09-GC_Algorithm
1. 标记阶段
- Heap里存放着几乎所有的Obj实例,在GC之前,首先需要区分出内存中哪些是存活Obj,哪些是已经死亡Obj。只有被标记为己经死亡的Obj,GCtor才会GC,释放掉其所占用的内存空间,这个过程称为垃圾标记阶段
- 那么在JVM中究竟是如何标记一个死亡Obj呢?简单来说,当一个Obj已经不再被任何的存活Obj继续引用时,就可以宣判为已经死亡
- 判断Obj存活一般有两种方式
- 引用计数算法
- 可达性分析算法
1. 引用计数算法
- 引用计数算法(Reference Counting):对每个Obj保存一个整型的引用计数器属性。用于记录Obj被引用的情况
- 任何一个Obj引用了A,则A的引用计数器+1;当引用失效时,引用计数器-1。只要ObjA的引用计数器的值为0,即表示ObjA为垃圾,可进行回收
- 优点:实现简单,垃圾Obj便于辨识;判定效率高,回收没有延迟性
- 缺点:
- 需要单独的字段存储计数器,增加了存储空间的开销
- 每次赋值都需要更新计数器,伴随着加法和减法操作,这增加了时间开销
- 无法处理循环引用的情况。这是一条致命缺陷,GCtor中没有使用这类算法
Python如何解决循环引用?
- 手动解除:在合适的时机,解除引用关系
- 使用弱引用WeakRef,WeakRef是Python提供的标准库,旨在解决循环引用
1. 循环引用
当p的指针断开,内部的引用形成一个循环,造成内存泄漏
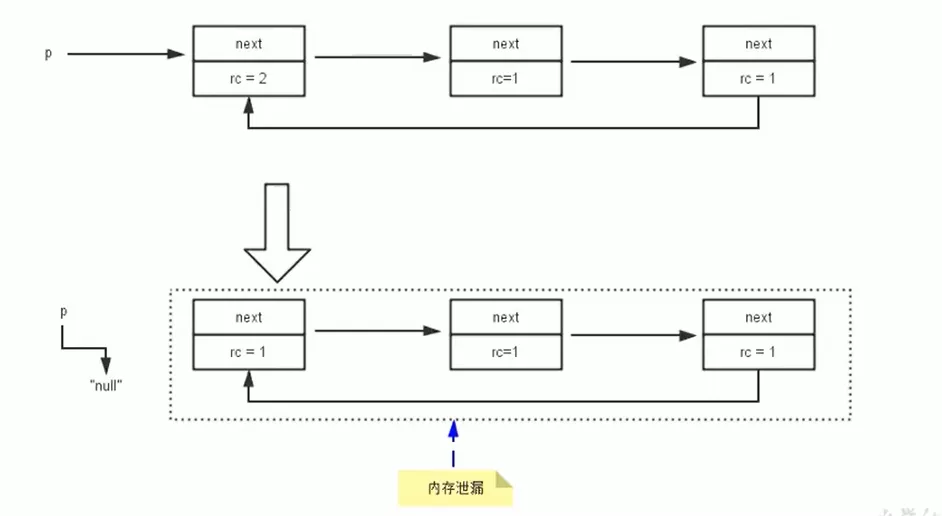
2. 循环引用GC
/*
* -XX:+PrintGCDetails
* 证明:Hotspot使用的不是引用计数算法
*/
public class RefCountGC {
// 这个成员属性唯一的作用就是占用一点内存
private byte[] bigSize = new byte[5 * 1024 * 1024]; // 5MB
Object reference = null;
public static void main(String[] args) throws InterruptedException {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
// 显式的执行垃圾回收行为
// 发生GC,obj1和obj2能否被回收?
System.gc();
Thread.sleep(1_000_000);
}
}
[GC (System.gc()) [PSYoungGen: 15490K->808K(76288K)] 15490K->816K(251392K), 0.0061980 secs] [Times: user=0.00 sys=0.00, real=0.36 secs]
[Full GC (System.gc()) [PSYoungGen: 808K->0K(76288K)] [ParOldGen: 8K->672K(175104K)] 816K->672K(251392K), [Metaspace: 3479K->3479K(1056768K)], 0.0045983 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
PSYoungGen total 76288K, used 655K [0x000000076b500000, 0x0000000770a00000, 0x00000007c0000000)
eden space 65536K, 1% used [0x000000076b500000,0x000000076b5a3ee8,0x000000076f500000)
from space 10752K, 0% used [0x000000076f500000,0x000000076f500000,0x000000076ff80000)
to space 10752K, 0% used [0x000000076ff80000,0x000000076ff80000,0x0000000770a00000)
ParOldGen total 175104K, used 672K [0x00000006c1e00000, 0x00000006cc900000, 0x000000076b500000)
object space 175104K, 0% used [0x00000006c1e00000,0x00000006c1ea8070,0x00000006cc900000)
Metaspace used 3486K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 385K, capacity 388K, committed 512K, reserved 1048576K
// 进行了GC,将新生代中的两个Obj进行回收
PSYoungGen: 15490K->808K(76288K)] 15490K->816K(251392K)
2. 可达性分析算法
- 可达性分析算法(Reachability Analysis)、根搜索算法、追踪性垃圾收集
- 不仅同样具备实现简单和执行高效等特点,更重要的是可以有效地解决在引用计数算法中循环引用的问题,防止内存泄漏发生
- 可达性分析是Java、C#的选择。这种类型的GC通常也叫作追踪性垃圾收集(Tracing Garbage Collection)
1. 思路
所谓"GC Roots”根集合就是一组必须活跃的引用
- 以根Obj集合(GC_Roots)为起始点,按照从上至下的方式搜索被根Obj集合所连接的目标Obj是否可达
- 使用可达性分析算法后,存活Obj都被GC_Roots直接或间接连接着,搜索所走过的路径称为引用链(Reference Chain)
- 如果目标Obj没有任何引用链相连,则是不可达的,就意味着该Obj己经死亡,可以标记为垃圾Obj
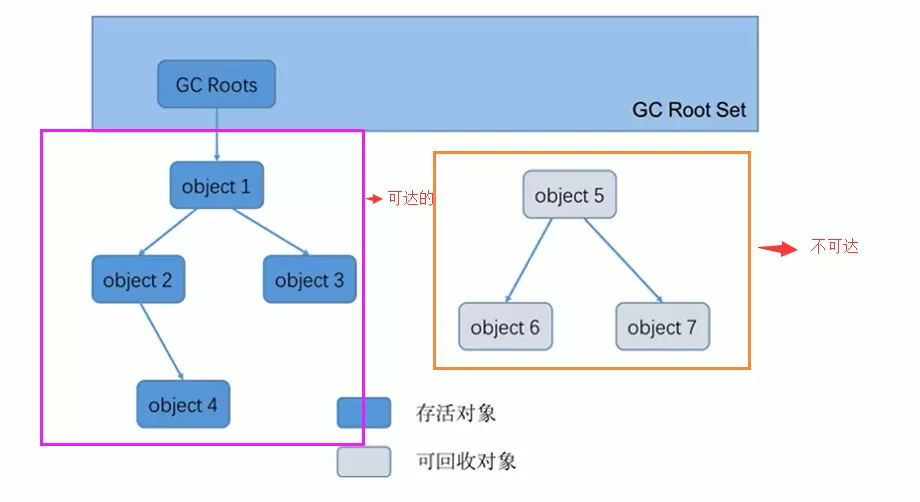
2. GC Roots哪些?
除了Heap外的一些结构,eg:虚拟机栈、本地方法栈、方法区、字符串常量池等对Heap进行引用的,都可以作为GC Roots进行可达性分析
- JVM_Stack中引用的Obj
- eg:各个线程调用的方法中使用到的参数、局部变量等
- 本地方法栈内JNI(native方法)引用的Obj
- 方法区中类静态属性引用的Obj
- eg:Java类的引用类型静态变量
- 方法区中常量引用的Obj
- eg:字符串常量池(String Table)里的引用
- 所有被同步锁
synchronized持有的Obj - JVM内部的引用
- 基本数据类型对应的ClassObj,一些常驻的异常Obj(eg:NullPointerException、OutOfMemoryError),系统类加载器
- 反映JVM内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等
- 除了这些固定的GC Roots集合以外,根据所选用的GCtor以及当前回收的内存区域不同,还可以有其他Obj“临时性”地加入,共同构成完整GC Roots集合
- eg:分代收集、局部回收(Partial GC)
- 如果只针对Heap中的某一块区域进行GC(eg:典型的只针对新生代),必须考虑到内存区域是JVM自己的实现细节,更不是孤立封闭的,这个区域的Obj完全有可能被其他区域的Obj所引用,这时候就需要一并将关联的区域Obj也加入GCRoots集合中去考虑,才能保证可达性分析的准确性
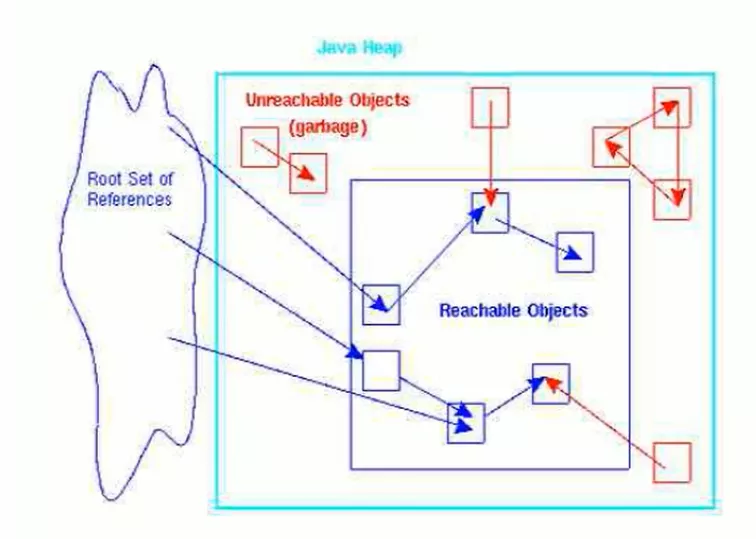
- 由于Root采用栈方式存放变量和指针,所以如果一个指针,保存了Heap里面的Obj,而自己又不在Heap里面,那它就是一个Root
- 如果要使用可达性分析算法来判断内存是否可回收,那么分析工作必须在一个能保障一致性的快照中进行。这点不满足的话分析结果的准确性就无法保证
- 这也是导致GC时必须“Stop The World”的重要原因。即使是号称(几乎)不会发生停顿的CMS收集器中,枚举根节点时也是必须要停顿的
2. 清除阶段
当成功区分出内存中存活Obj、死亡Obj后,GCtor执行垃圾回收,释放掉死亡Obj内存空间
JVM中比较常见的三种GC算法:
- 标记-清除算法(Mark-Sweep)
- 复制算法(Copying)
- 标记-压缩算法(Mark-Compact)
1. Mark-Sweep
标记-清除算法(Mark-Sweep):是一种非常基础、常见的GC算法,该算法被J.McCarthy等人在1960年提出并应用于Lisp语言
Heap中的有效内存空间(available memory)被耗尽时,就会STW,然后进行两项工作
- 标记:GCtor从Root开始遍历,标记所有被引用的Obj。一般是在Obj的Header中记录为可达Obj
- 清除:GCtor对Heap从头到尾进行线性的遍历,回收不可达Obj
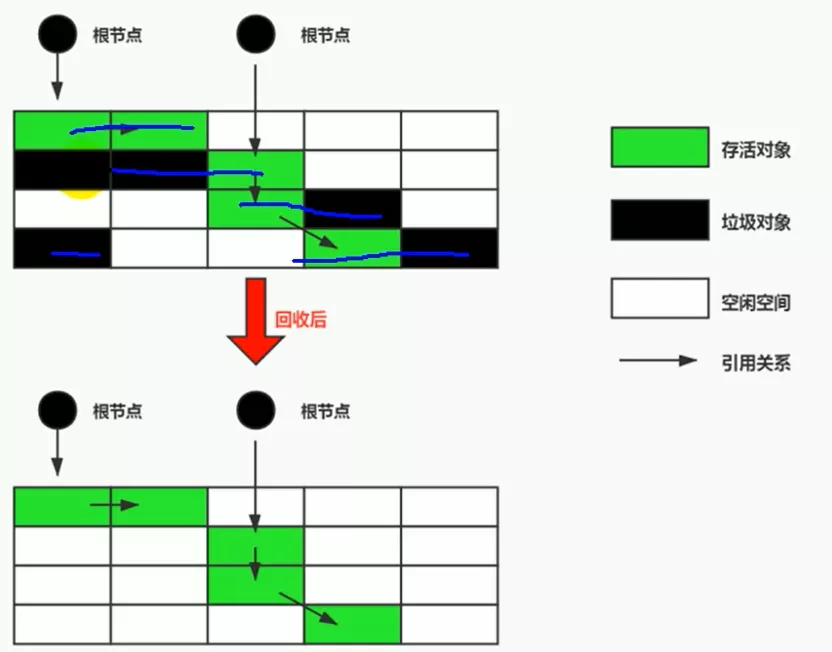
1. 清除?
清除并不是真的置空,而是把清除Obj地址保存在空闲地址列表里。下次有新Obj加载时,判断垃圾的位置空间如果够,覆盖原有的地址
- 如果内存规整
- 采用指针碰撞的方式进行内存分配
- 如果内存不规整
- JVM需要维护一个列表,空闲列表分配
2. 缺点
- 效率不算高
- 在进行GC时,STW,用户体验较差
- 产生内存碎片,需要维护一个空闲列表
2. Copying
- 背景
- 解决《标记-清除算法》在GC效率方面的缺陷,M.L.Minsky于1963年发表了著名的论文,“使用双存储区的Lisp语言垃圾收集器CA LISP Garbage Collector Algorithm Using Serial Secondary Storage)”。M.L.Minsky在该论文中描述的算法被人们称为复制(Copying)算法,它也被M.L.Minsky本人成功地引入到了Lisp语言的一个实现版本中
- 核心思想
- 将活着的内存空间分为两块。GC时,将正在使用的内存中的存活Obj复制到未被使用的内存块中,之后清除正在使用的内存块中的所有Obj,交换两个内存的角色,完成GC
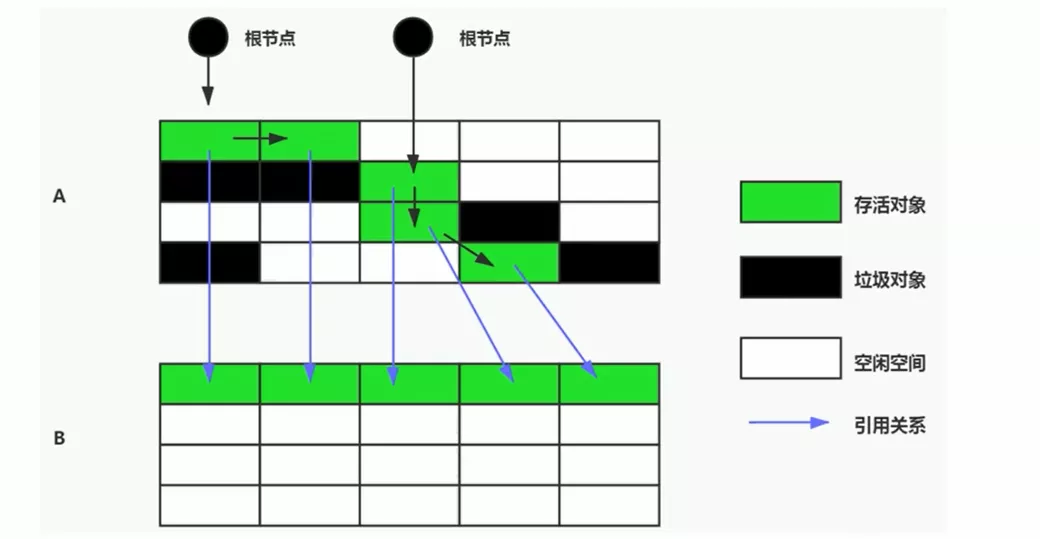
把可达Obj,直接复制到另外一个区域中。复制完成后,A区就没有用了,里面的Obj可以直接清除掉,其实新生代就用Copying
- 优点
- 没有标记、清除过程,实现简单,运行高效
- 不会出现内存碎片
- 缺点
- 需要两倍的内存空间
- 对于G1分拆成为大量Region的GCtor,复制而不是移动,意味着GC需要维护Region之间Obj引用关系,内存占用、时间开销也不小
- 如果系统中的垃圾Obj很多,Copying需要复制的存活Obj数量非常低(老年代大量的Obj存活,那么复制很多,效率很低)
- 在新生代,对常规应用的GC,一次通常可以回收70% - 99%的内存空间。回收性价比很高。所以现在的商业JVM都用Copying回收新生代
3. Mark-Compact
标记-压缩(整理)算法
- Copying的高效性是建立在存活Obj少、垃圾Obj多的前提下。适合新生代GC。老年代,大部分都是存活Obj。使用Copying,存活Obj较多,复制成本很高
- 1970年前后,G.L.Steele、C.J.Chene、D.s.Wise等研究者发布标记-压缩算法
- 第一阶段:和标记清除算法一样,从根节点开始标记所有被引用Obj
- 第二阶段:将所有的存活Obj压缩到内存的一端,按顺序排放。之后,清理边界外所有的空间
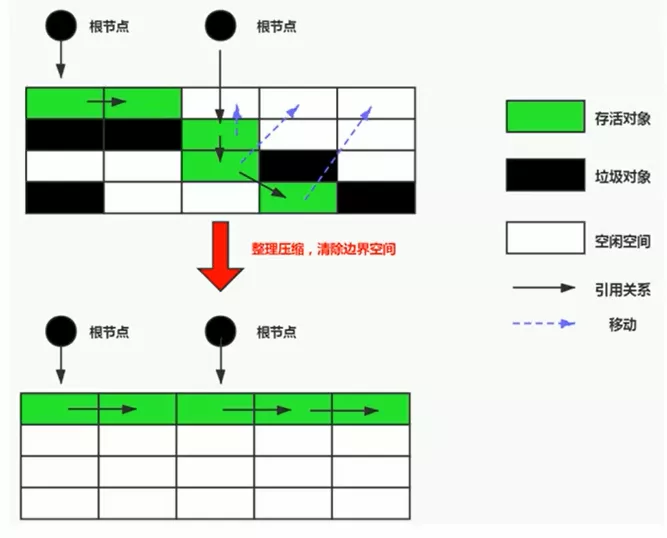
标清、标整本质差异
- 标记-清除算法是一种非移动式的回收算法,标记-压缩是移动式的。是否移动是一项优缺点并存的风险决策
- 标记的存活Obj将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,给新Obj分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销
- 优点
- 消除了Mark-Sweep中,内存区域分散的缺点
- 消除了Copying中,内存减半的高额代价
- 缺点
- 效率低于Copying
- 移动Obj的同时,如果Obj被其他Obj引用,则还需要调整引用的地址
- 移动过程中,需要STW
4. 小结
- 效率上来说,Copying是当之无愧的老大,但是却浪费了太多内存
- 而为了尽量兼顾上面提到的三个指标,Mark-Compact相对来说更平滑一些,但是效率上不尽如人意,它比Copy多了一个标记的阶段,比Mark-Sweep多了一个整理内存的阶段
| Mark-Sweep | Mark-Compact | Copying | |
|---|---|---|---|
| 速率 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(堆积碎片) | 少(不堆积碎片) | 活Obj的2倍空间(不堆积碎片) |
| 移动Obj | 否 | 是 | 是 |
3. 分代收集算法
没有一种算法可以完全替代其他算法,都有自己独特的优势和特点。分代收集算法应运而生
- 分代收集算法:不同Obj生命周期是不一样的。因此,不同生命周期Obj可以采取不同的收集方式,以便提高回收效率。一般是把Heap分为新生代、老年代,根据各个年代的特点使用不同的GC算法,以提高GC效率
- 程序运行中,产生大量的Obj,其中有些Obj是与业务信息相关(eg:Http请求中的SessionObj、线程、Socket连接,这类Obj跟业务直接挂钩),因此生命周期较长。但是还有一些Obj,是程序运行过程中生成的临时变量,这些Obj生命周期较短,甚至只用一次即可回收(eg:StringObj,由于其不变类的特性,系统会产生大量的这些Obj)
目前几乎所有的GC都采用分代收集(Generational Collectioning)算法,执行垃圾回收。HotSpot中,基于分代的概念,GC所使用的内存回收算法必须结合年轻代、老年代各自的特点
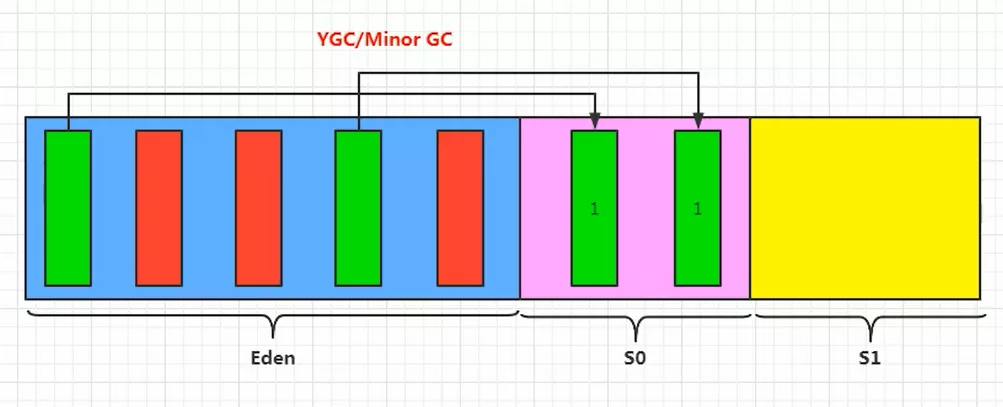
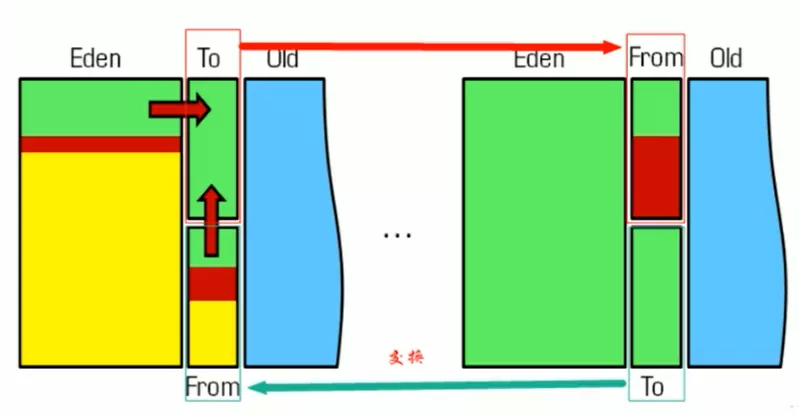
- 年轻代(Young Gen)
- 特点:区域相对较小,Obj生命周期短、存活率低,回收频繁
- Copying的回收整理,速度是最快的。效率只和当前存活Obj大小有关,因此很适用于年轻代的回收。而Copying内存利用率不高的问题,通过Hotspot中的两个Survivor的设计得到缓解
- 老年代(Tenured Gen)
- 特点:区域较大,Obj生命周期长、存活率高,回收不频繁
- 存在大量存活率高的Obj,Copying明显变得不合适。一般是由《标记-清除》《标记-清除、标记-整理》的混合实现
- Mark阶段开销,与存活Obj的数量成正比
- Sweep阶段开销,与所管理区域的大小成正相关
- Compact阶段开销,与存活Obj的数量成正比
以HotSpot中的CMS回收器为例,CMS是基于Mark-Sweep实现,Obj的回收效率很高。而对于碎片问题,采用基于Mark-Compact的Serial_Old作为补偿措施,当内存回收不佳(碎片导致的Concurrent Mode Failure时),将采用Serial_Old执行FullGC以达到对老年代内存的整理
4. 增量收集算法
- 上述现有算法,在GC过程中,应用软件将处于STW状态。如果GC时间过长,应用程序会被挂起很久,将严重影响用户体验或者系统的稳定性。为了解决这个问题,即对实时GC算法的研究,直接导致了增量收集(Incremental Collecting)算法的诞生
- 如果一次性将所有的垃圾进行处理,需要造成系统长时间的停顿,那么就可以让GC线程和应用程序线程交替执行。每次,GC线程只收集一小片区域的内存空间,接着切换到应用程序线程。依次反复,直到GC完成
- 总的来说,增量收集算法的基础仍是传统的Mark-Sweep和Copying。增量收集算法通过对线程间冲突的妥善处理,允许GC线程以分阶段的方式完成标记、清理或复制工作
- 缺点:这种方式,由于在GC过程中,间断性地还执行了应用程序代码,所以能减少系统的停顿时间。但是,因为线程切换和上下文转换的消耗,会使得GC的总体成本上升,造成系统吞吐量下降
5. 分区算法
- 相同条件下,Heap越大,一次GC时所需时间就越长,STW也越长。为了更好地控制GC产生的停顿时间,将一块大的内存区域分割成多个小块,根据目标的停顿时间,每次合理地回收若干个小区间,而不是整个Heap,从而减少STW
- 分代算法:将按照Obj的生命周期长短划分成两个部分
- 分区算法:将整个Heap划分成连续的不同Region,每个Region都独立使用,独立回收。好处是可以控制一次回收多少个小区间
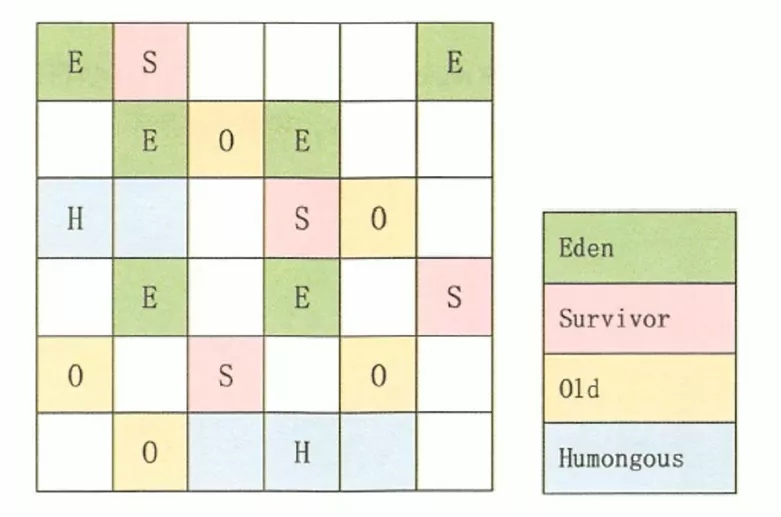
6. finalization机制
- Java语言提供了Obj终止(finalization)机制,允许开发人员提供Obj被销毁之前的自定义处理逻辑
- 当GCtor发现没有引用指向一个Obj。即:GC此Obj之前,总会先调用这个Obj的
finalize() finalize()方法允许在子类中被重写,用于在Obj被回收时进行资源释放。通常这个方法进行一些资源释放和清理的工作- eg:关闭文件、套接字、数据库连接等
永远不要主动调用某个Obj的finalize(),应该交给GC机制调用。理由包括下面三点:
finalize()可能会导致Obj复活finalize()执行时间是没有保障的,完全由GC线程决定,极端情况下,若不发生GC,则finalize()将没有执行机会- 因为优先级比较低,即使主动调用该方法,也不会因此就直接进行回收
- 一个糟糕的
finalize()会严重影响GC性能
1. Obj三种状态
从所有的根节点都无法访问到某个Obj。一般来说,此Obj需要被回收。但事实上,也并非是“非死不可”的,它们暂时处于“缓刑”阶段。一个无法触及的Obj有可能在某一个条件下“复活”自己,JVM由于finalize()的存在,Obj一般处于三种可能的状态:
- 可达状态:从根节点开始,可以到达这个Obj
- 可恢复状态:Obj的所有引用都被释放,但可能在
finalize()中复活 - 不可达状态:Obj的
finalize()被调用,并且没有复活。finalize()只会被调用一次
以上3种状态,只有在Obj不可触及时才可以被回收

2. 具体过程
判定一个ObjA是否可回收,至少要经历两次标记过程:
- 如果ObjA到GC Roots没有引用链,则进行第一次标记
- 进行筛选,执行
finalize()方法- 没有重写
finalize(),或者finalize()已经被JVM调用过。ObjA被判定为不可触及的 - 重写了
finalize(),且还未执行过。那么ObjA会被插入到F-Queue队列,由一个JVM自动创建的、低优先级的Finalizer线程,执行finalize() finalize()是Obj逃脱死亡的最后机会。稍后GC会对F-Queue队列中的Obj进行第二次标记,如果ObjA在finalize()中与引用链上的任何一个Obj建立了联系,那么在第二次标记时,ObjA会被移出“即将回收”集合。之后,对象会再次出现没有引用存在的情况。在这个情况下,finalize不会被再次调用,Obj会直接变成不可触及的状态,也就是说,一个Obj的finalize只会被调用一次
- 没有重写
Finalizer线程(JVM自动创建的、低优先级的线程)
3. code
重写finalize(),然后在方法的内部,将其关联到GC Roots中
/**
* 测试finalize(),即finalization机制
*/
public class CanReliveObj {
public static CanReliveObj obj; // 类变量,属于GC_Root
// finalize()只能被调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()");
obj = this; // 当前待回收的Obj与引用链上的obj建立了联系
}
public static void main(String[] args) throws InterruptedException {
obj = new CanReliveObj();
// Obj第一次成功拯救自己
obj = null;
System.gc();
System.out.println("第1次 gc");
// Finalizer线程优先级很低,暂停2秒,等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is null");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 此次自救却失败了
obj = null;
System.gc();
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is null");
} else {
System.out.println("obj is still alive");
}
}
}
进行第一次清除时,会执行finalize(),Obj进行了一次自救。finalize()只会被调用一次,因此第二次该Obj将会被GC掉
第1次 gc
调用当前类重写的`finalize()`方法
obj is still alive
第2次 gc
obj is dead
7. dump文件
1. Create
1. jmap
public class GCRootsTest {
public static void main(String[] args) throws InterruptedException {
List<Object> numList = new ArrayList<>();
Date birth = new Date();
for (int i = 0; i < 100; i++) {
numList.add(String.valueOf(i));
Thread.sleep(10);
}
System.out.println("数据添加完毕,请操作:");
new Scanner(System.in).next();
numList = null;
birth = null;
System.out.println("numList、birth已置空,请操作:");
new Scanner(System.in).next();
System.out.println("结束");
}
}
➜ java git:(master) ✗# jps
3680 GCRootsTest
753 RemoteMavenServer36
3777 Jps
711
3679 Launcher
➜ java git:(master) ✗# jmap -dump:format=b,live,file=test1.bin 3680
Dumping heap to /Users/list/mca_proj/tmp/target/classes/com/listao/jvm/chapter09/java/test1.bin ...
Heap dump file created
2. JVisualVM
- 捕获的 heap_dump 文件是一个临时文件,关闭
JVisualVM后自动删除,若要保留,需要将其另存为文件 - 通过以下方法捕获 heap_dump:
- 在左侧
Application(应用程序)子窗口中,右击相应的应用程序,选择Heap_Dump(堆Dump) - 在
Monitor(监视)子标签页中,点击Heap_Dump(堆Dump)按钮
- 在左侧
- 本地应用程序的
Heap_dumps作为应用程序标签页的一个子标签页打开。同时,heap_dump在左侧的Application(应用程序)栏中对应一个含有时间戳的节点。右击这个节点选择save_as(另存为)即可将heap_dump保存到本地
2. MAT打开Dump
- 官网下载
- MAT(Memory Analyzer)是一款功能强大的Heap内存分析器。用于查找内存泄漏以及查看内存消耗情况。基于Eclipse开发的,是一款免费的性能分析工具
可以看到有哪些可以作为GC_Roots的Obj,能够看到有一些常用的Java类,然后Thread线程
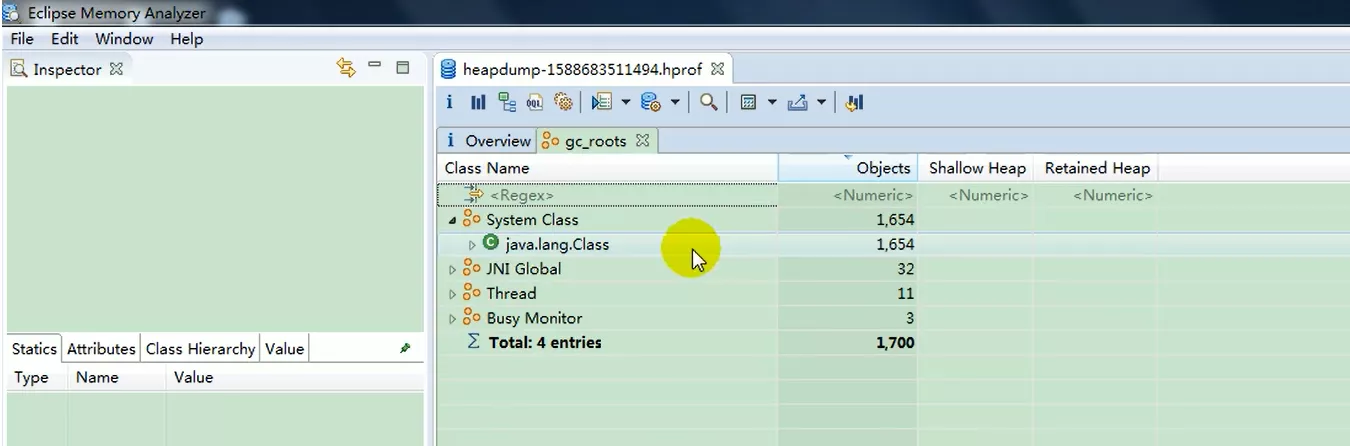
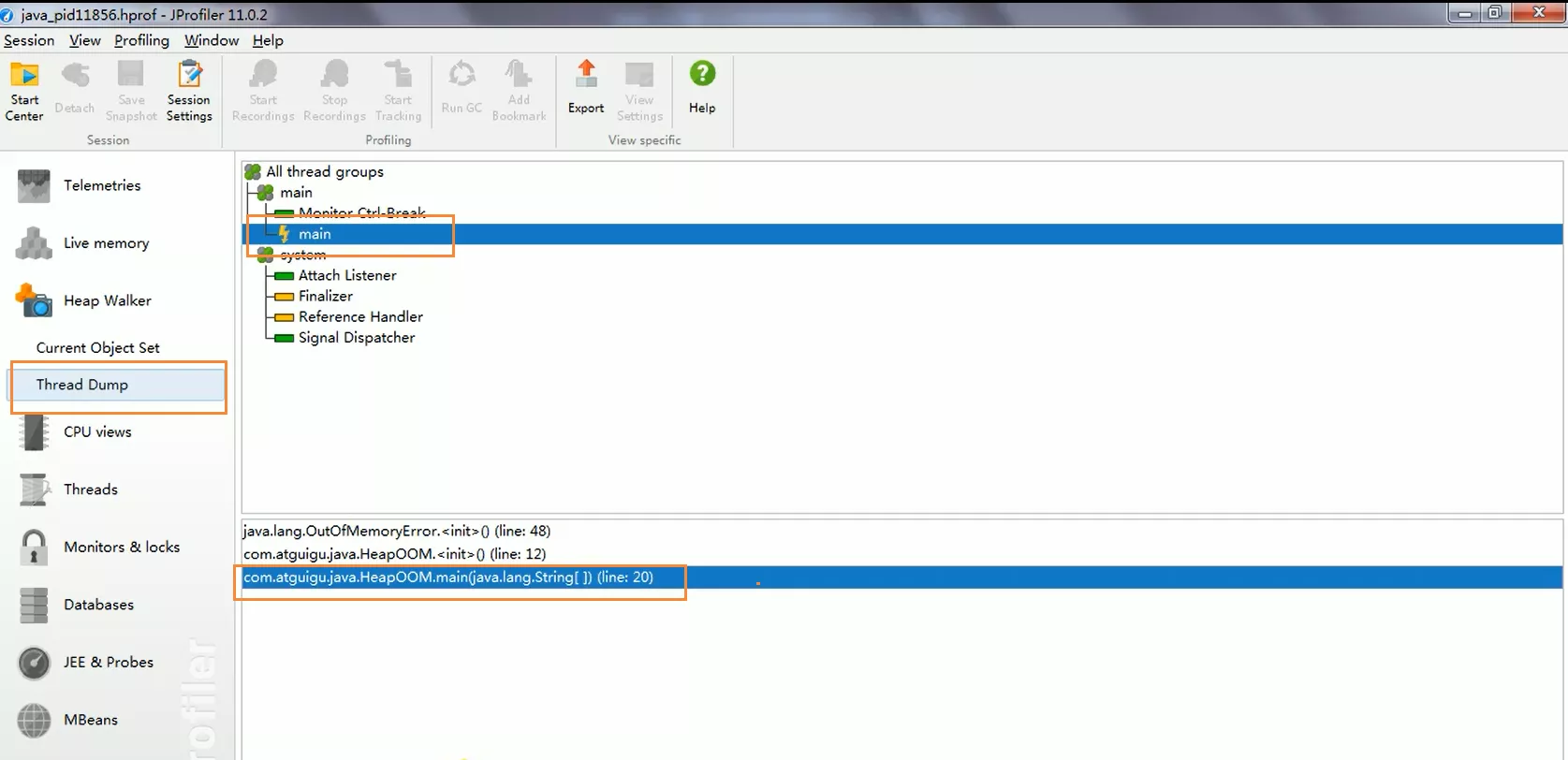
3. JProfiler
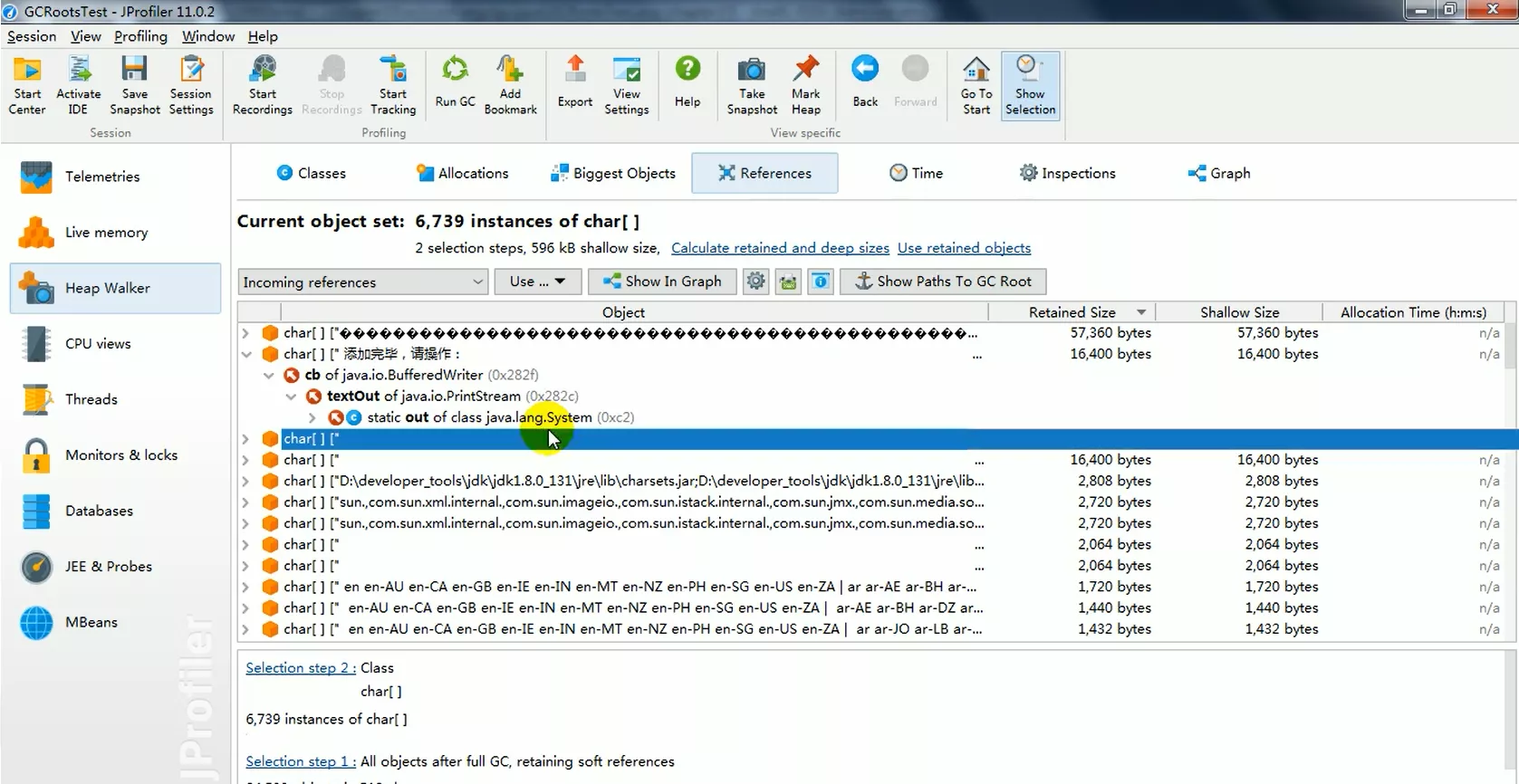
1. GC_Roots溯源
实际开发中,一般不会查找全部的GC_Roots,可能只查找某个Obj的整个链路,称为GC_Roots溯源。可以使用JProfiler
2. OOM
- 当程序出现OOM时,进行排查
-XX:+HeapDumpOnOutOfMemoryError将出错时的dump文件输出
/**
* 内存溢出排查
* -Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
*/
public class HeapOOM {
byte[] buffer = new byte[1 * 1024 * 1024]; // 1MB
public static void main(String[] args) {
ArrayList<HeapOOM> list = new ArrayList<>();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Throwable e) {
System.out.println("count = " + count);
e.printStackTrace();
}
}
}
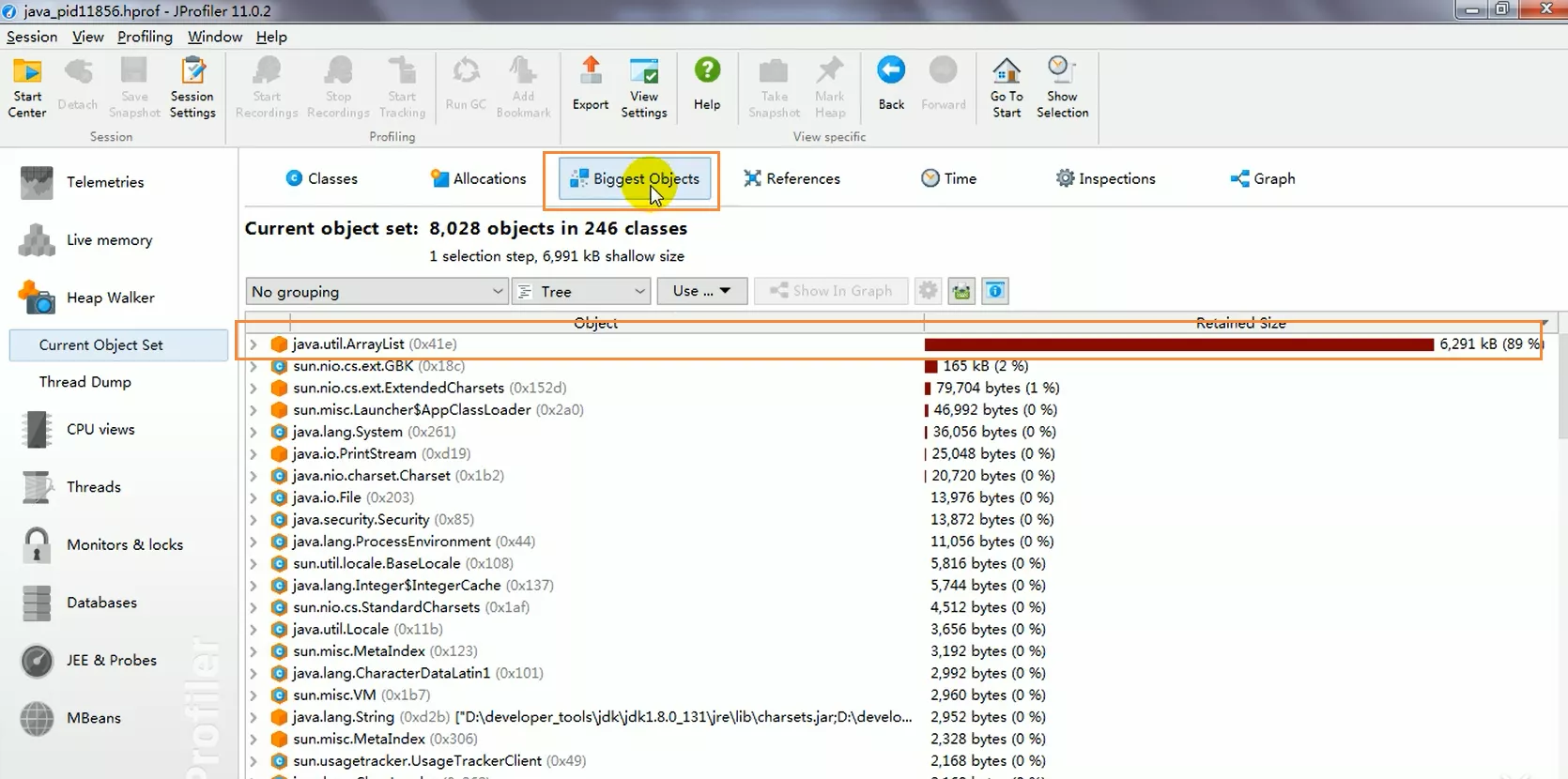
打开dump文件,然后点击Biggest Objects就能够看到超大Obj
然后通过线程,定位到哪里出现OOM