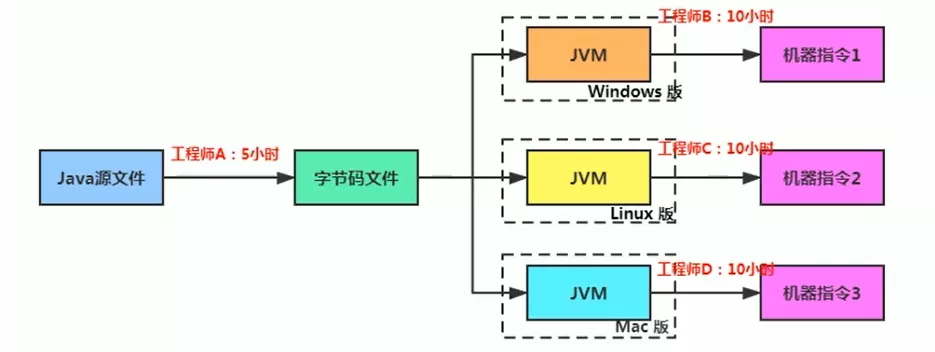
- 解释器真正意义上所承担的角色就是运行时“翻译者”,将字节码文件的内容“翻译”为对应平台的本地机器指令执行
- 当一条字节码指令被解释执行完成后,接着再根据PC记录的下一条字节码指令执行解释操作
1. 分类
在Java的发展历史里,一共有两套解释执行器,即古老的字节码解释器、现在普遍使用的模板解释器
- 字节码解释器:在执行时通过纯软件代码模拟字节码的执行,效率非常低下
- 模板解释器:每一条字节码和一个模板函数相关联,模板函数中直接产生这条字节码执行时的机器码,从而很大程度上提高了解释器的性能
在HotSpot中,解释器主要由Interpreter模块和Code模块构成
- Interpreter模块:实现了解释器的核心功能
- Code模块:用于管理HotSpot在运行时生成的本地机器指令
2. 现状
- 由于解释器在设计和实现上非常简单,因此除了Java语言之外,还有许多高级语言同样也是基于解释器执行的,eg:Python、Perl、Ruby等。但是在今天,基于解释器执行已经沦落为低效的代名词,并且时常被一些C/C++程序员所调侃
- 为了解决这个问题,JVM平台支持一种叫作即时编译的技术。目的:避免函数被解释执行,而是将整个函数体编译成为机器码,每次函数执行时,只执行编译后的机器码即可,使执行效率大幅度提升
- 无论如何,基于解释器的执行模式,仍然为中间语言的发展做出了不可磨灭的贡献
6. JIT编译器
1. Java执行分类
- 解释执行:源代码编译成字节码文件后,运行时解释器将字节码文件转为机器码执行
- 编译执行(直接编译成机器码)。现代VM为了提高执行效率,会使用即时编译技术(JIT,Just In Time),将方法编译成机器码后再执行
- HotSpot是目前市面上高性能VM的代表作之一。它采用解释器、即时编译器并存的架构。在JVM运行时,解释器和即时编译器能够相互协作,各自取长补短。权衡直接解释执行代码的时间和编译本地代码的时间,选择最合适的方式执行
- 今天,Java程序的性能早已脱胎换骨,已经达到了可以和C/CPP程序一较高下的地步
2. JVM执行方式
- JVM采用解释器与即时编译器并存的架构,寻找一个平衡点。在此模式下,当JVM启动时,解释器首先发挥作用,而不必等待JIT全部编译完成再执行,这样可以省去许多不必要的编译时间。随着运行时间的推移,JIT逐渐发挥作用,根据热点探测功能,将有价值的字节码编译为本地机器指令,以换取更高的程序执行效率
- 同时,在编译器进行激进优化不成立时,解释执行作为编译器的“逃生门”
既然HotSpot中已经内置JIT编译器了,为什么还使用解释器来“拖累”程序的性能呢?
- 程序启动,解释器可以马上发挥作用,省去编译的时间,立即执行
- 编译器要想发挥作用,把代码编译成本地代码,需要一定的执行时间。但编译为本地代码后,执行效率高
- JRockit砍掉了解释器,只保留及时编译器。因为JRockit只部署在服务器上,一般有足够时间进行指令编译,对于响应来说要求不高,等及时编译器的编译完成后,就会提供更好的性能
1. 案例
- 注意解释执行、编译执行在线上环境微妙的辩证关系。机器在热机状态可以承受的负载要大于冷机状态。如果以热机状态时的流量进行切流,可能使处于冷机状态的服务器因无法承载流量而假死
- 生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8
- 故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT的存在——阿里团队
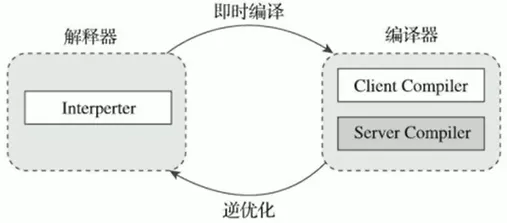
3. 概念
Java语言的“编译期”其实是一段“不确定”的操作过程
- 可能指一个前端编译器(“编译器的前端”更准确一些),把
.java文件转变成.class文件的过程 - 也可能指VM的后端运行期编译器(JIT编译器,Just In Time Compiler),把字节码转变成机器码
- 还可能指使用静态提前编译器(AOT编译器,Ahead of Time Compiler),直接把
.java文件编译成本地机器代码
- 前端编译器:Sun的Javac、Eclipse JDT中的增量式编译器(ECJ)
- JIT编译器:HotSpot的C1、C2编译器
- AOT编译器:GNU Compiler for the Java(GCJ)、Excelsior JET
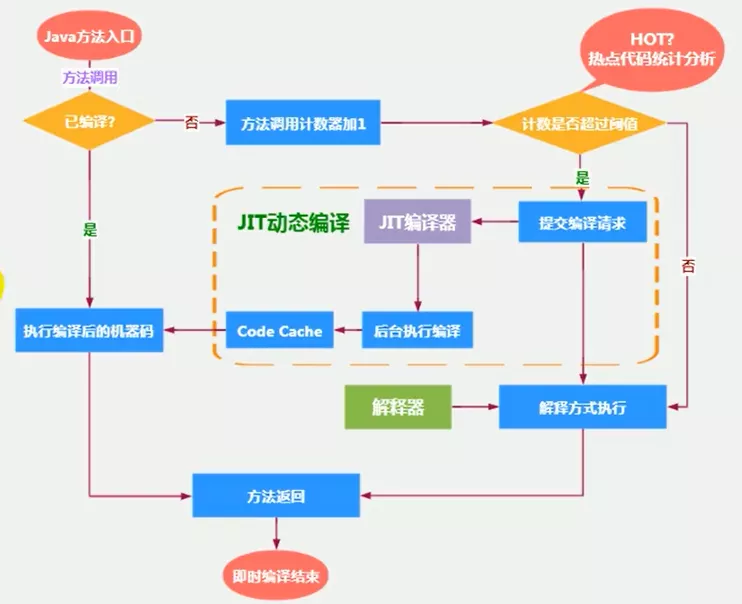
4. 热点探测技术
- 热点代码:一个被多次调用的方法,或是一个方法体内部循环次数较多的循环体,可以通过JIT编译为本地机器指令
- 这种编译方式发生在方法的执行过程中,称为栈上替换,或OSR(On Stack Replacement)编译
- 一个究竟要被调用多少次,或者一个循环体究竟需要执行多少次循环才可以达到这个标准?必然需要一个明确的阈值,JIT才会将这些“热点代码”编译为本地机器指令执行。主要依靠热点探测功能
HotSpot采用基于计数器热点探测,为每一个方法建立2个不同类型的计数器:
- 方法调用计数器(Invocation Counter)
- 用于统计方法的调用次数
- 回边计数器(Back Edge Counter)
- 用于统计循环体执行的次数
1. 方法调用计数器
- 用于统计方法被调用的次数,默认阈值在Client模式下是1500次,在Server模式下是10000次。超过阈值,就会触发JIT编译。可以通过JVM参数
-XX:CompileThreshold人为设定 - 一个方法被调用,先检查是否被JIT编译过,优先执行编译后的本地代码;没被编译,则将此方法的调用计数器加1,如果
(方法调用计数器 + 回边计数器) > 阈值,向JIT进行代码编译请求
1. 热点衰减
- 半衰周期是化学中的概念。eg:出土的文物通过查看C60来获得文物的年龄
- 如果不做任何设置,方法调用计数器统计的并不是被调用的绝对次数,而是一个相对的执行频率,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果次数仍然不足阈值,调用计数器值就会减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就称为此方法的半衰周期(Counter Half Life Time)
- 进行热度衰减是在JVM进行GC时顺便进行的。使用JVM参数
-XX:-UseCounterDecay来关闭热度衰减,让方法计数器统计方法调用的绝对次数。这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码 - 另外,可以使用
-XX:CounterHalfLifeTime参数设置半衰周期的大小,单位是秒
2. 回边计数器
统计一个方法中循环体执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”(Back Edge)。显然,建立回边计数器统计的目的就是为了触发OSR编译
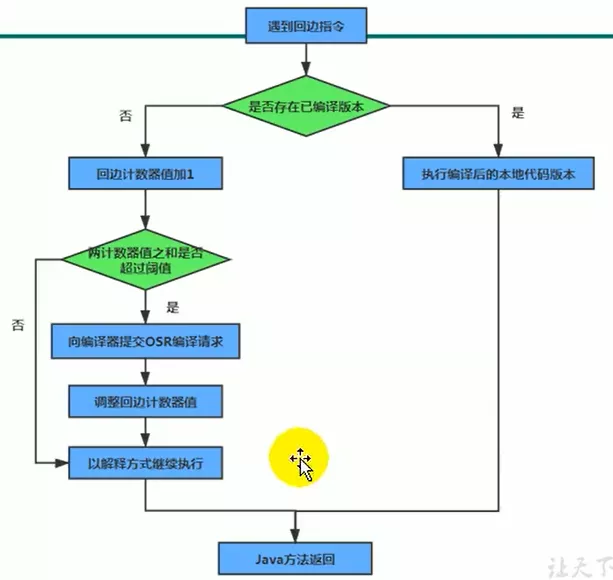
- OSR(On Stack Replacement)栈上替换的编译
-XX:OnStackReplacePercentage=140来设置,Client默认为933,Server默认为140- eg:main方法,只执行一次,远远达不到阈值,但是方法体中执行了多次循环,OSR编译就是只编译该循环代码,然后将其替换,下次循环直接执行编译好的代码,不过触发OSR编译也需要一个阈值
-XX:CompileThreshold = 10000
-XX:OnStackReplacePercentage = 140
-XX:InterpreterProfilePercentage = 33
OSR trigger = (CompileThreshold * (OnStackReplacePercentage - InterpreterProfilePercentage)) / 100 = 10700
5. 设置程序执行模式
缺省情况下HotSpot是采用解释器、即时编译器并存的架构。根据具体的应用场景,通过命令显式地指定
-Xint(Interpreted Mode):解释器模式-Xcomp(Compiled Mode):JIT模式。如果JIT出现问题,解释器会介入执行-Xmixed(Mixed Mode):解释器 + JIT的混合模式
➜ ~# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
➜ ~# java -Xint -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, interpreted mode)
➜ ~# java -Xcomp -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, compiled mode)
➜ ~# java -Xmixed -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
6. JIT分类
在HotSpot中内嵌有两个JIT编译器,Client_Compiler、Server_Compiler,简称为C1编译器、C2编译器。显式指定哪一种JIT
-client:指定JVM运行在Client模式下,并使用C1编译器- C1对字节码进行简单、可靠的优化,耗时短。以达到更快的编译速度
-server:指定JVM运行在Server模式下,并使用C2编译器- C2进行耗时较长的优化,以及激进优化。但优化的代码执行效率更高(使用C++)
1. C1、C2优化策略
- 运行后C1、C2编译出来的机器码如果不再符合优化条件,则会进行逆优化,回到解释执行
- eg:基于类层次分析编译的代码,当有新的相应的接口实现类加入时,就执行逆优化
- C1
- 方法内联:将引用的函数代码编译到引用点处,这样可以减少栈帧的生成,减少参数传递以及跳转过程
- 去虚拟化:对唯一的实现类进行内联
- 冗余消除:在运行期间把一些不会执行的代码折叠掉
- C2。在全局层面,逃逸分析是优化基础
- 标量替换:用标量值代替聚合对象的属性值
- 栈上分配:对于未逃逸的对象分配对象在Stack而不是Heap
- 同步消除:清除同步操作,通常指
synchronized-XX:+EliminateLocks
1. 方法内联
- 方法内联的阈值:35byte
- 可在debug版本的JDK的启动参数加上
-XX:+PrintInlining来查看方法内联的信息
private int add4(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
JVM会把add2去掉,并把代码翻译成:
private int add4(int x1, int x2, int x3, int x4) {
return x1 + x2 + x3 + x4;
}
2. 标量替换
通过-XX:+EliminateAllocations可以开启标量替换,-XX:+PrintEliminateAllocations查看标量替换情况
Point point = new Point(1, 2);
System.out.println("point.x = " + point.x + "; point.y = " + point.y);
当point对象在后面的执行过程中未用到时,经过编译后,代码会变成类似下面的结构:
int x = l;
int y = 2;
System.out.println("point.x=" + x + "; point.y = " + y);
3. 冗余削除
在编译时根据运行时状况进行代码折叠或削除
private static final Log log = LogFactory.getLog("BLUEDAVY")
private static final boolean isDebug=log.isDebugEnabled();
public void execute()[
if(isDebug) {
log.debug(*enter this method: execute");
}
// do something
}
eg:log.isDebugEnabled返回的为false,在执行C1编译后,这段代码就演变成类似下面的结构:
代码编写规则上写不要直接调用 log.debug,而要先判断
public void execute() {
// do something
}
4. 常量编译优化
常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化
package org.fenixsoft.classloading;
/**
* 被动使用类字段演示三
* 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化
*/
public class ConstClass (
static {
System.out.printIn("ConstClass init!");
}
public static final String HELLOWORLD = "hello world"
}
/**
* 非主动使用类字段演示
*/
public classNotInitialization {
public static void main(String[] args) {
System.out.println(ConstCIass.HELLOWORLD);
}
}
5. CodeCache
主要用于缓存编译后的机器码,动态生成的代码和本地方法代码(JNI)
- JVM参数
InitialCodeCacheSize:CodeCache区域初始化大小ReservedCodeCacheSize:CodeCache区域的最大值(linux下默认为48M,如果开启了分层编译默认为240M,大小不能超过2048M)CodeCacheMinimumFreeSpace:当CodeCache的可用大小不足这个值时,就会停止JIT编译,并进行code cache full的处理逻辑UseCodeCacheFlushing:一旦CodeCache达到这个值,JVM将会切换到interpreted-only(解释执行)模式,字节码不会再被编译为机器码,应用程序将继续运行,但是运行速度将会降低一个数量级
- JIT预热
- 面对大流量并发场景,当一个方法瞬间流量激增,会瞬间达到JIT编译的阈值,JVM会执行JIT编译,将热点代码编译成机器码进行缓存,但是当热点代码过多,JIT编译的压力剧增,直接导致系统负载瞬时拉高,CPU占用率也会飙升,导致整体服务性能降低
- 建议针对大流量并发场景,应用上线时提前预估流量逐步切流,避免瞬时流量触发JIT编译,待JIT编译预热完成,逐步切入全量流量
- CodeCache注意事项
- 如果CodeCache区域被占满,编译器被停用,字节码将不会编译为机器码,应用程序继续运行,但运行速度会降低一个数量级,严重影响系统运行性能
2. 分层编译策略
- 分层编译(Tiered Compilation)策略
- 程序解释执行(不开启性能监控)可以触发C1编译,将字节码编译成机器码,可以进行简单优化
- 加上性能监控,C2编译会根据性能监控信息进行激进优化
JDK7之后,一旦在程序中显式指定-server,默认开启分层编译策略,由C1、C2相互协作共同执行编译任务
# 开启
-XX:+TieredCompilation
# 关闭
-XX:-TieredCompilation
7. future
1. Graal编译器
- 自JDK10起,HotSpot又加入了一个全新的及时编译器:Graal编译器
- 编译效果短短几年就追平了C2编译器,未来可期
- 目前,带着“实验状态”标签,需要使用开关参数去激活才能使用
-XX:+UnlockExperimentalvMOptions -XX:+UseJVMCICompiler
2. AOT编译器
- JDK9引入了AOT编译器(静态提前编译器,Ahead of Time Compiler)
- 实验性AOT编译工具jaotc。借助Graal编译器,将所输入的Class文件转换为机器码,并存放至生成的动态共享库之中
- 所谓AOT编译,是与JIT相对立的一个概念
- JIT指的是在程序运行过程中,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程
- AOT编译指的则是,在程序运行之前,便将字节码转换为机器码的过程
.java => .class =>(使用jaotc)=> .so
- 优点:
- JVM加载已经预编译成二进制库,可以直接执行。不必等待JIT的预热,减少Java应用给人带来“第一次运行慢” 的不良体验
- 缺点:
- 破坏了java“ 一次编译,到处运行”,必须为每个不同的硬件,OS编译对应的发行包
- 降低了Java链接过程的动态性,加载的代码在编译器就必须全部已知
- 还需要继续优化中,最初只支持Linux X64 java base
利用下面的命令把某个类或者某个模块编译成为AOT库
jaotc --output libHelloWorld.so HelloWorld.class
jaotc --output libjava.base.so --module java.base
启动:
java -XX:AOTLibrary=./libHelloWorld.so,./libjava.base.so HelloWorld
- OracleJDK支持分层编译和AOT协作使用,这两者并不是二选一的关系。可以参考相关文档:JEP 295: Ahead-of-Time Compilation
- AOT也仅仅是只有一种方式,业界早就有第三方工具(如GCJ、ExcelsiorExcelsiorJET)提供相关功能