02-六大设计原则
- 评判代码质量的标准
- eg:可读性、可复用性、可扩展性等,从代码整体质量的角度来评判
- 设计原则是更加具体的对于代码进行评判的标准
- eg:这段代码的可扩展性比较差,主要原因是违背了开闭原则
六大设计原则 (SOLID)(重点关注三个常用原则):
- 单一职责原则(SRP):类的职责要单一
- 开闭原则(OCP):总纲,对扩展开放,对修改关闭
- 里氏替换原则(LSP):子类可以透明替换父类
- 接口隔离原则(ISP):接口的职责要单一
- 依赖倒置原则(DIP):面向接口编程
- 迪米特法则 (LoD):降低耦合
1. 概述
- 设计模式通常遵循一些设计原则,在设计原则的基础之上衍生出了各种各样的设计模式
- 设计原则是设计要求,设计模式是设计方案,使用设计模式的代码则是具体的实现
设计模式中主要有六大设计原则,简称为SOLID。是由各个原则的首字母简称合并的来(两个L算一个,solid 稳定的)
- 单一职责原则(Single Responsibitity Principle)
- 开放封闭原则(Open Close Principle)
- 里氏替换原则(Liskov Substitution Principle)
- 接口隔离原则(Interface Segregation Principle)
- 依赖倒置原则(Dependence Inversion Principle)
- 迪米特法则(Law Of Demter)
软件开发中要基于这六个原则,设计建立稳定、灵活、健壮的程序
2. 单一职责原则
1. 官方定义
- 单一职责原则,英文缩写SRP(Single Responsibility Principle)
- 《架构整洁之道》一书中,英文描述:
A class or module should have a single responsibility。一个类或者模块只负责完成一个职责(功能)- 提高类的内聚性
- 实现代码的 高内聚、低耦合
2. 通俗解释
- 一个类或者模块只负责完成一个职责(功能)
- 在类的设计中,不要设计大而全的类,而是要设计粒度小、功能单一的类
eg:设计一个类既包含了用户的一些操作,又包含了支付的一些操作,那这个类的职责就不够单一。应该将该类进行拆分,拆分成多个功能更加单一的。粒度更细的类
3. 场景示例
软件设计中,真正用好单一职责原则并不简单,因为遵循这一原则最关键的地方在于职责的划分,而职责的划分是根据需求定的,同一个类(接口)的设计,在不同的需求里面,可能职责的划分并不一样
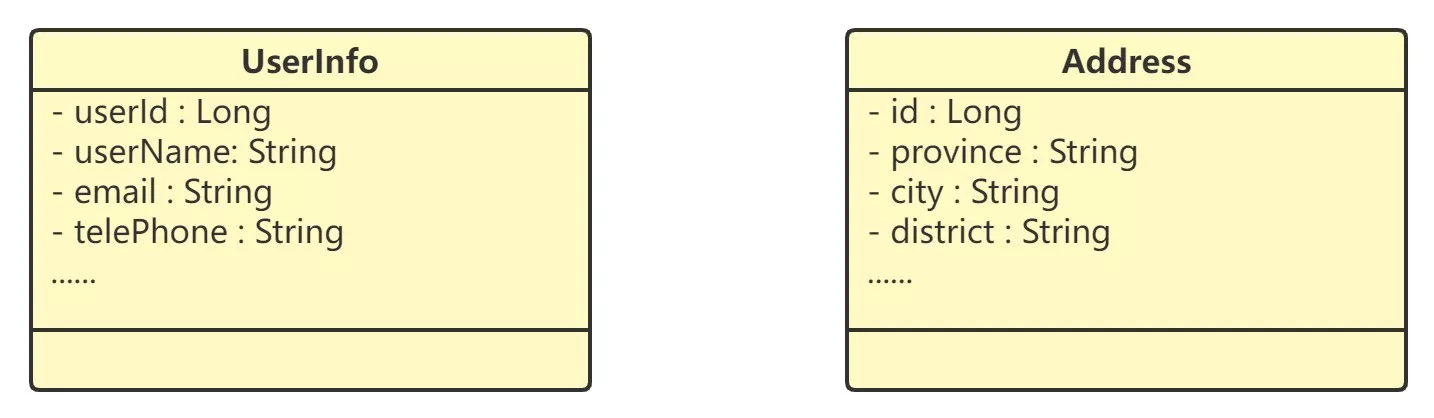
在一个社交媒体产品中,使用 UserInfo 去记录用户信息,包括如下属性。是否满足单一职责原则呢?
- 观点1:满足,因为记录的都是跟用户相关的信息
- 观点2:不满足,因为地址信息应该被拆分出来,单独放到地址表中保存

正确答案:根据实际业务场景选择是否拆分
- 该社交产品的有用户信息只是用来展示的,那么这个类这样设计就没有问题
- 假设后面这个社交产品又添加了电商模块,那就需要将地址信息提取出来,单独设计一个类
- 总结: 不同的应用场景、不同阶段的需求背景下,对同一个类的职责是否单一的判定,可能是不一样的
- 最好的方式就是:先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构
如何判断一个类的职责是否单一?(没有一个具体的金科玉律,但从实际代码开发经验上,有一些可执行性的侧面判断指标,可供参考)
- 类中的代码行数、函数、属性过多
- 类依赖的其他类过多
- 私有方法过多
- 类中大量的方法都是集中操作类中的几个属性
3. 开闭原则
- 所有设计模式的最核心目标。也是最难实现目标,但是所有的软件设计模式都应该以开闭原则当作标准,才能使软件更加的稳定和健壮
1. 官方定义
- 一般认为最早提出开闭原则(OCP,Open-Close Principle)的是伯特兰·迈耶。他在1988年发表的《面向对象软件构造》中给出的。在面向对象编程领域中,开闭原则规定软件中的对象、类、模块和函数对扩展应该是开放的,但对于修改是封闭的
- 这意味着应该用抽象定义结构,用具体实现扩展细节,以此确保软件系统开发和维护过程的可靠性
2. 通俗解释
定义:对扩展开放,对修改关闭
- 对扩展开放和对修改关闭表示:当一个类或一个方法有新需求、需求发生改变时,应该采用扩展的方式而不应该采用修改原有逻辑的方式来实现
- 因为扩展新的逻辑,如果有问题只会影响新的业务,不会影响老业务;如果采用修改的方式,很有可能影响老业务
优点:
- 新老逻辑解耦,需求发生改变不会影响老业务逻辑
- 改动成本最小,只需要追加新逻辑,不需要改的老逻辑
- 提升代码稳定性、可扩展性
3. 场景示例
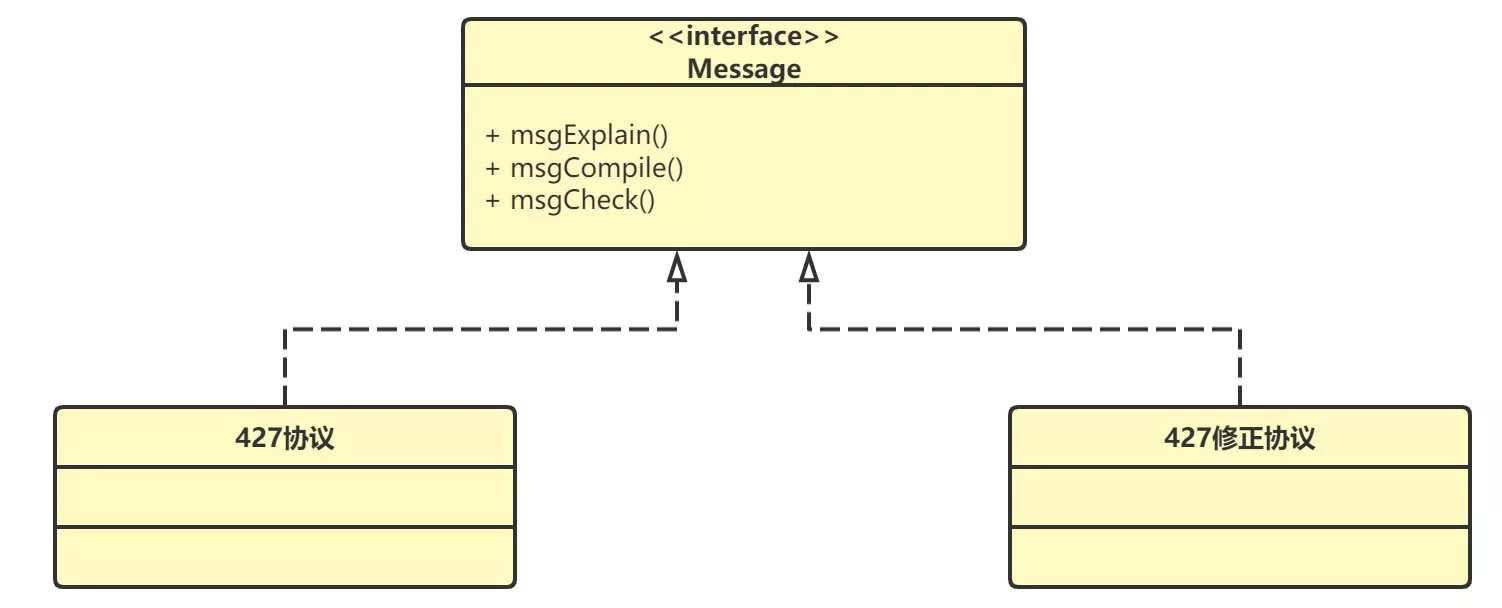
- 系统A、B之间进行数据传输使用427版本的协议,一年以后对427版本的协议进行了修正
- 设计时应该考虑数据传输协议的可变性,抽象出具有报文解译、编制、校验等所有版本协议使用的通用方法,调用方针对接口进行编程即可
- 调用方依赖于报文接口,报文接口是稳定的,而不针对具体的427协议、427修正协议。利用接口多态技术,实现开闭原则
顶层设计思维
- 抽象意识
- 封装意识
- 扩展意识
写代码时,多花点时间思考一下,这段代码未来可能有哪些需求变更、如何设计代码结构,事先留好扩展点,以便在未来需求变更时,不需要改动代码整体结构、做到最小代码改动的情况下,新代码能够灵活地插入到扩展点上,做到 对扩展开放、对修改关闭
提高拓展性方式
- 多态
- 依赖注入
- 面向接口编程
- 合理使用设计模式
4. 里氏替换原则
1. 官方定义
- 里氏替换原则(LSP,Liskov Substitution Principle)是由麻省理工学院计算机科学系教授芭芭拉·利斯科夫,于1987年在“面向对象技术的高峰会议”(OOPSLA)上发表的一篇论文《数据抽象和层次》(Data Abstractionand Hierarchy)里提出的
- 她在论文中提到:如果S是T的子类型,对于S类型的任意对象,如果将他们看作是T类型的对象,则对象的行为也理应与期望的行为一致
- 子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏
2. 通俗解释
- 什么是替换?
- 替换的前提是面向对象语言所支持的多态特性,同一个行为具有多个不同表现形式或形态的能力
- 以JDK的集合框架为例,
List接口的定义为有序集合,List接口有多个派生类。eg:ArrayList,LinkedList- 那当某个方法参数或变量是
List接口类型时,既可以是ArrayList的实现,也可以是LinkedList的实现,这就是替换
- 什么是与期望行为一致的替换?(Robert Martin所说的“必须能够替换”)
- 在不了解派生类的情况下,仅通过接口或基类的方法,即可清楚的知道方法的行为,而不管哪种派生类的实现,都与接口或基类方法的期望行为一致
- 不需要关心是哪个类对接口进行了实现,因为不管底层如何实现,最终的结果都会符合接口中关于方法的描述(也就是与接口中方法的期望行为一致)
- 或者说接口、基类的方法是一种契约,使用方按照这个契约来使用,派生类也按照这个契约来实现。这就是与期望行为一致的替换
3. 场景示例
- 要求:在编码时使用基类、接口去定义对象变量,使用时可以由具体实现对象进行赋值,实现变化的多样性,完成代码对修改的封闭,扩展的开放
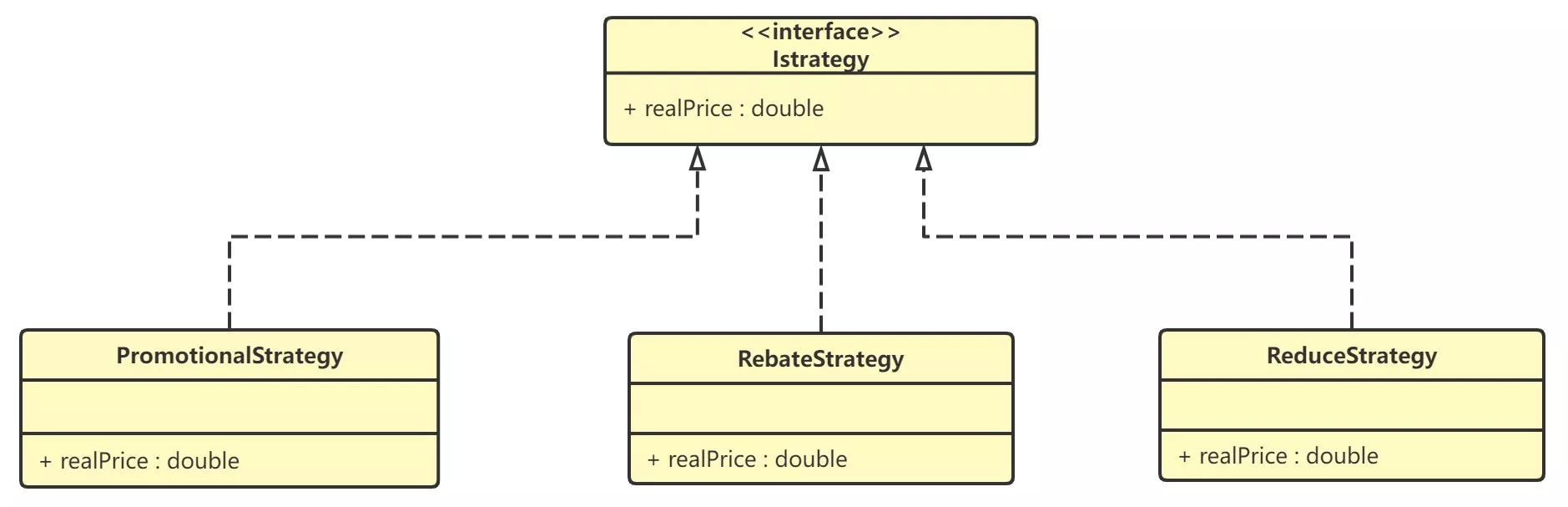
- 在一个商城项目中,定义结算接口
Istrategy,该接口有三个具体实现类PromotionalStrategy(满减活动,两百以上打八折)RebateStrategy(直接打折活动)ReduceStrategy(返现活动,满一千减两百)
public interface Istrategy {
public double realPrice(double consumePrice);
}
public class PromotionalStrategy implements Istrategy {
public double realPrice(double consumePrice) {
if (consumePrice > 200) {
return 200 + (consumePrice - 200) * 0.8;
} else {
return consumePrice;
}
}
}
public class RebateStrategy implements Istrategy {
private final double rate;
public RebateStrategy() {
this.rate = 0.8;
}
public double realPrice(double consumePrice) {
return consumePrice * this.rate;
}
}
public class ReduceStrategy implements Istrategy {
public double realPrice(double consumePrice) {
if (consumePrice >= 1000) {
return consumePrice - 200;
} else {
return consumePrice;
}
}
}
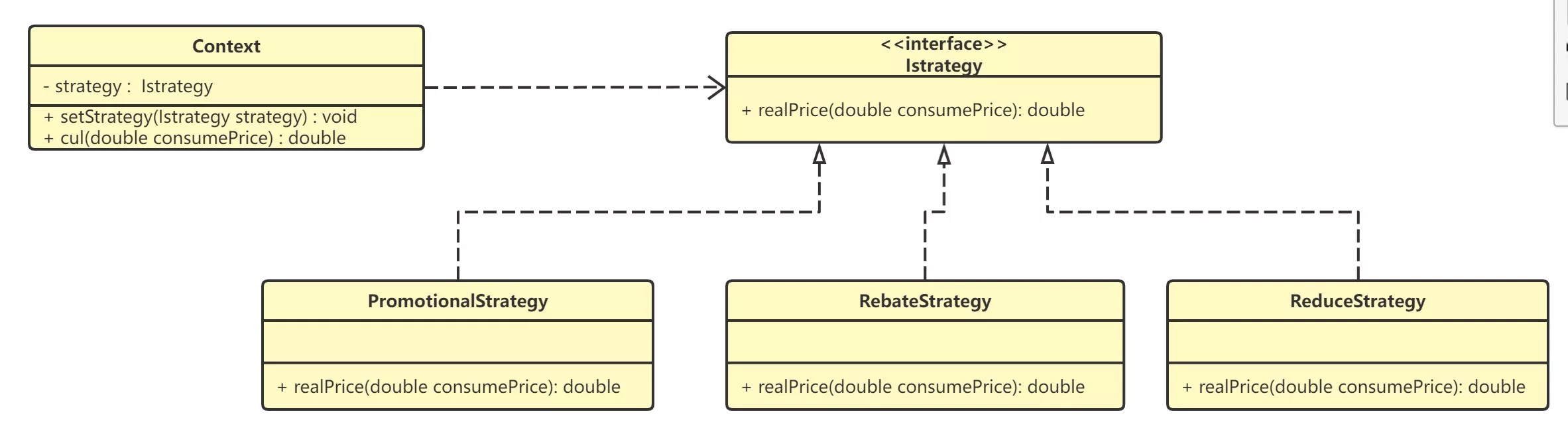
- 调用方为
Context,在此类中使用接口定义了一个对象
public class Context {
// 使用基类定义对象变量
private Istrategy strategy;
// 注入当前活动使用的具体对象
public void setStrategy(Istrategy strategy) {
this.strategy = strategy;
}
// 计算并返回费用
public double cul(double consumePrice) {
// 使用具体商品促销策略获得实际消费金额
double realPrice = this.strategy.realPrice(consumePrice);
// 格式化保留小数点后1位,即:精确到角
BigDecimal bd = new BigDecimal(realPrice);
bd = bd.setScale(1, BigDecimal.ROUND_DOWN);
return bd.doubleValue();
}
}
里氏代换原则、多态区别?
- 虽然从定义描述和代码实现上来看,多态和里式替换有点类似,但它们关注的角度是不一样的
- 多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路
- 里式替换是一种设计原则,用来指导继承关系中子类该如何设计,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑及不破坏原有程序的正确性
里氏替换原则、依赖倒置原则,构成了面向接口编程的基础,正因为里氏替换原则,才使得程序呈现多样性
5. 接口隔离原则
- 《Interface Segregation Principle》
1. 官方定义
- 《代码整洁之道》作者罗伯特 C·马丁为 “接口隔离原则” 的定义是:
Clients should not be forced to depend on methods they do not use(客户端不应该被迫依赖于它不使用的方法)
- 另一定义:一个类对另一个类的依赖应该建立在最小的接口上
2. 通俗解释
- 要为各个类建立它们需要的专用接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用
接口隔离原则、单一职责都是为了提升类的高内聚、低耦合,体现了封装的思想,但两者是不同的:
- 单一注重的是职责,而接口隔离注重的是对接口依赖的隔离
- 单一主要是约束类,针对的是程序中的实现和细节;接口隔离主要约束接口,针对抽象和程序整体框架的构建
3. 场景示例
- 微服务用户系统提供了一组跟用户相关的API给其他系统使用。eg:注册、登录、获取用户信息等

public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public class UserServiceImpl implements UserService {
// ...
}
需求:后台管理系统要实现删除用户的功能,希望用户系统提供一个删除用户的接口,如何设计这个接口(假设这里不考虑使用鉴权框架)
方案1:直接在
UserService接口中添加一个删除用户的接口可以解决问题,但也隐藏了一些安全隐患。删除用户是一个非常慎重的操作,只希望通过后台管理系统来执行,这个接口只限于给后台管理系统使用。如果把它放到
UserService中, 那所有使用UserService的系统,都可以调用这个接口。不加限制地被其他业务系统调用,就有可能导致误删用户方案2:遵照接口隔离原则,为依赖接口的类定制服务。只提供调用者需要的方法,屏蔽不需要的方法
将删除接口单独放到另外一个接口
RestrictedUserService中, 然后将RestrictedUserService只打包提供给后台管理系统来使用

public interface RestrictedUserService {
boolean deleteUserByCellphone(String cellphone);
boolean deleteUserById(long id);
}
public class UserServiceImpl implements UserService, RestrictedUserService {
// ...
}
优点:
- 将臃肿庞大的接口分解为多个粒度小的接口,可以预防外来变更的扩散,提高系统的灵活性、可维护性
- 使用多个专门的接口还能够体现对象的层次,因为可以通过接口的继承,实现对总接口的定义
- 能减少项目工程中的代码冗余。过大的大接口里面通常放置许多不用的方法,当实现这个接口的时候,被迫设计冗余的代码
6. 依赖倒置原则
- 依赖倒置原则是实现开闭原则的重要途径之一,它降低了客户与实现模块之间的耦合
- 依赖抽象,而不是依赖具体
- 面向抽象编程
1. 官方定义
- 依赖倒置原则(DIP,Dependence Inversion Principle)是Robert C.Martin于1996年在C++Report上发表的文章中提出的
High level modules should not depend upon low level modules. Both should depend upon abstractions. Abstractions should not depend upon details. Details should depend upon abstractions
- 是指在设计代码架构时,高层模块不应该依赖于底层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象
- 抽象是稳定的
- 细节是多变的
2. 通俗解释
- 高层级的模块应该依赖的是低层级模块的行为的抽象,取决于具体编程语言,可以是抽象类、接口等技术
- 只要依赖了实现,就是耦合了代码,所以始终依赖的是抽象,而不是实现
传统的自顶向下的设计
- 逐级依赖,中层模块、高层模块的耦合度很高。如果需要修改其中一个模块,可能导致其它模块也需要修改,牵一发动全身,不易于维护
- 不使用依赖反转的系统构架,控制流和依赖关系流的依赖箭头是一个方向的,由高层指向底层,也就是高层依赖底层
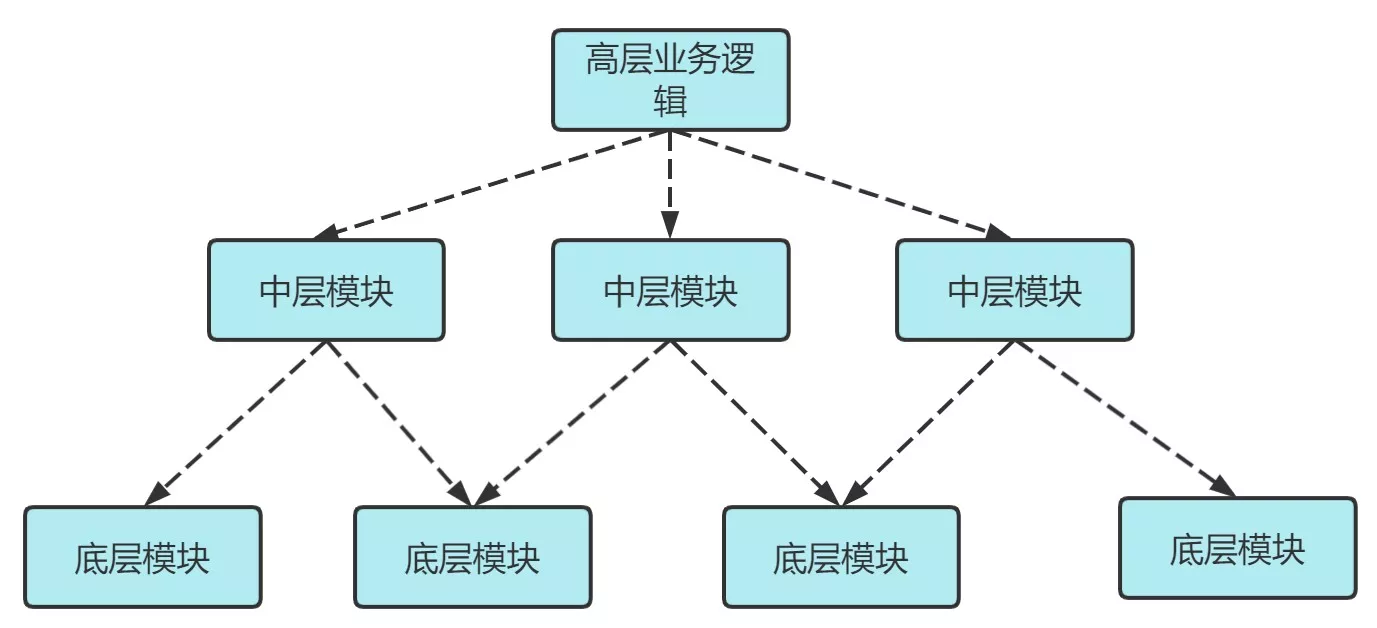
好处:
- 减少类间的耦合性,提高系统的稳定性
- 根据类与类之间的耦合度从弱到强:依赖关系、一般关联关系、聚合关系、组合关系、泛化关系、实现关系)
- 降低并行开发引起的风险(两个类之间有依赖关系,只要制定出两者之间的接口(或抽象类)就可以独立开发了)
- 提高代码的可读性、可维护性
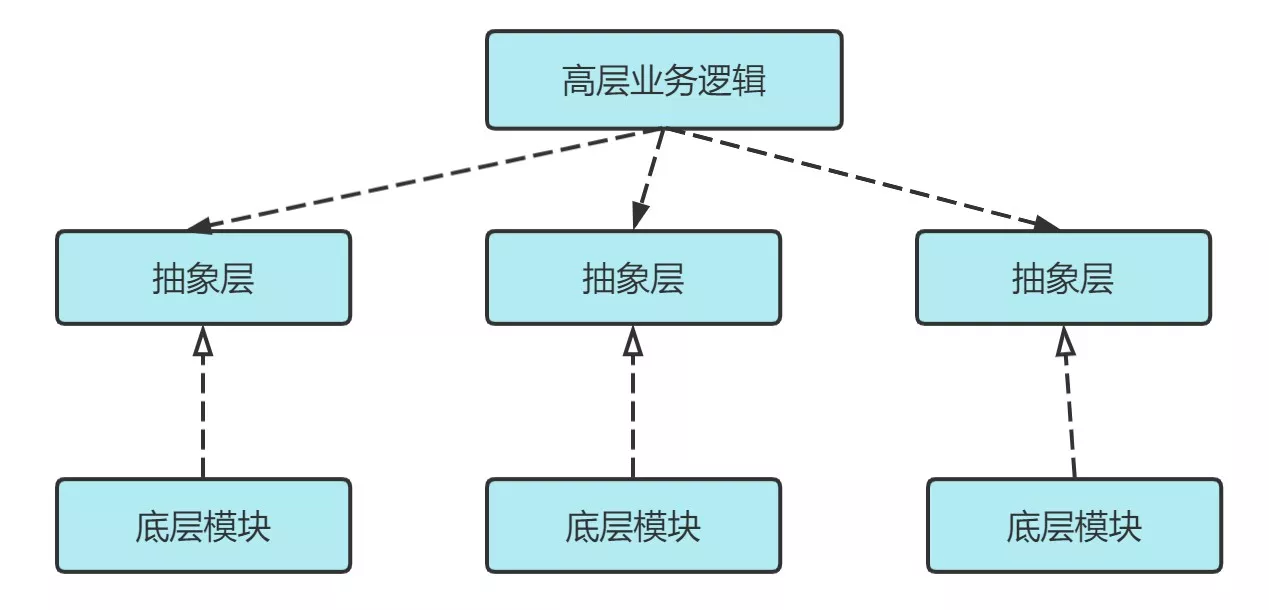
3. 场景示例
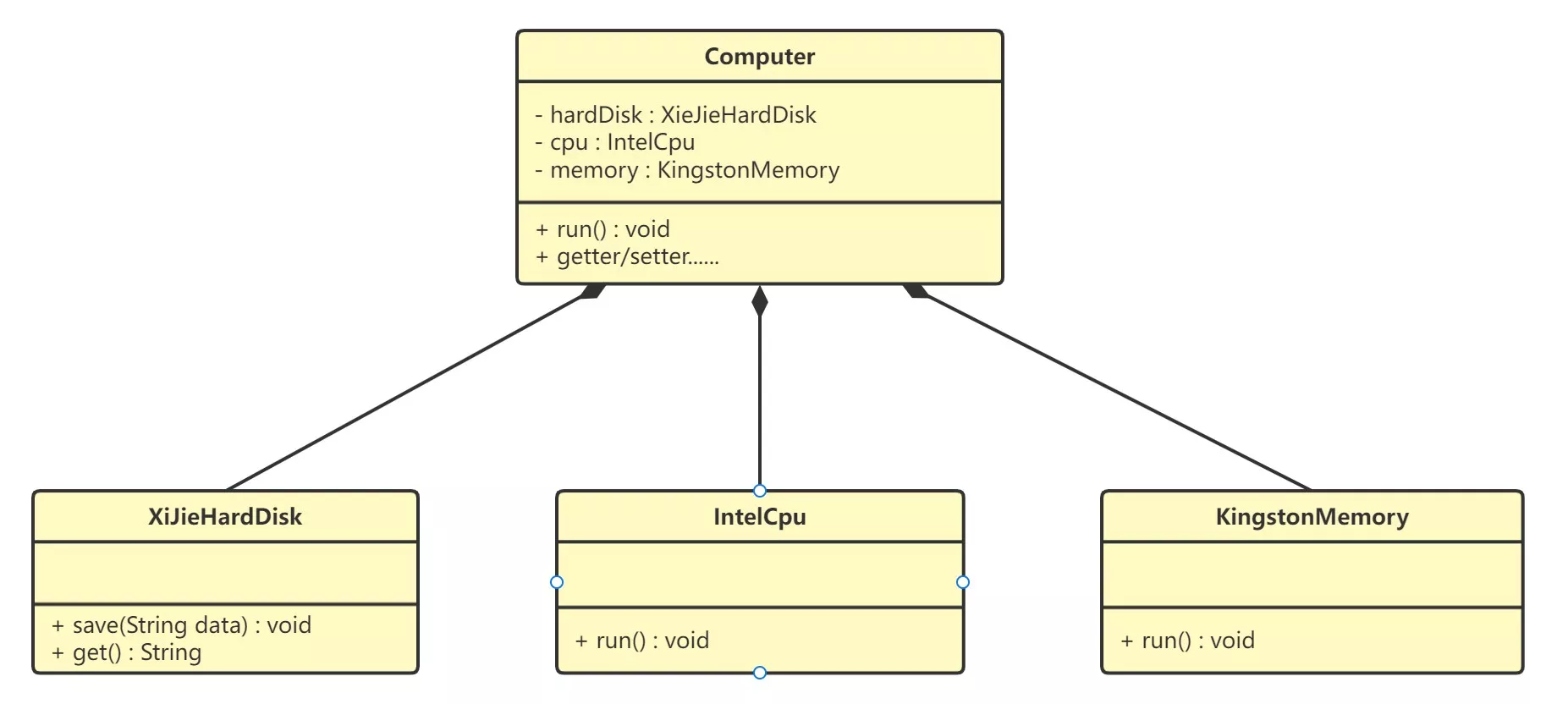
- 现在要组装一台电脑,需要的配件有:cpu、硬盘、内存条
- cpu选择:Intel、AMD等
- 硬盘选择:希捷、西数等
- 内存条选择:金士顿、海盗船等
public class XiJieHardDisk implements HardDisk {
public void save(String data) {
System.out.println("使用希捷硬盘存储数据" + data);
}
public String get() {
System.out.println("使用希捷希捷硬盘取数据");
return "数据";
}
}
public class IntelCpu implements Cpu {
public void run() {
System.out.println("使用Intel处理器");
}
}
public class KingstonMemory implements Memory {
public void save() {
System.out.println("使用金士顿作为内存条");
}
}
@Data
public class Computer {
private XiJieHardDisk hardDisk;
private IntelCpu cpu;
private KingstonMemory memory;
public void run() {
System.out.println("计算机工作");
cpu.run();
memory.save();
String data = hardDisk.get();
System.out.println("从硬盘中获取的数据为:" + data);
}
}
public class TestComputer {
public static void main(String[] args) {
Computer computer = new Computer();
computer.setHardDisk(new XiJieHardDisk());
computer.setCpu(new IntelCpu());
computer.setMemory(new KingstonMemory());
computer.run();
}
}
- 组装的电脑:cpu只能是Intel,内存条只能是金士顿,硬盘只能是希捷,这对用户肯定是不友好的
- 根据依赖倒置原则进行改进:修改
Computer类,让Computer类依赖抽象(各个配件的接口),而不是依赖于各个组件具体的实现类
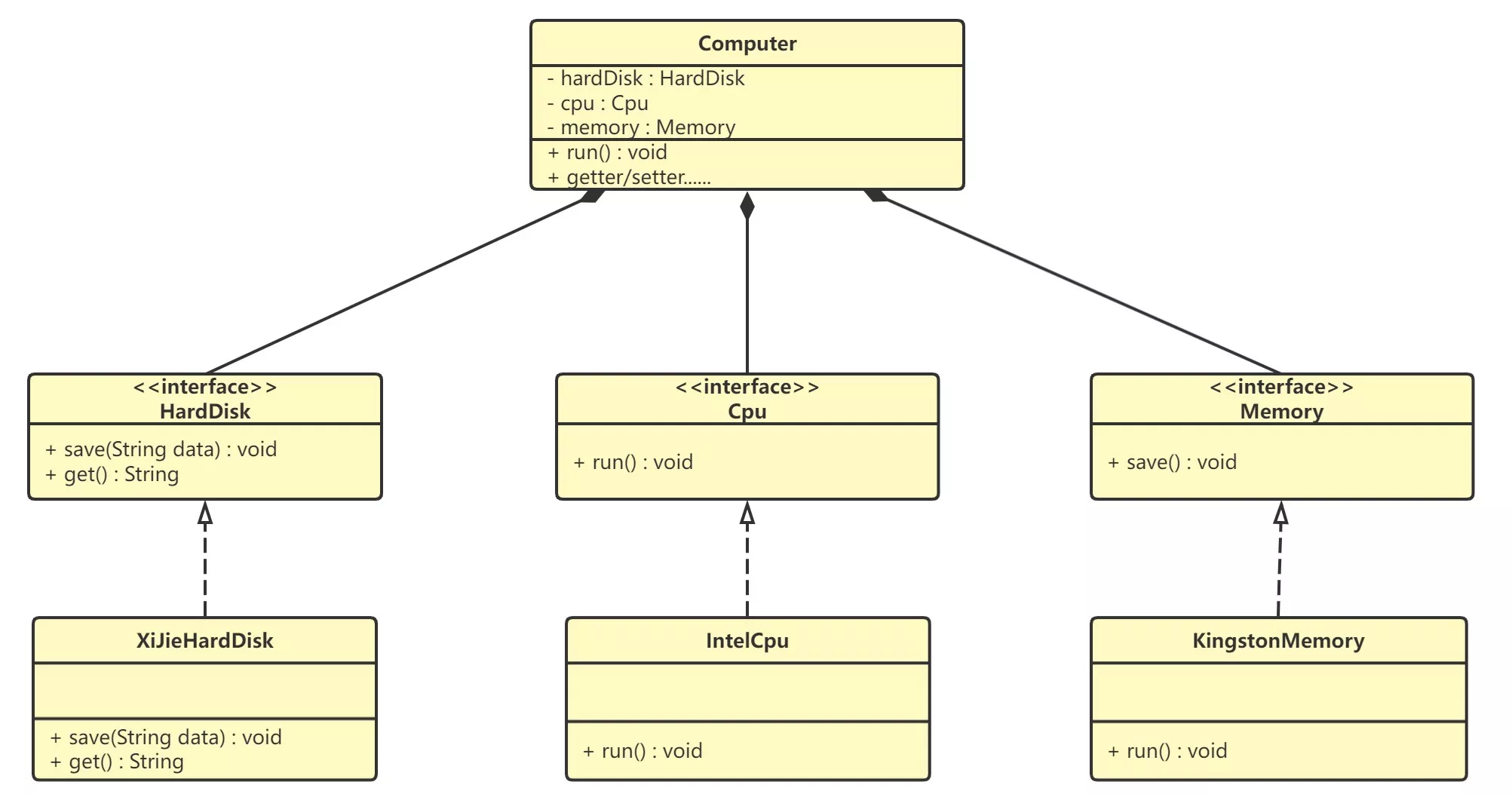
@Data
public class Computer {
private HardDisk hardDisk;
private Cpu cpu;
private Memory memory;
public void run() {
System.out.println("计算机工作");
}
}
关于依赖倒置、依赖注入、控制反转这三者之间的区别与联系
依赖倒置原则
- 是一种通用的软件设计原则,主要用来指导框架层面的设计
高层模块不依赖低层模块,它们共同依赖同一个抽象。抽象不要依赖具体实现细节,具体实现细节依赖抽象
控制反转
- 控制反转、依赖倒置有一些相似,它也是一种框架设计常用的模式,但并不是具体的方法
- “控制”:指对程序执行流程的控制
- “反转”:指在没有使用框架前,程序员自己控制整个程序的执行。使用框架后,整个程序的执行流程通过框架来控制。流程的控制权从程序员“反转”给框架
- Spring框架,核心模块IOC容器,就是通过控制反转这一种思想进行设计的
依赖注入
- 依赖注入是实现控制反转的一个手段,它是一种具体的编码技巧
- 不通过 new 的方式在类内部创建依赖的对象,而是将依赖的对象在外部创建好之后,通过构造函数等方式传递(或注入)进来,给类来使用
- 依赖注入真正实现了面向接口编程的愿景,可以很方便地替换同一接口的不同实现,而不会影响到依赖这个接口的客户端
7. 迪米特法则
1. 官方定义
- 1987年秋天,迪米特法则由美国Northeastern University的Ian Holland(伊恩 霍兰德)提出,被UML的创始者之一Booch(布奇)等人普及。后来,因为经典著作The PragmaticProgrammer 《程序员修炼之道》而广为人知
- 迪米特法则(LoD:Law of Demeter)又叫最少知识原则(LKP:Least Knowledge Principle ),指一个类/模块对其他的类/模块有越少的了解越好。简言之:talk only to your immediate friends(只跟你最亲密的朋友交谈),不跟陌生人说话
2. 通俗解释
- 思想:不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。
如果两个软件实体无须直接通信,就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性
- 在迪米特法则中,对于一个对象,非陌生人包括以下几类:
- 当前对象本身(this)
- 以参数形式传入到当前对象方法中的对象
- 当前对象的成员对象
- 如果当前对象的成员对象是一个集合,那么集合中的元素也都是朋友
- 当前对象所创建的对象
3. 场景示例
- 明星由于全身心投入艺术,所以许多日常事务由经纪人负责处理
- eg:和粉丝的见面会、和媒体公司的业务洽淡等。这里的经纪人是明星的朋友,而粉丝、媒体公司是陌生人
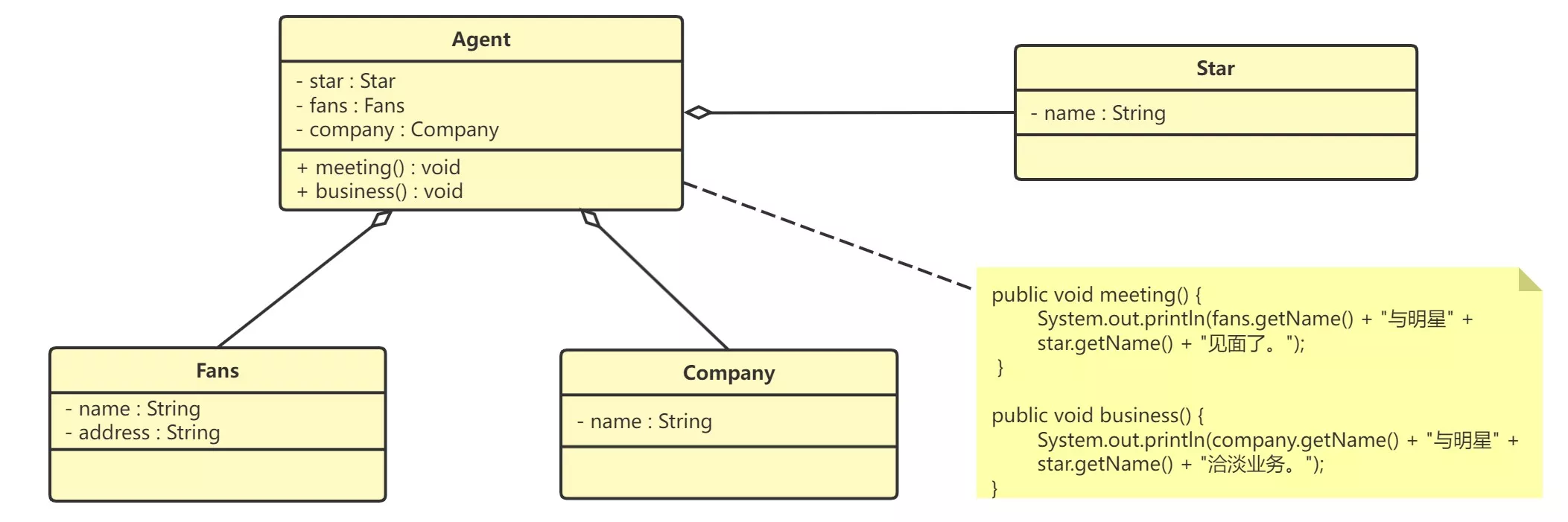
- 迪米特法则的独特之处在于它简洁而准确的定义,它允许在编写代码时直接应用,几乎自动地应用了适当的封装、高内聚和低耦合
- 但是,过度使用迪米特法则会使系统产生大量的中介类,从而增加系统复杂性,使模块间的通信效率降低。所以,在釆用迪米特法则时需要反复权衡,确保高内聚、低耦合的同时,保证系统的结构清晰
public class Star {
private String name;
public Star(String name) {
this.name=name;
}
}
public class Fans {
private String name;
public Fans(String name) {
this.name=name;
}
}
public class Company {
private String name;
public Company(String name) {
this.name=name;
}
}
public class Agent {
private Star star;
private Fans fans;
private Company company;
public void meeting() {
System.out.println(fans.getName() + "与明星" + star.getName() + "见面了。");
}
public void business() {
System.out.println(company.getName() + "与明星" + star.getName() + "洽淡业务。");
}
}