14-存储优化
除了性能优化外,还有很多项目优化的方法,比如存储优化、可用性优化、稳定性优化、易用性优化、体验优化、成本优化、安全性优化等等
1. 存储优化思路
存储是一个很广泛的概念,有很多种存储技术,比如数据库存储、内存存储、对象存储、块存储、文件存储等。
- 存储空间优化
- 存储成本优化
- 存储安全性优化
- 存储可用性优化
- 存储可靠性优化
- 存储性能优化
1. 通用存储优化手段
1. 存储空间优化
- 压缩:使用压缩算法对数据进行压缩,减小存储空间的占用。常见的压缩算法有 gzip、zstd 等
- 分区分表:常用于数据库和大数据存储,将大量数据分别存放于不同的分区和表中,从而提高单表查询性能,并减小单表数据量
- 数据清理(归档):定期清理过期或不再需要的数据。或者将不常用的数据归档到其他存储中
- 数据去重:去除重复的数据或复用数据,常用于网盘系统的实现(eg:秒传功能)
2. 存储成本优化
存储成本优化:除了空间方面的考虑外,还要考虑存储管理和维护成本、设备成本、使用成本等,目标是在提供足够性能和可用性的前提下,降低整个存储系统的总体成本
- 选择合适的存储技术:专业的存储服务特定的业务。eg:用图数据库存储关联数据、向量数据库存储向量数据,往往“事半功倍”
- 合理采购存储资源:从需求和业务出发,评估存储用量,避免过度购买存储资源
3. 存储安全性优化
保护存储数据的完整、安全,防止数据泄露等
- 数据加密:使用合适的加密算法确保数据在存储过程、存储对象上的安全性
- 备份恢复:定期备份数据,以便在数据丢失或损坏时能够迅速恢复
- 访问控制:设置合适的权限和访问控制策略,确保只有授权用户能够访问存储的数据
- 日志审计:记录关键操作的日志,便于出现问题后的故障定位。还可以通过定期查阅日志,提前发现一些潜在的问题
4. 其他优化
- 存储可用性优化:保证存储系统在任何时候都能正常提供服务,常用方法有容错、冗余备份、故障转移、快速故障检测恢复等
- 存储可靠性优化:保证数据的完整性和系统地稳定性。可以通过在底层选用高可靠的硬件设备来实现
- 存储性能优化:提高存储系统的读写速度、降低响应延迟等
- 存储管理优化:提高操作存储、配置和监控存储资源的有效性,可以通过自动化管理工具实现
- 存储可观测性优化:更好地检测存储系统的运行状态、资源占用和行为。可以通过可视化监控看板、完备的日志和告警系统实现
2. 存储空间优化
1. 分析
- 文件压缩:将多个模板文件压缩打包后上传,这点之前我们已经实现了
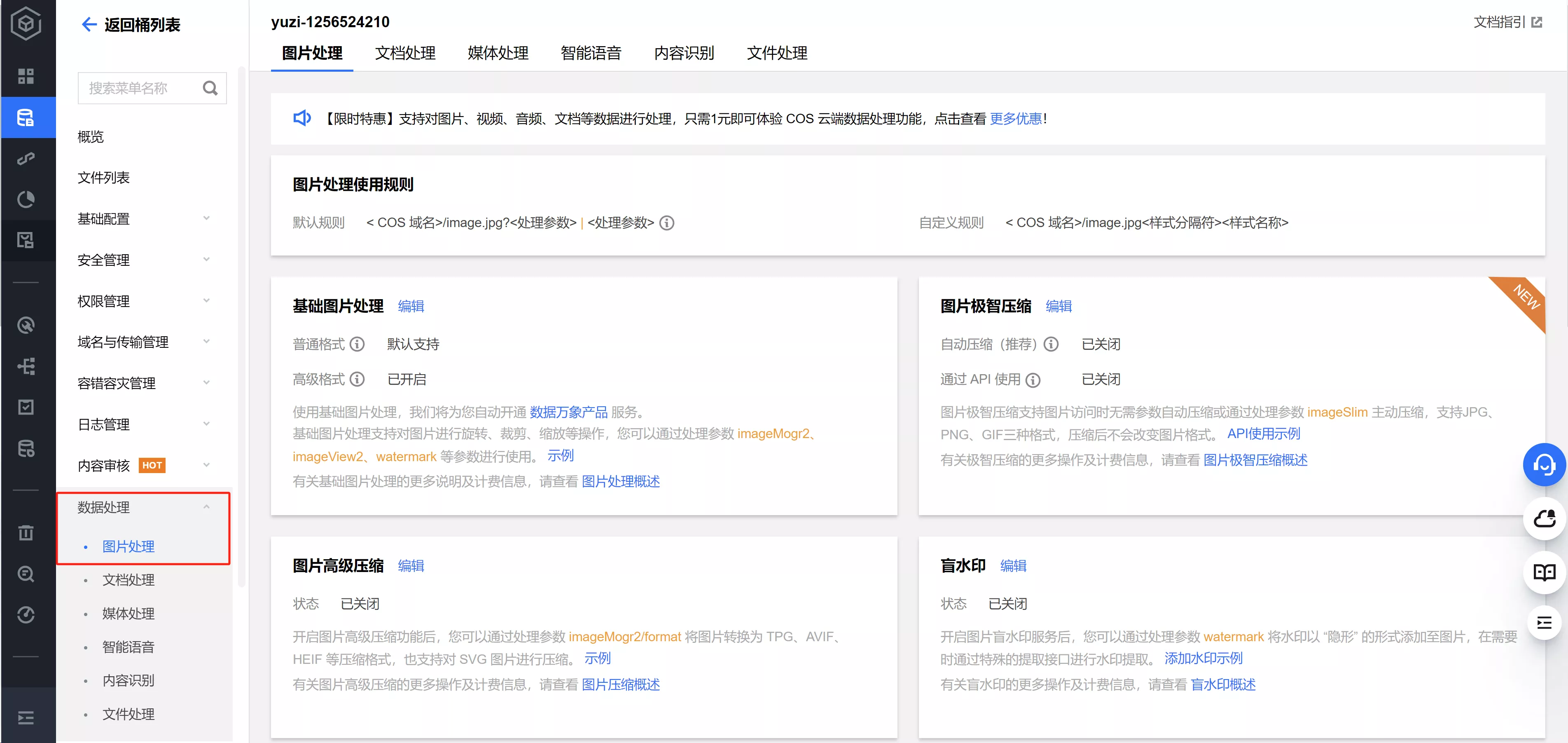
- 官方 COS 官方强烈推荐的方式 自带了图像自动压缩处理的功能(数据万象),配置下即可
- 文件瘦身:除了压缩文件减少文件体积外,还可以精简文件本身的体积
- eg:制作工具项目中,我们额外生成了一个 dist 目录作为产物包,移除了不必要的源码文件
- 数据去重:可以通过文件的 MD5 值判断是否已存在相同的文件,如果重复就不再上传,而是将新文件的路径指向已有文件。类似秒传的实现原理,但是实现成本比较高
- 文件清理:定期清理项目中不需要的文件。业务开发中最常用的一种方式
2. 文件清理机制设计
首先明确需求,感受下 2 种需求描述的差异:
- 需求 1:定期清理无用文件
- 需求 2: 每天清理所有无用的文件,包括用户上传的模板制作文件(generator_make_template)、已删除的代码生成器对应的产物包文件(generator_dist)
然后再进行方案设计,关键要考虑 2 个问题:
- 如何触发任务的定时执行?
- 分布式任务调度系统
- 如何高效删除文件?
- 整体删除文件目录
- 批量删除
扩展:思考定时批量删除会不会有什么问题?eg:刚上传就删了?
日期作为目录,整个删除?
3. 分布式任务调度系统
1. 是什么?
- 专用于协调和执行分布式场景中任务的系统
- 主流的分布式任务调度系统有 XXL-JOB、Elastic Job 等
2. XXL-JOB介绍
- 是一个非常成熟的开源定时任务调度系统,有几万个 star
- 优点:易学、易用、易部署、易扩展,经过多家知名公司生产环境的验证
- 官方文档写得非常好,强烈推荐阅读
3. XXL-JOB安装
- 下载项目源码 使用 Gitee
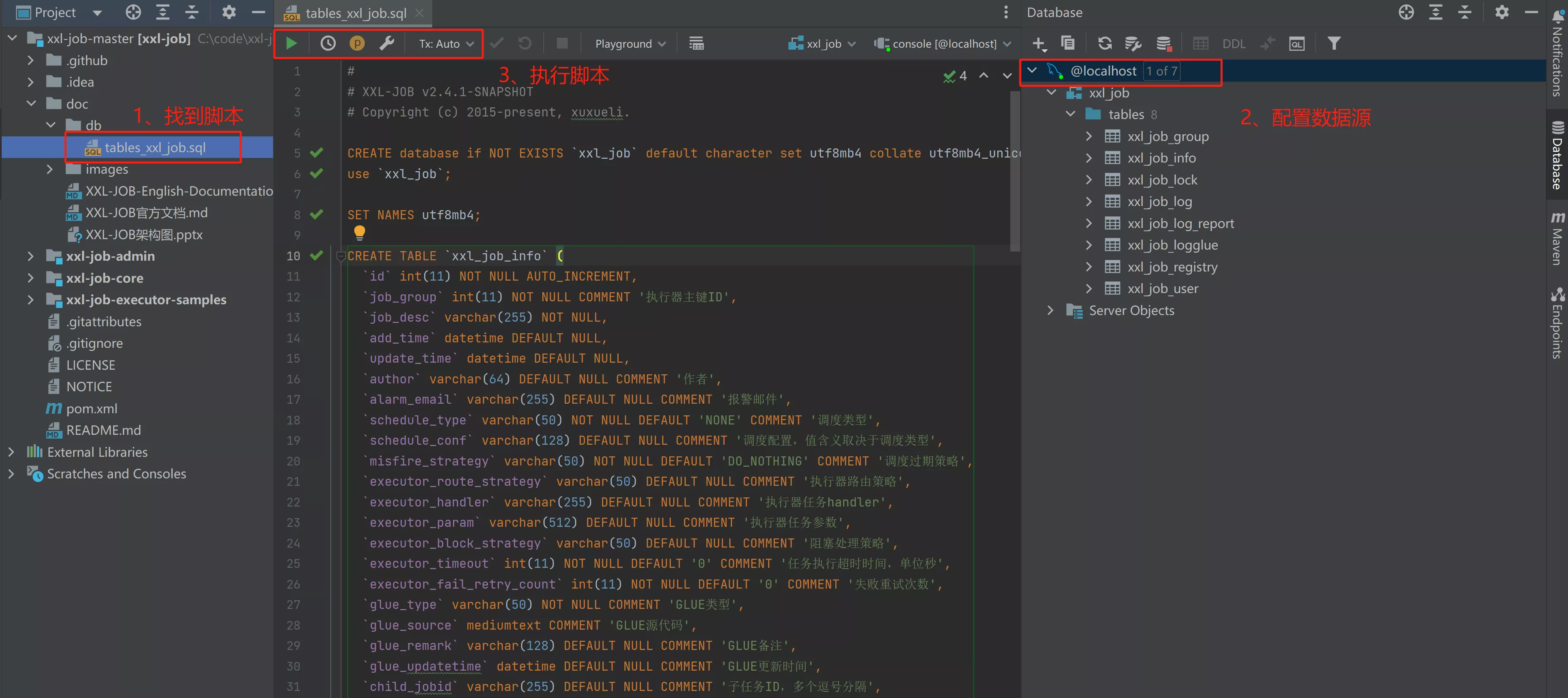
- 执行初始化数据库脚本
- 在项目根路径下
/doc/db/tables_xxl_job.sql文件
- 在项目根路径下
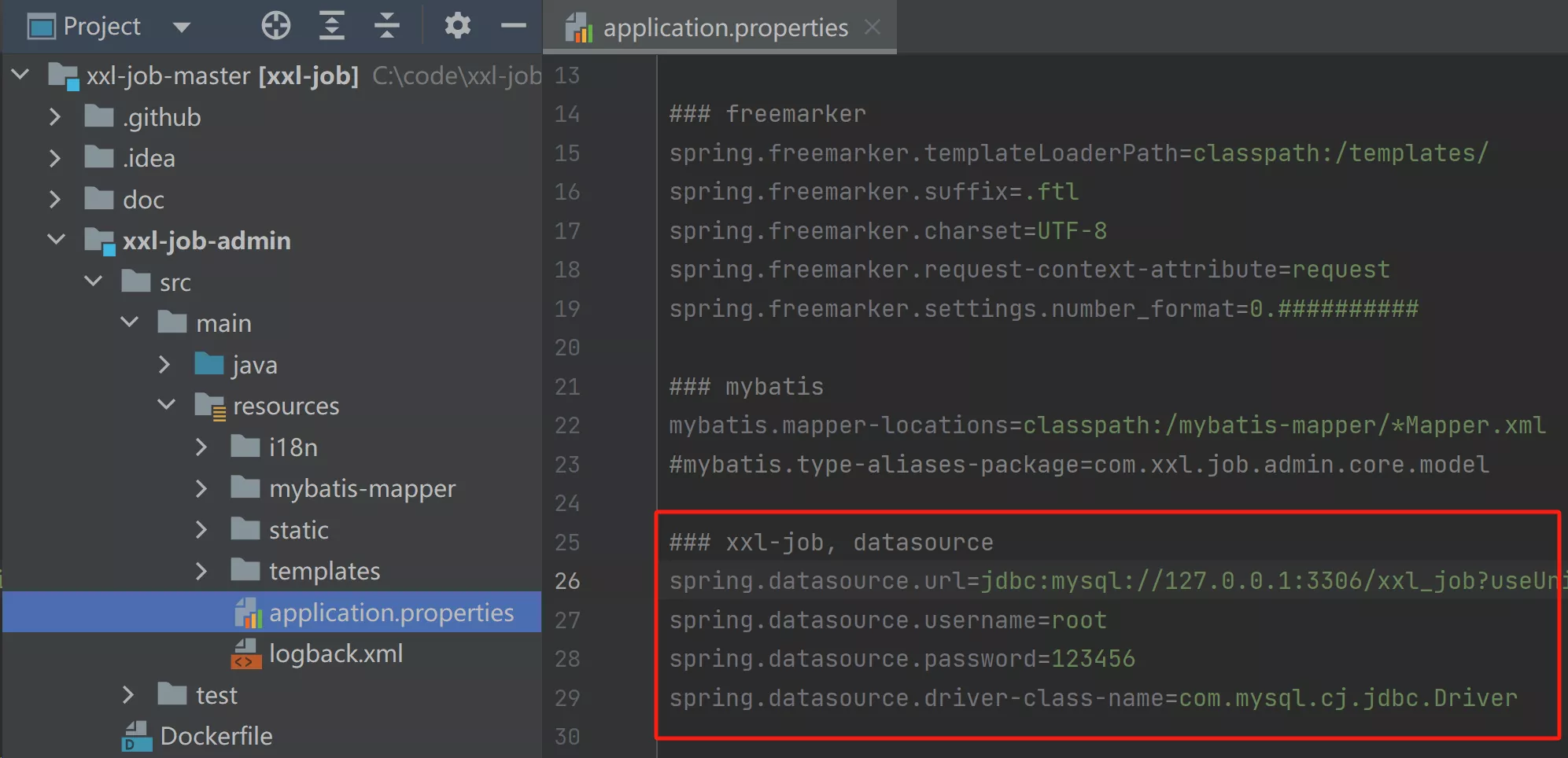
- 修改数据库配置信息
- 修改
xxl-job-admin目录下的application.properties配置文件
- 修改
- 启动项目
- 找到
xxl-job-admin的入口类并运行
- 找到
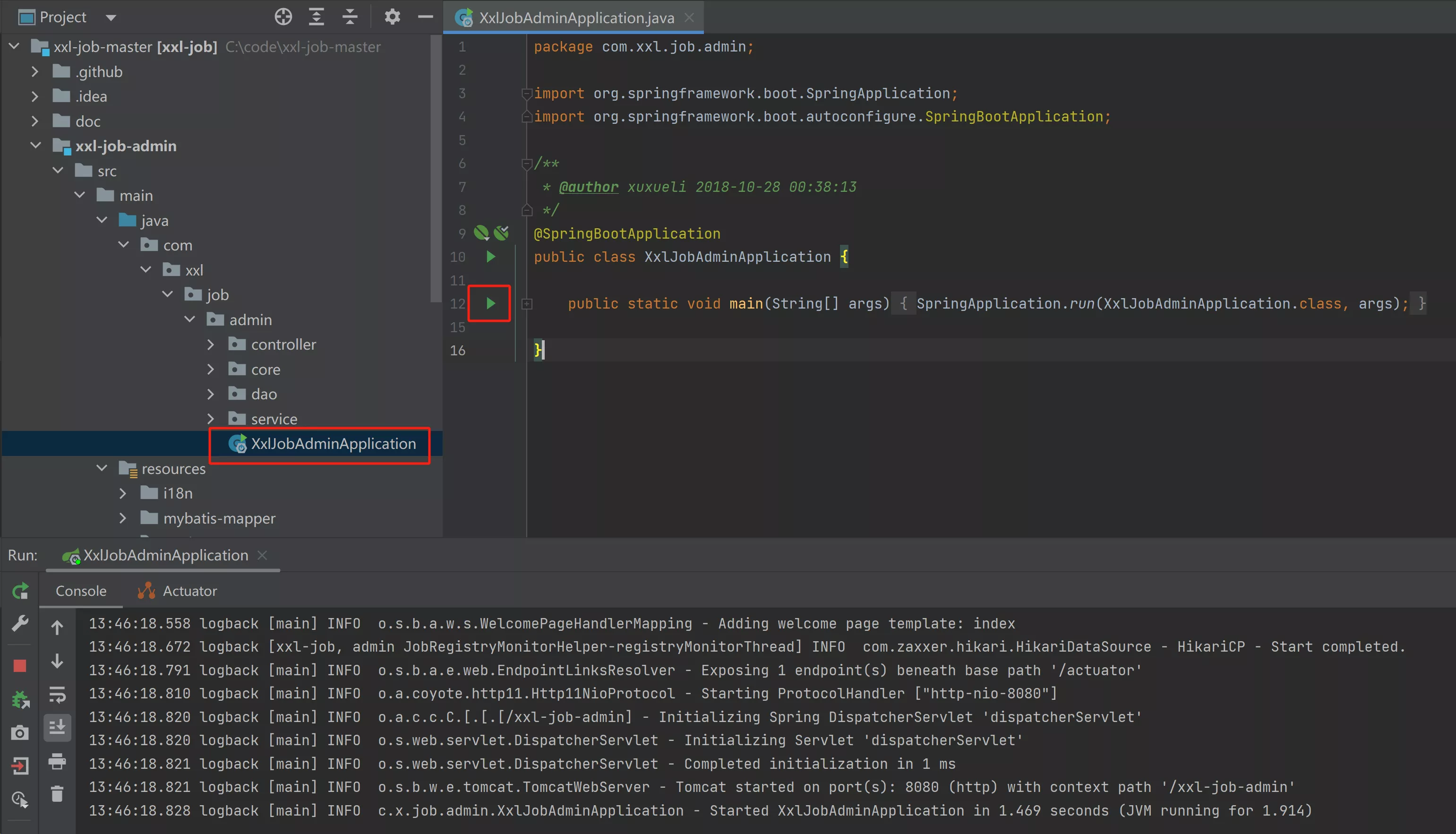
Mac 电脑修改:xxl-job-admin 的 logback.xml 文件,将绝对路径 / 即可
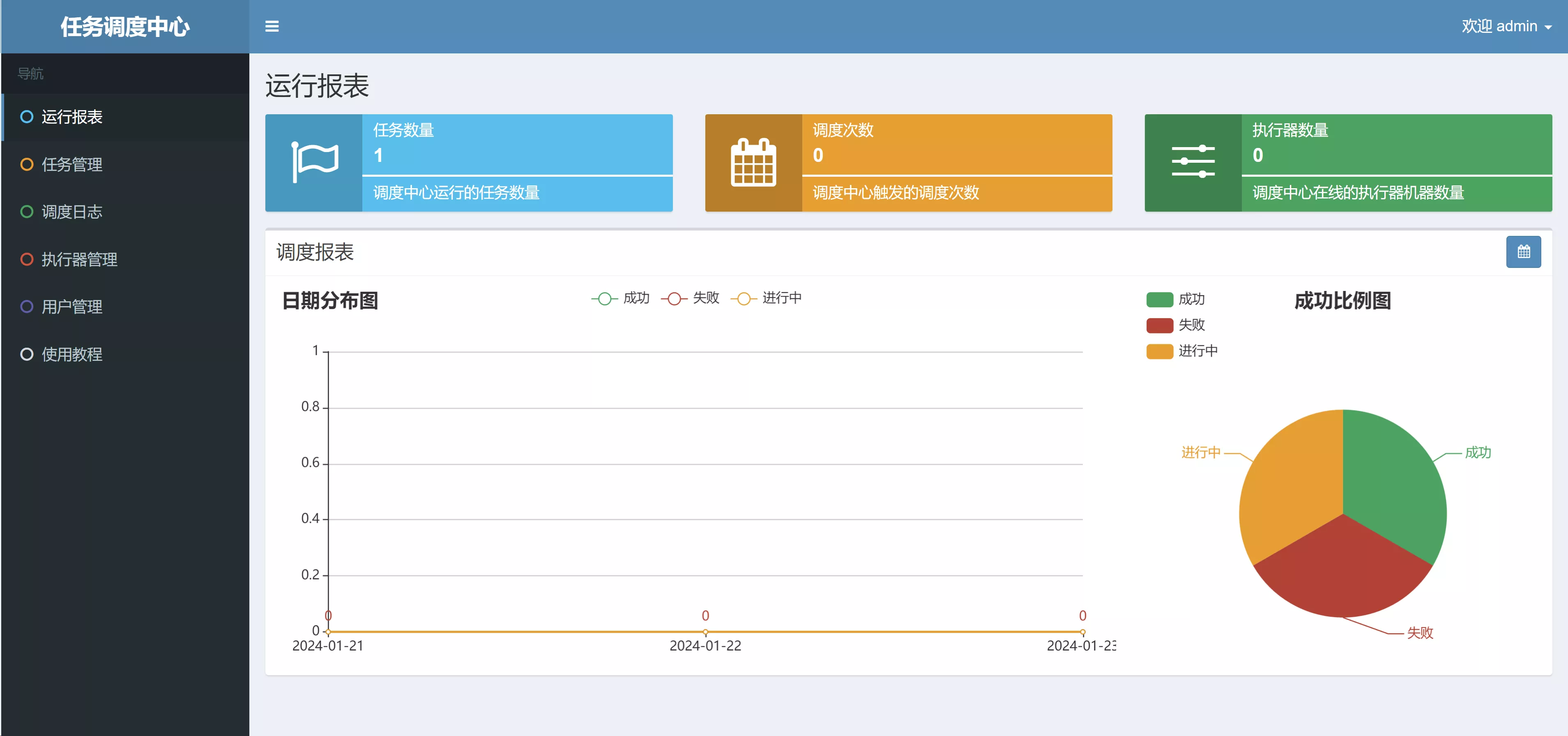
- 运行成功后
- 访问地址:http://localhost:8080/xxl-job-admin
- 默认账号/密码:
admin/123456
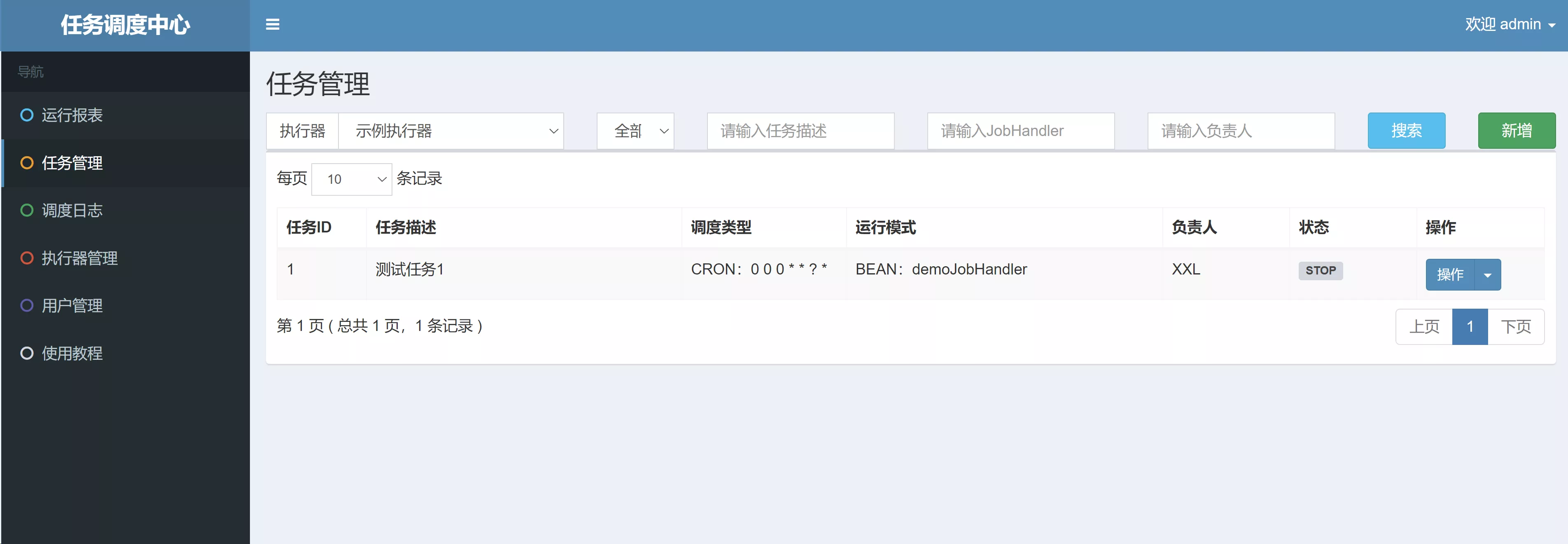
《任务管理》页面,可以看到已经注册并等待定时执行的任务
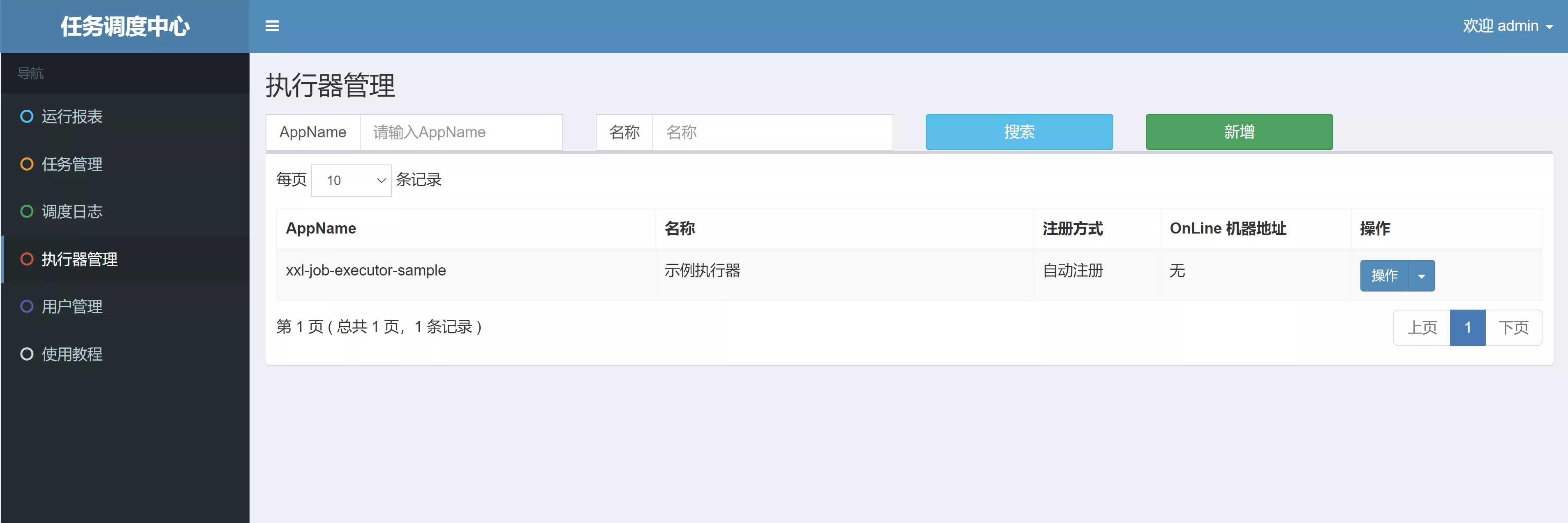
《执行器管理》页面,可以看到已注册的执行器。执行器相当于实际执行业务逻辑的代码,跟随项目部署在服务器上,对于分布式项目,同一个执行器会部署在多个机器上
4. 入门Demo
直接使用 XXL-JOB 源码包的 xxl-job-executor-sample-springboot 进行入门学习
1. XXL-JOB 依赖
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.1-SNAPSHOT</version>
</dependency>
2. 配置执行器
需要手动创建一个 XXL-JOB 执行器的 Bean
package com.xxl.job.executor.core.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
3. application.properties
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job executor appname
xxl.job.executor.appname=xxl-job-executor-sample
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30
4. 开发任务
内置了一个 SampleXxlJob 任务类,编写了多个基础任务,照猫画虎即可
/**
* XxlJob开发示例(Bean模式)
*
* 开发步骤:
* 1、任务开发:在Spring Bean实例中,开发Job方法;
* 2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
* 3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;
* 4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;
*
* @author xuxueli 2019-12-11 21:52:51
*/
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobHelper.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
// default success
}
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
// 业务逻辑
for (int i = 0; i < shardTotal; i++) {
if (i == shardIndex) {
XxlJobHelper.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobHelper.log("第 {} 片, 忽略", i);
}
}
}
/**
* 3、命令行任务
*/
@XxlJob("commandJobHandler")
public void commandJobHandler() throws Exception {
String command = XxlJobHelper.getJobParam();
int exitValue = -1;
BufferedReader bufferedReader = null;
try {
// command process
ProcessBuilder processBuilder = new ProcessBuilder();
processBuilder.command(command);
processBuilder.redirectErrorStream(true);
Process process = processBuilder.start();
//Process process = Runtime.getRuntime().exec(command);
BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream());
bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream));
// command log
String line;
while ((line = bufferedReader.readLine()) != null) {
XxlJobHelper.log(line);
}
// command exit
process.waitFor();
exitValue = process.exitValue();
} catch (Exception e) {
XxlJobHelper.log(e);
} finally {
if (bufferedReader != null) {
bufferedReader.close();
}
}
if (exitValue == 0) {
// default success
} else {
XxlJobHelper.handleFail("command exit value("+exitValue+") is failed");
}
}
/**
* 4、跨平台Http任务
* 参数示例:
* "url: http://www.baidu.com\n" +
* "method: get\n" +
* "data: content\n";
*/
@XxlJob("httpJobHandler")
public void httpJobHandler() throws Exception {
// param parse
String param = XxlJobHelper.getJobParam();
if (param==null || param.trim().length()==0) {
XxlJobHelper.log("param["+ param +"] invalid.");
XxlJobHelper.handleFail();
return;
}
String[] httpParams = param.split("\n");
String url = null;
String method = null;
String data = null;
for (String httpParam: httpParams) {
if (httpParam.startsWith("url:")) {
url = httpParam.substring(httpParam.indexOf("url:") + 4).trim();
}
if (httpParam.startsWith("method:")) {
method = httpParam.substring(httpParam.indexOf("method:") + 7).trim().toUpperCase();
}
if (httpParam.startsWith("data:")) {
data = httpParam.substring(httpParam.indexOf("data:") + 5).trim();
}
}
// param valid
if (url==null || url.trim().length()==0) {
XxlJobHelper.log("url["+ url +"] invalid.");
XxlJobHelper.handleFail();
return;
}
if (method==null || !Arrays.asList("GET", "POST").contains(method)) {
XxlJobHelper.log("method["+ method +"] invalid.");
XxlJobHelper.handleFail();
return;
}
boolean isPostMethod = method.equals("POST");
// request
HttpURLConnection connection = null;
BufferedReader bufferedReader = null;
try {
// connection
URL realUrl = new URL(url);
connection = (HttpURLConnection) realUrl.openConnection();
// connection setting
connection.setRequestMethod(method);
connection.setDoOutput(isPostMethod);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setReadTimeout(5 * 1000);
connection.setConnectTimeout(3 * 1000);
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8");
connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8");
// do connection
connection.connect();
// data
if (isPostMethod && data!=null && data.trim().length()>0) {
DataOutputStream dataOutputStream = new DataOutputStream(connection.getOutputStream());
dataOutputStream.write(data.getBytes("UTF-8"));
dataOutputStream.flush();
dataOutputStream.close();
}
// valid StatusCode
int statusCode = connection.getResponseCode();
if (statusCode != 200) {
throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid.");
}
// result
bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
StringBuilder result = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
result.append(line);
}
String responseMsg = result.toString();
XxlJobHelper.log(responseMsg);
return;
} catch (Exception e) {
XxlJobHelper.log(e);
XxlJobHelper.handleFail();
return;
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
if (connection != null) {
connection.disconnect();
}
} catch (Exception e2) {
XxlJobHelper.log(e2);
}
}
}
/**
* 5、生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑;
*/
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")
public void demoJobHandler2() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
}
public void init(){
logger.info("init");
}
public void destroy(){
logger.info("destroy");
}
}
5. 任务调度中心
- 《执行器管理》页面,查看到已注册的执行器
- 现在执行器是通过初始化数据库表脚本创建的,也可以手动新增或让框架自动注册
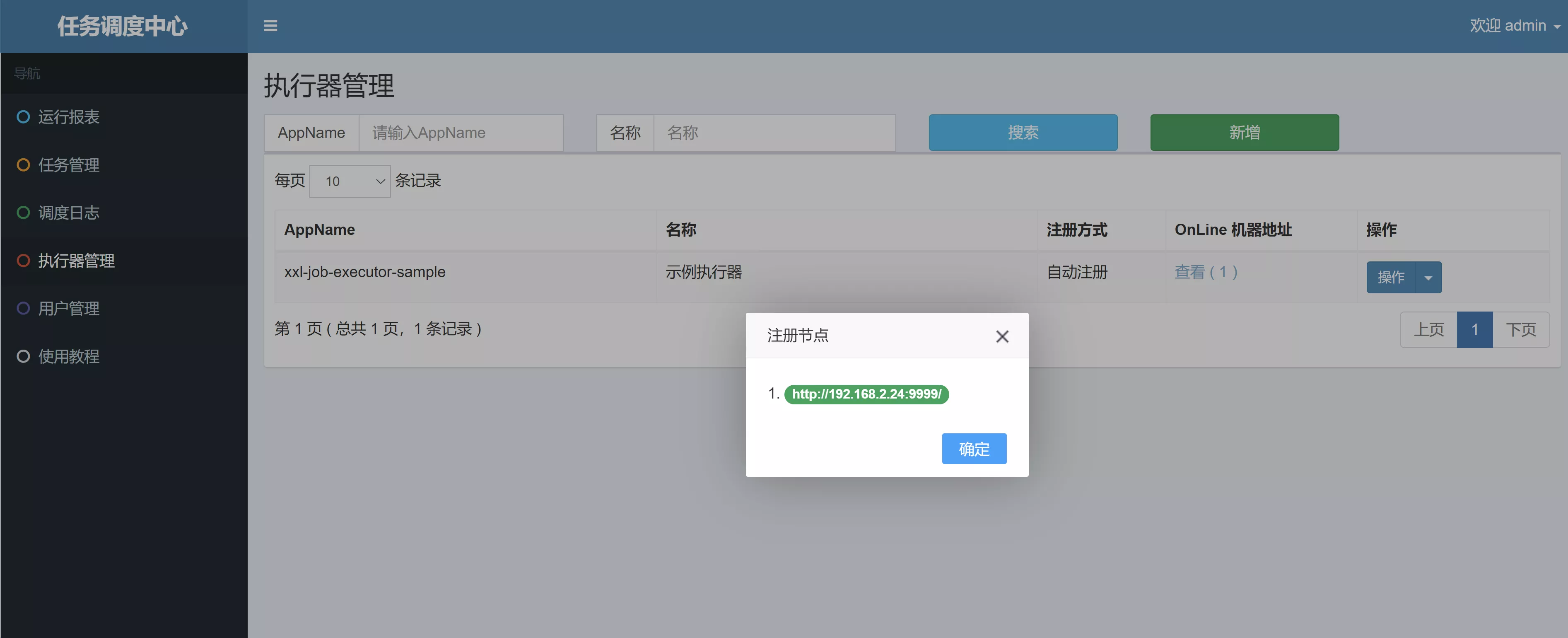
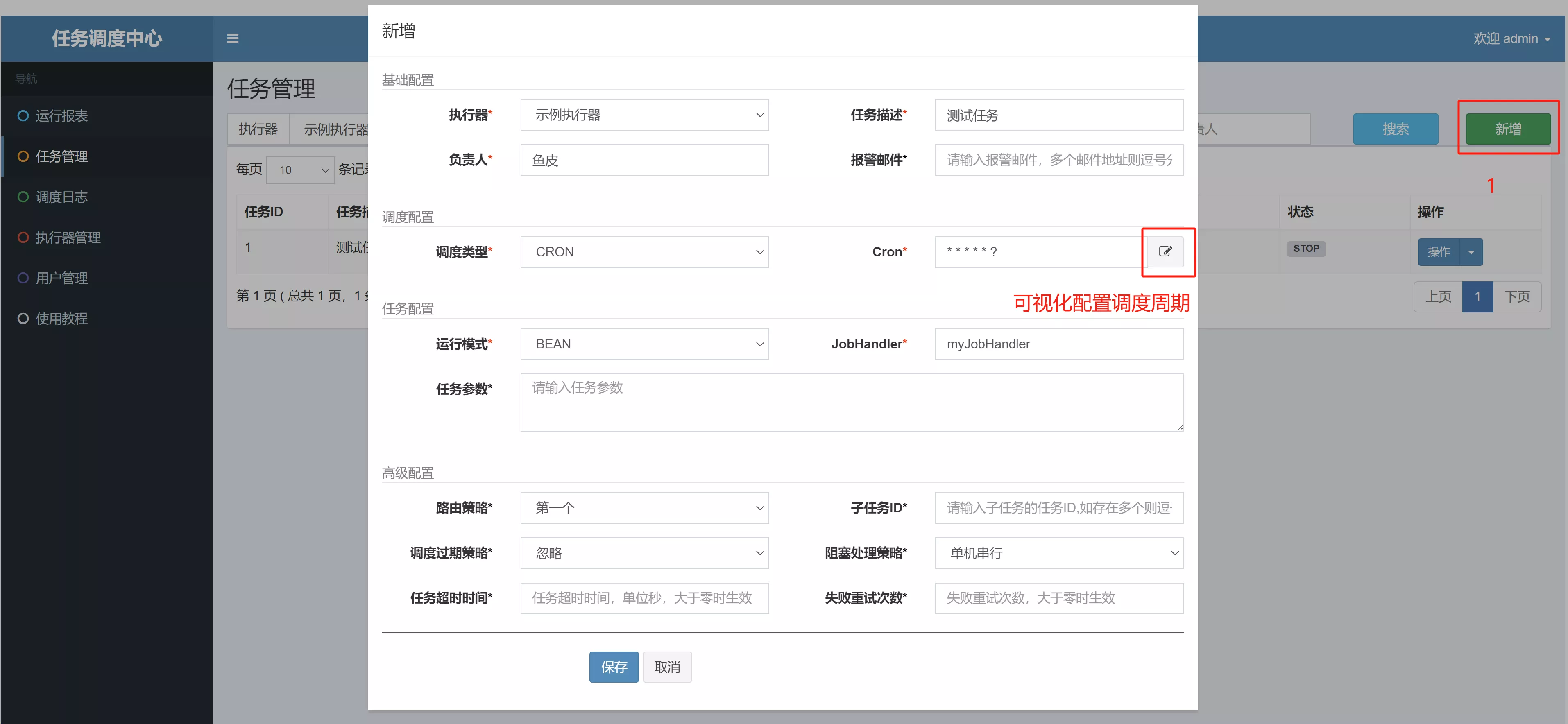
- 《任务管理》页面,手动新增任务
- 在配置中,可以指定任务执行周期(Cron)和执行的 JobHandler(开发任务时注解内的值一致)
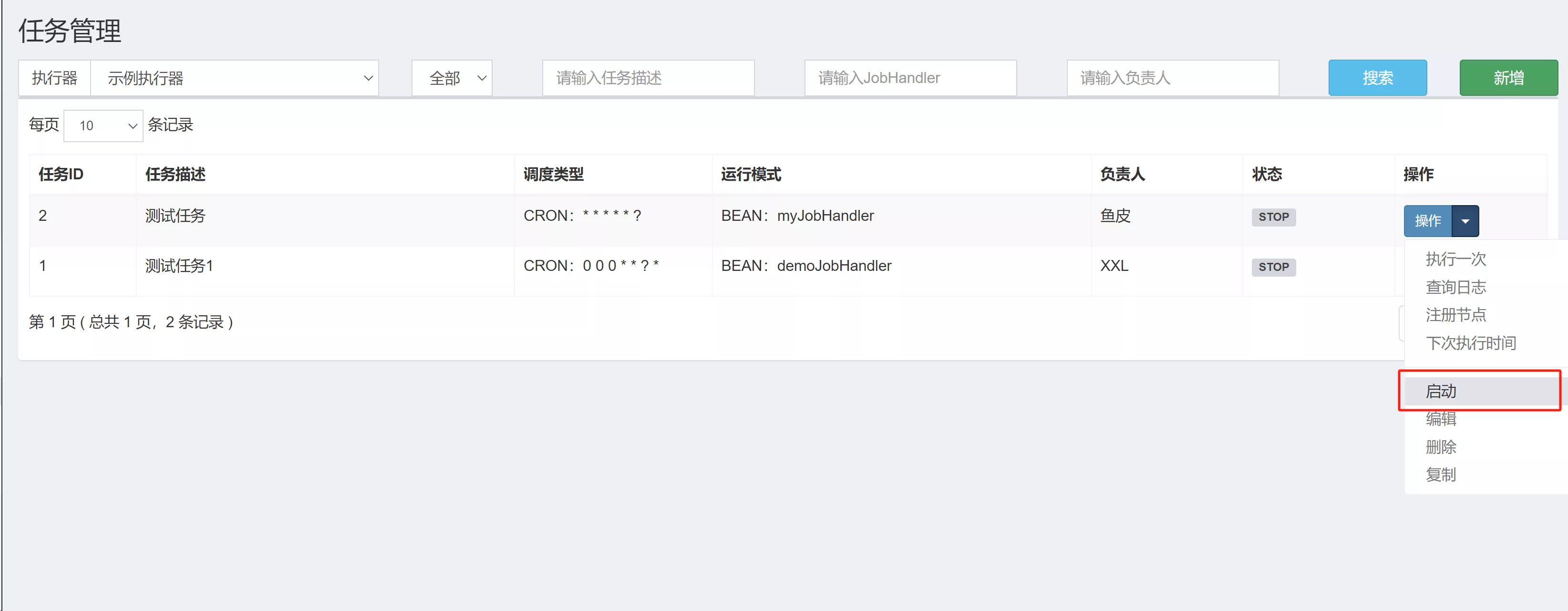
- 启动任务
- 点击启动即可,调试阶段也可以选择“执行一次”
- 《运行报表》页面,可以查看任务的执行记录统计信息,从中可以分析出任务的成功率、阻塞情况等
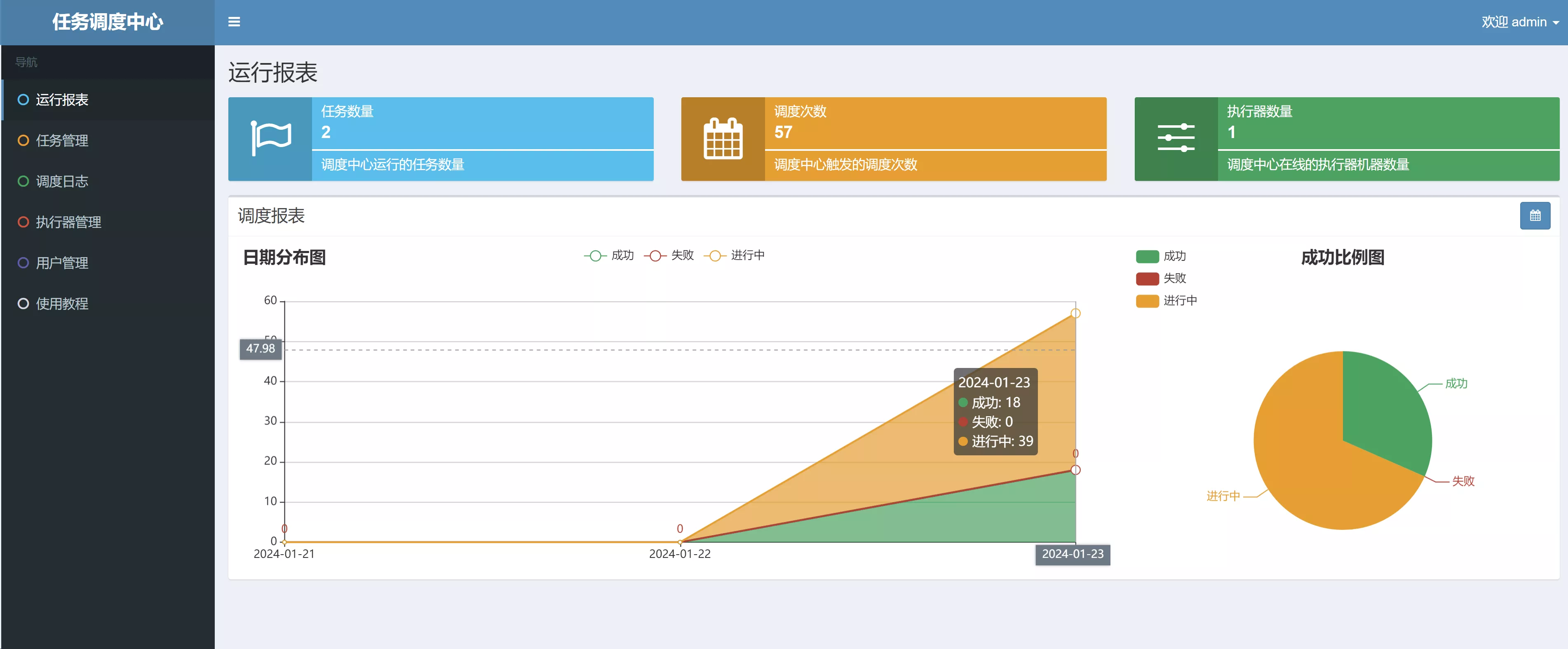
- 测试发现,如果有已经触发但是没有执行完成的任务(eg:线程阻塞了),哪怕这时关闭任务,也会把积压的请求完成。如果这时候 XXL-JOB 管理系统挂了,这时客户端不再执行定时任务,但客户端会不断重连 XXL-JOB 管理系统,等管理系统重新上线后,仍然会继续运行积压的请求。这是 XXL-JOB 提供的能力之一,相比于自己开发一套任务调度系统,使用 XXL-JOB 更省时省心
- 除了编写代码外,XXL-JOB 也支持直接在界面编写任务代码。如下图,运行模式设置为
GLUE即可:- 不推荐这种方式,不利于维护

5. 核心原理
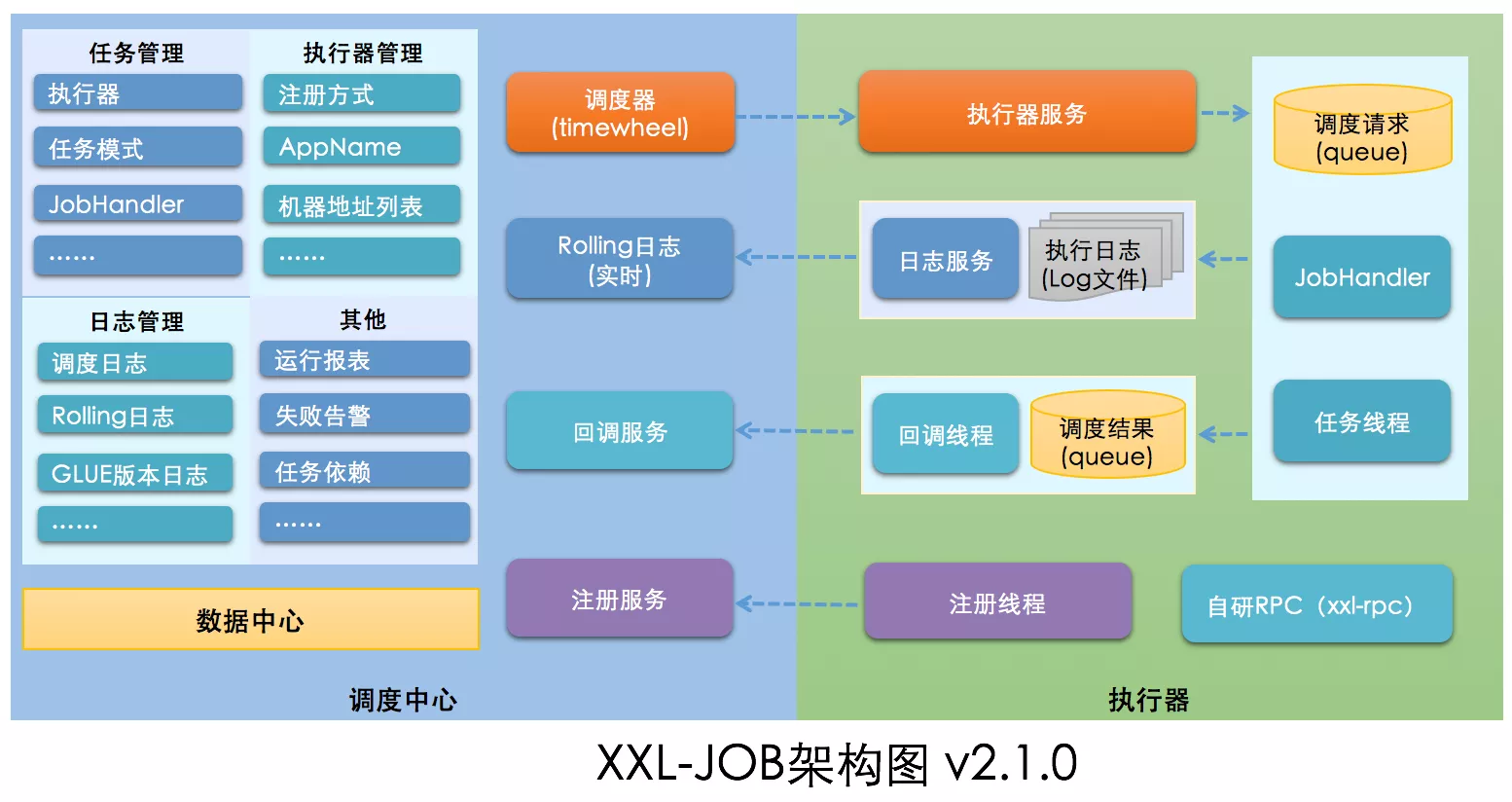
从整体到局部,XXL-JOB 分为调度中心和执行器
- 调度中心:相当于管理者,管理分配任务
- 执行器:相当于员工,执行任务
员工首先要在公司完成注册(注册线程调用注册服务),然后调度中心就可以通过调度器来调用执行器,执行器负责完成任务并且向调度中心汇报进度和情况(日志),调度中心可以管理任务的执行情况并提供可视化监控面板
4. 文件清理机制开发
掌握了 XXL-JOB 的基础用法和原理后,实战开发文件清理机制
1. 引入 XXL-JOB
pom.xml引入 Maven 依赖:
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.0</version>
</dependency>
- 复制 XXL-JOB 配置类
XxlJobConfig,到web.config包下,用于创建执行器 Bean
package com.yupi.web.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*/
@Configuration
@Slf4j
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
application.yml
# xxl-job 配置
xxl:
job:
admin:
# xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
addresses: http://127.0.0.1:8080/xxl-job-admin
# xxl-job, access token
accessToken: default_token
executor:
# xxl-job executor appname
appname: yuzi-generator-web-backend
# xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
address:
# xxl-job executor server-info
ip:
port: 9999
# xxl-job executor log-path
logpath: logs/jobhandler
# xxl-job executor log-retention-days
logretentiondays: 30
正常启动
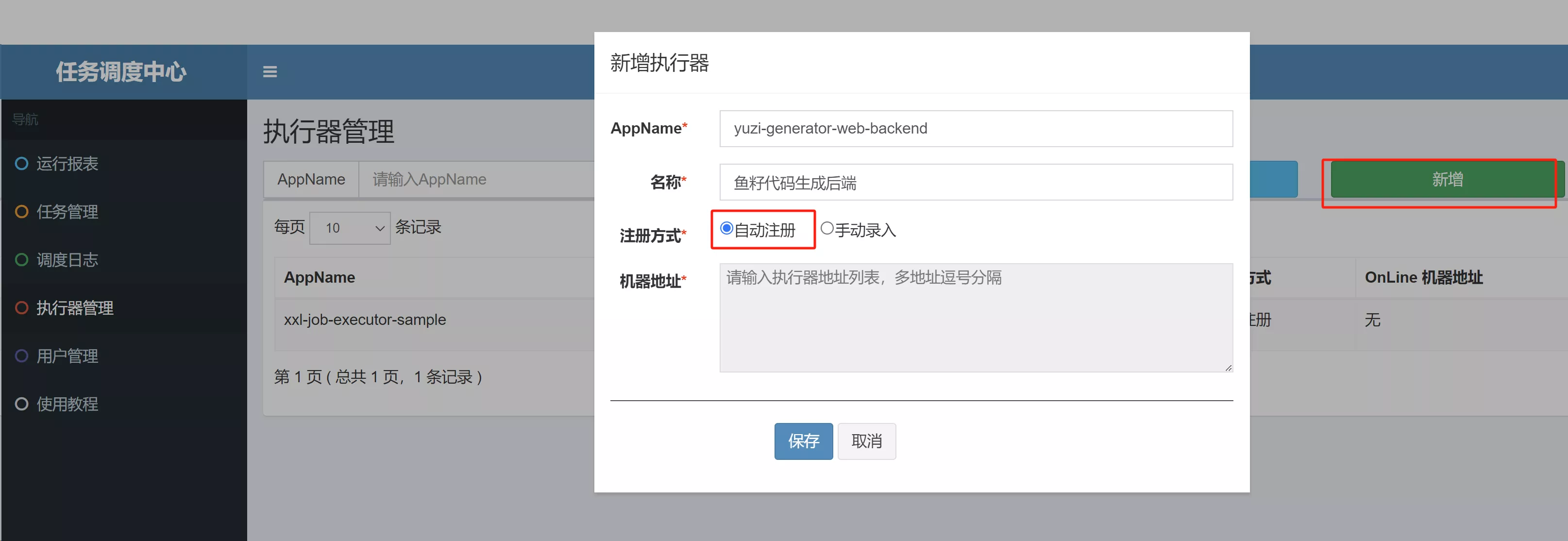
2. 任务管理平台新增执行器
AppName 的填写和配置文件一致,注册方式选择《自动注册》,XXL-JOB 会自动寻找执行器的地址
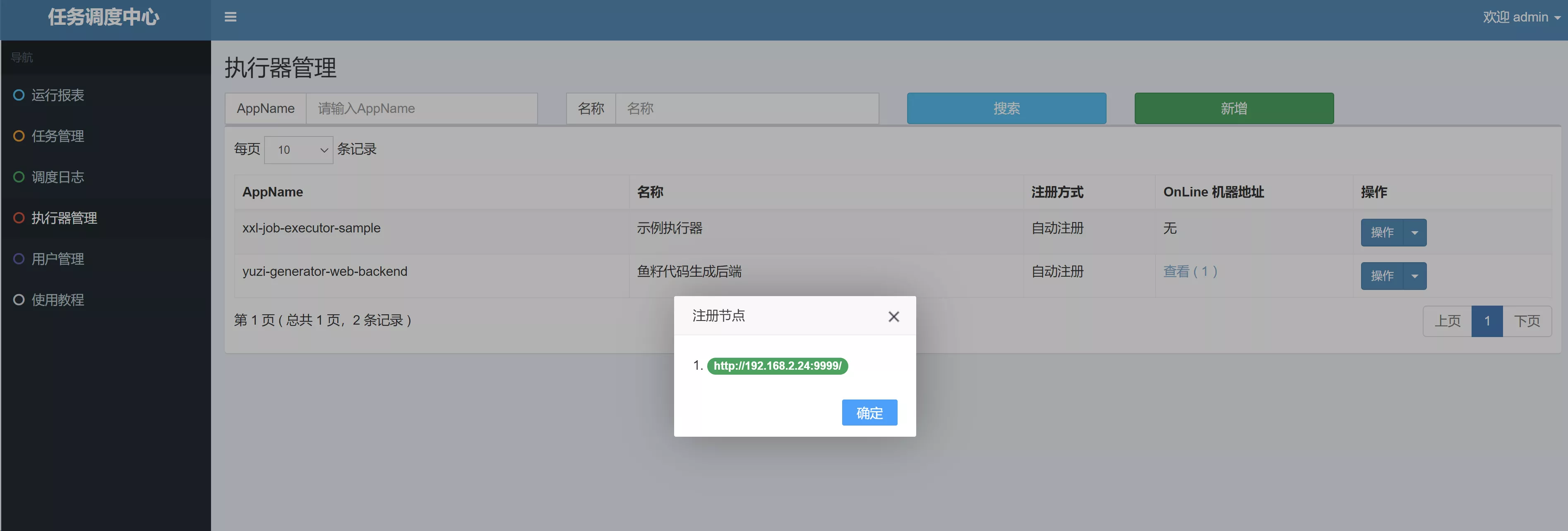
新增成功后,稍等片刻。刷新(重新搜索),能够看到执行器成功接入
3. 对象存储支持删除操作
- 给
CosManager补充删除对象、批量删除、删除目录功能。官方文档
/**
* 删除对象
*
* @param key
* @throws CosClientException
* @throws CosServiceException
*/
public void deleteObject(String key) throws CosClientException, CosServiceException {
cosClient.deleteObject(cosClientConfig.getBucket(), key);
}
- 批量删除对象方法。注意:批量删除的调用路径不能以
/开头!
/**
* 批量删除对象
*
* @param keyList
* @return
* @throws MultiObjectDeleteException
* @throws CosClientException
* @throws CosServiceException
*/
public DeleteObjectsResult deleteObjects(List<String> keyList)
throws MultiObjectDeleteException, CosClientException, CosServiceException {
DeleteObjectsRequest deleteObjectsRequest = new DeleteObjectsRequest(cosClientConfig.getBucket());
// 设置要删除的key列表, 最多一次删除1000个
ArrayList<DeleteObjectsRequest.KeyVersion> keyVersions = new ArrayList<>();
// 传入要删除的文件名
// 注意文件名不允许以正斜线/或者反斜线\开头,例如:
// 存储桶目录下有a/b/c.txt文件,如果要删除,只能是 keyList.add(new KeyVersion("a/b/c.txt")), 若使用 keyList.add(new KeyVersion("/a/b/c.txt"))会导致删除不成功
for (String key : keyList) {
keyVersions.add(new DeleteObjectsRequest.KeyVersion(key));
}
deleteObjectsRequest.setKeys(keyVersions);
DeleteObjectsResult deleteObjectsResult = cosClient.deleteObjects(deleteObjectsRequest);
return deleteObjectsResult;
}
- 删除目录。注意:方法参数是目录前缀,而不是精确的目录,所以尽量以
/结尾,防止误删文件
/**
* 删除目录
*
* @param delPrefix
* @throws CosClientException
* @throws CosServiceException
*/
public void deleteDir(String delPrefix) throws CosClientException, CosServiceException {
ListObjectsRequest listObjectsRequest = new ListObjectsRequest();
// 设置 bucket 名称
listObjectsRequest.setBucketName(cosClientConfig.getBucket());
// prefix 表示列出的对象名以 prefix 为前缀
// 这里填要列出的目录的相对 bucket 的路径
listObjectsRequest.setPrefix(delPrefix);
// 设置最大遍历出多少个对象, 一次 listobject 最大支持1000
listObjectsRequest.setMaxKeys(1000);
// 保存每次列出的结果
ObjectListing objectListing = null;
do {
objectListing = cosClient.listObjects(listObjectsRequest);
// 这里保存列出的对象列表
List<COSObjectSummary> cosObjectSummaries = objectListing.getObjectSummaries();
if (CollUtil.isEmpty(cosObjectSummaries)) {
break;
}
ArrayList<DeleteObjectsRequest.KeyVersion> delObjects = new ArrayList<>();
for (COSObjectSummary cosObjectSummary : cosObjectSummaries) {
delObjects.add(new DeleteObjectsRequest.KeyVersion(cosObjectSummary.getKey()));
}
DeleteObjectsRequest deleteObjectsRequest = new DeleteObjectsRequest(cosClientConfig.getBucket());
deleteObjectsRequest.setKeys(delObjects);
cosClient.deleteObjects(deleteObjectsRequest);
// 标记下一次开始的位置
String nextMarker = objectListing.getNextMarker();
listObjectsRequest.setMarker(nextMarker);
} while (objectListing.isTruncated());
}
- 单元测试
- 添加
--spring.profiles.active=local环境变量到启动参数中
- 添加
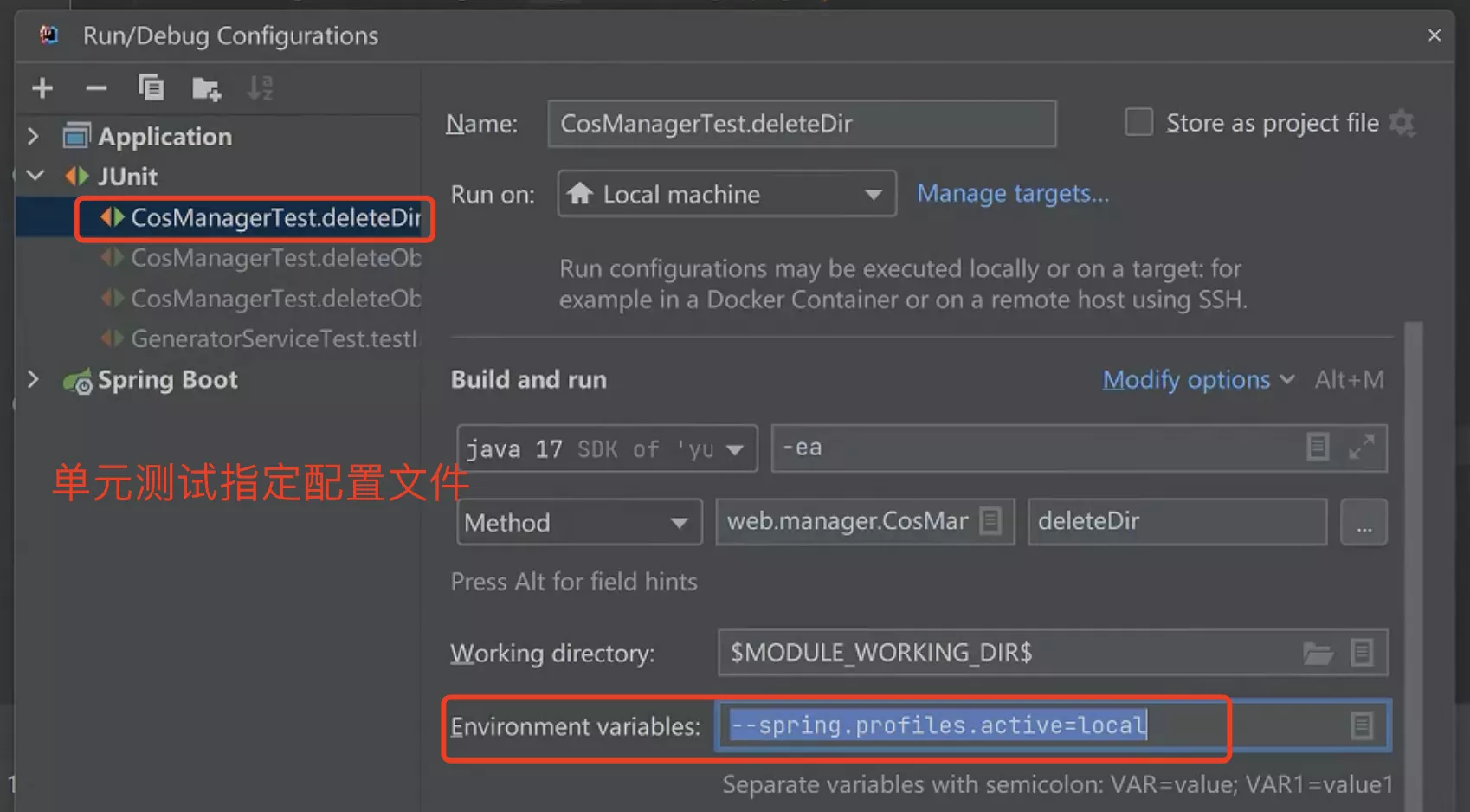
@SpringBootTest
class CosManagerTest {
@Resource
private CosManager cosManager;
@Test
void deleteObject() {
cosManager.deleteObject("/generator_make_template/1");
}
@Test
void deleteObjects() {
cosManager.deleteObjects(Arrays.asList("generator_make_template/1/a.zip",
"generator_make_template/1/b.zip"
));
}
@Test
void deleteDir() {
cosManager.deleteDir("/generator_picture/1/");
}
}
4. 开发定时任务
需求:每天清理所有无用的文件,包括用户上传的模板制作文件(generator_make_template)、已删除的代码生成器对应的产物包文件(generator_dist)
- 在
GeneratorMapper中新增查询已删除数据的方法
public interface GeneratorMapper extends BaseMapper<Generator> {
@Select("SELECT id, distPath FROM generator WHERE isDelete = 1")
List<Generator> listDeletedGenerator();
}
- 在
web.job包下新建ClearCosJobHandler任务处理器
@Component
@Slf4j
public class ClearCosJobHandler {
@Resource
private CosManager cosManager;
@Resource
private GeneratorMapper generatorMapper;
/**
* 每天执行
*
* @throws InterruptedException
*/
@XxlJob("clearCosJobHandler")
public void clearCosJobHandler() throws Exception {
log.info("clearCosJobHandler start");
// 编写业务逻辑
// 1. 包括用户上传的模板制作文件(generator_make_template)
cosManager.deleteDir("/generator_make_template/");
// 2. 已删除的代码生成器对应的产物包文件(generator_dist)。
List<Generator> generatorList = generatorMapper.listDeletedGenerator();
List<String> keyList = generatorList.stream().map(Generator::getDistPath)
.filter(StrUtil::isNotBlank)
// 移除 '/' 前缀
.map(distPath -> distPath.substring(1))
.collect(Collectors.toList());
cosManager.deleteObjects(keyList);
log.info("clearCosJobHandler end");
}
}
然后在 XXL-JOB 管理面板新增任务,每天固定时间执行:
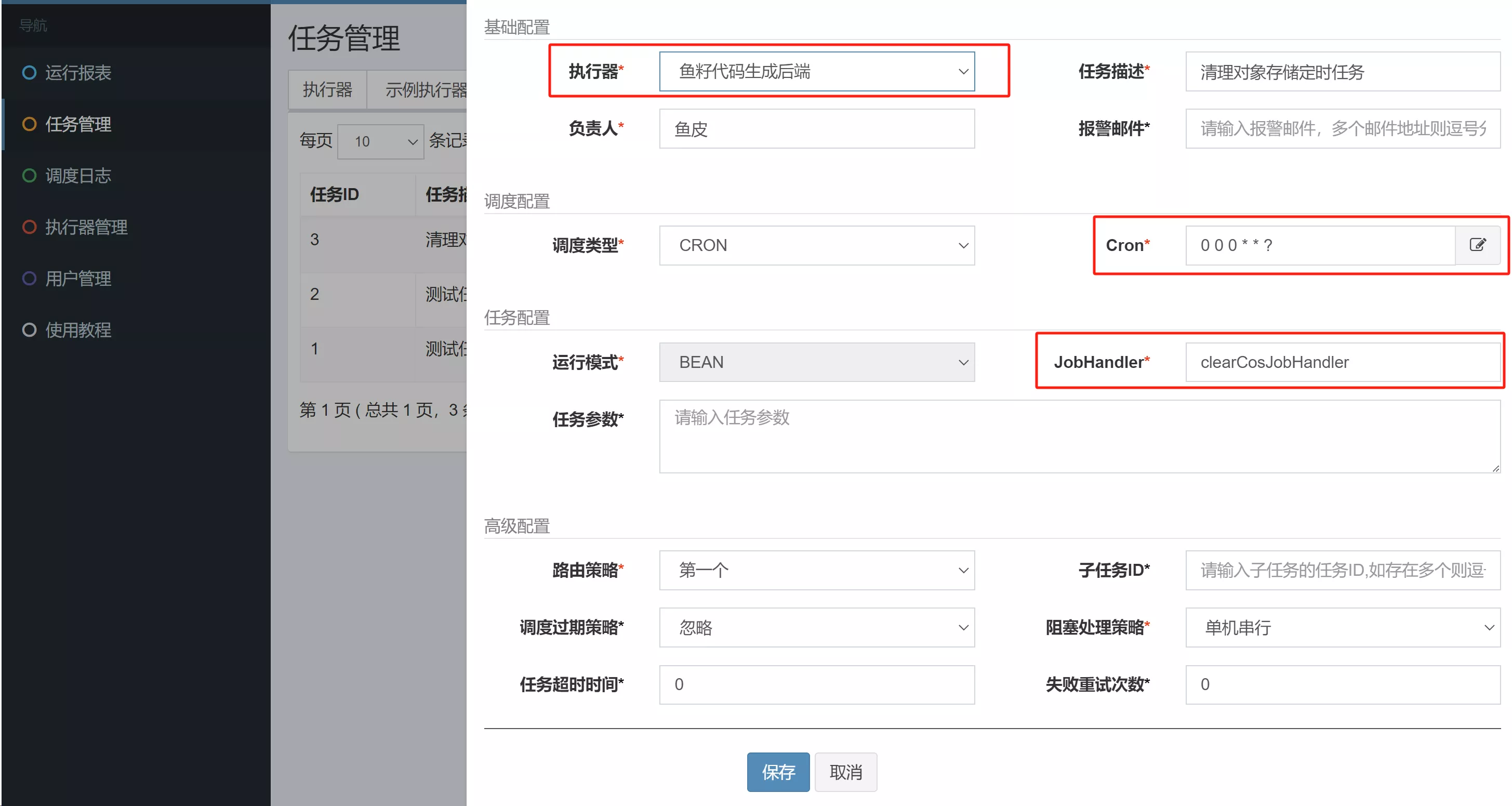
5. 测试
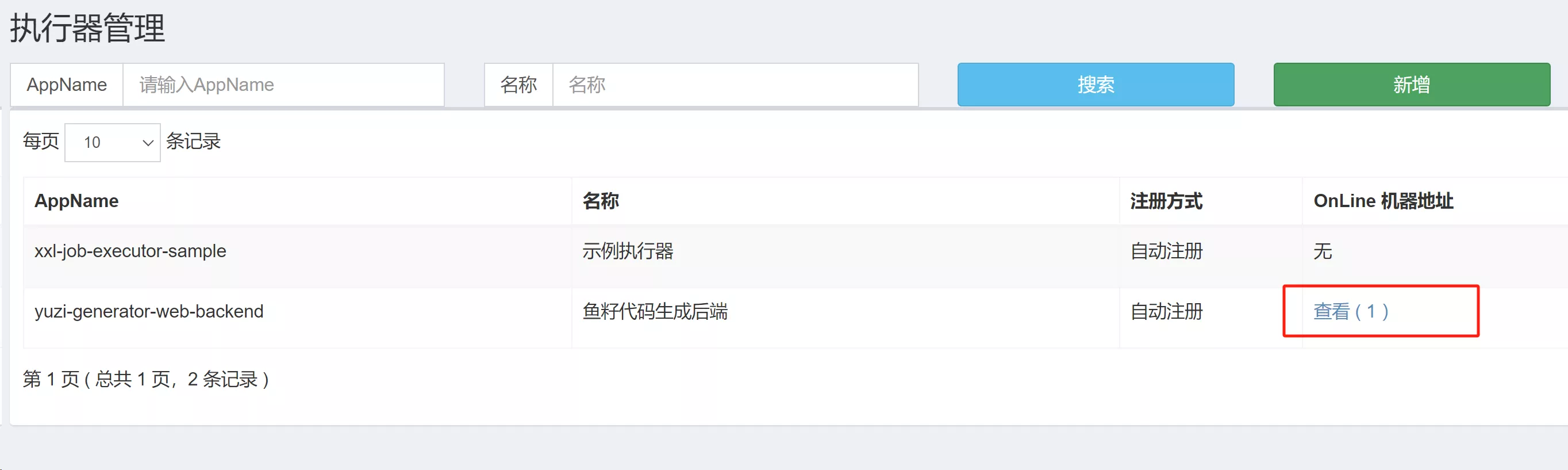
- 首先确保执行器管理页面的执行器识别到了在线机器地址
- 没识别到地址的话可以尝试重新启动项目、重新注册执行器等
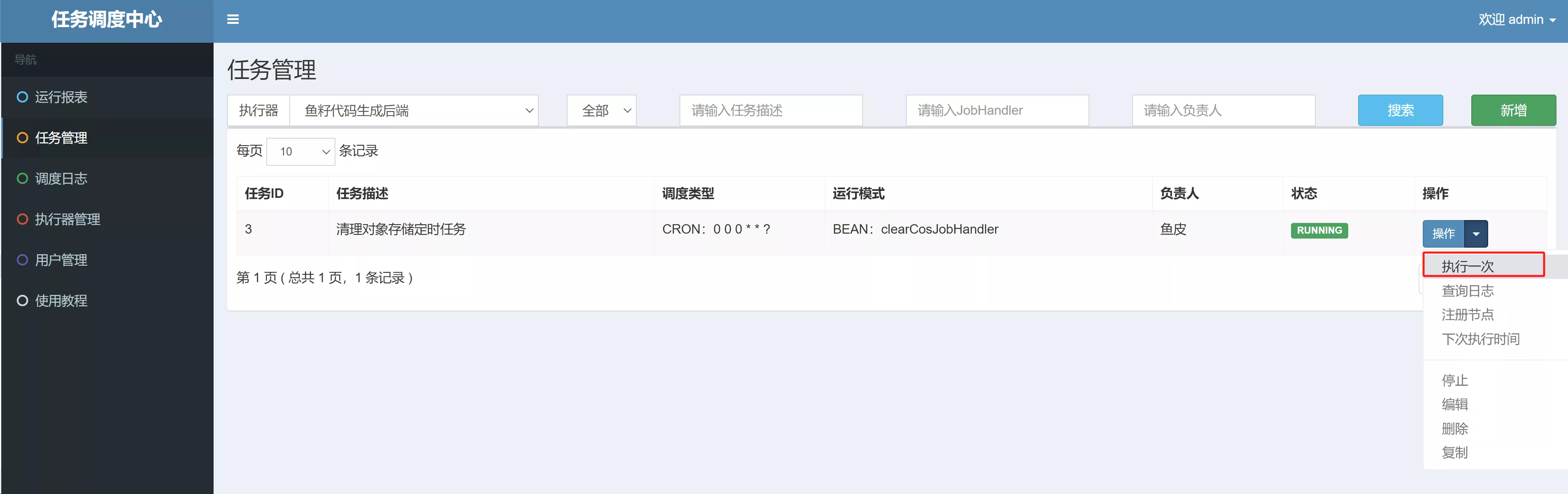
- 然后进入任务管理,选择新增的执行器,执行一次清理任务
- 任务成功日志

- 执行失败,也可以查看失败原因
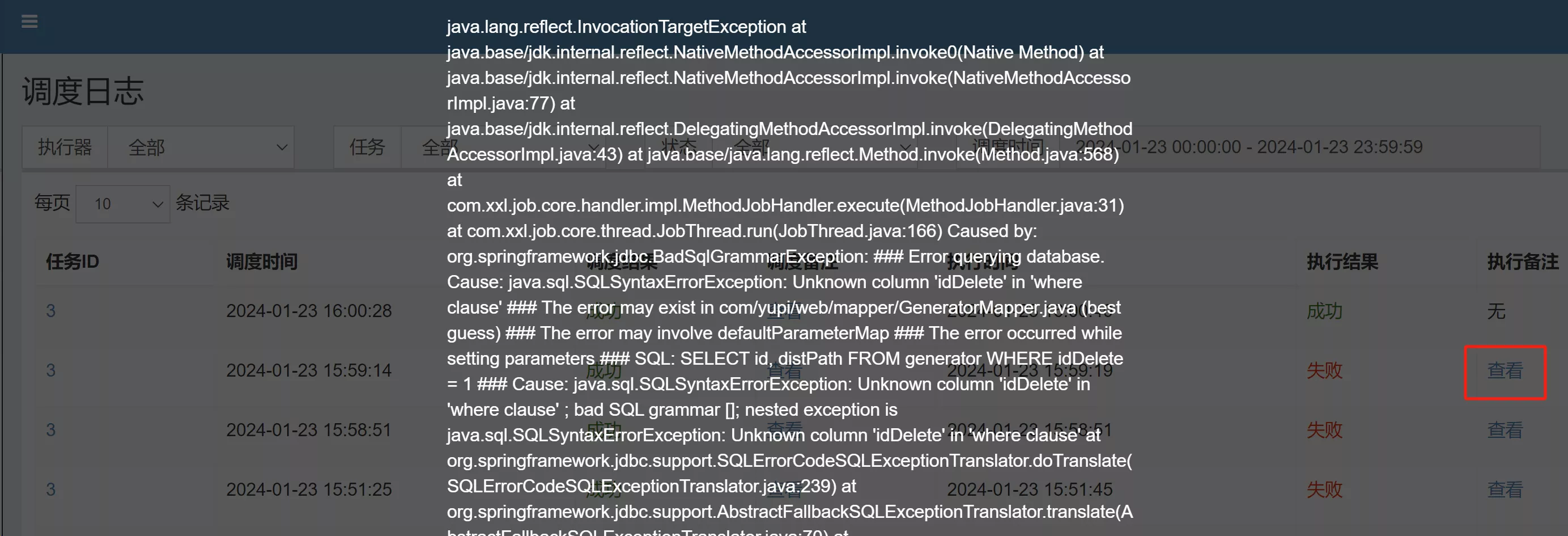
扩展:上述定时任务的代码有哪些可以优化的地方?比如查询已删除数据的过程
3. 存储成本优化
第三方云服务,参考官方的成本优化方案 COS 成本优化解决方案
- 对于大部分企业来说, 存储容量费用 和 流量费用 是其云存储成本的主要组成部分
1. 选择合适的存储
要根据实际的需求和业务选择对象存储的类型和业务地域。腾讯云 COS 提供了
- 标准存储
- 低频存储
- 归档存储
- 深度归档存储
后三种存储类型的存储容量费用较低。存储总费用最低的存储类型未必最合适
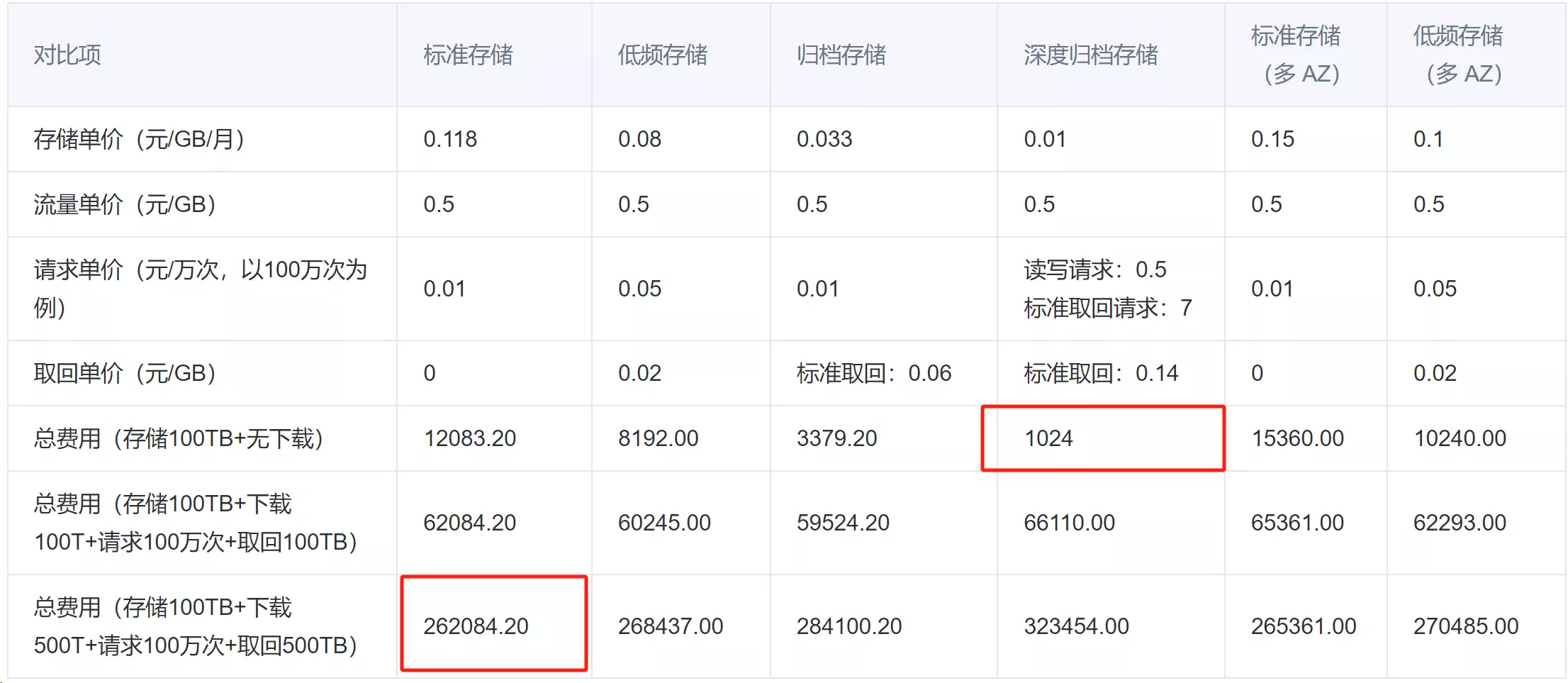
具体到业务场景中,官方推荐:
- 频繁读写场景
- UGC 场景、电商图片等读多写少的业务,可使用标准存储类型。如果业务对可用性和数据持久性有高要求,则可以考虑使用标准存储(多 AZ)
- 少量读场景(一个月读一次)
- 日志数据分析、网盘数据等业务,读取频率较低,但读取时对性能要求高,可使用低频存储类型。对可用性和数据持久性有高要求的业务可以使用低频存储(多 AZ)
- 极少量读场景(三个月读一次)
- 视频监控、日志数据归档等业务,读取频率极低,对读取性能要求较低,可使用归档存储类型
- 基本不读取场景(半年读一次)
- 医疗影像、档案资料等业务,日常仅做长期备份用途,对读取性能几乎无要求,可使用深度归档存储类型
2. 数据沉降
对于大部分数据而言,其访问热度一般随着存储时间延长而降低。因此,如果想严格控制成本,需要根据业务数据访问情况的变化,分析调整数据存储类型
一般情况下,数据沉降分为 2 个阶段:
- 先分析:通过对象存储提供的清单 / 访问日志分析,或业务代码中自行统计分析
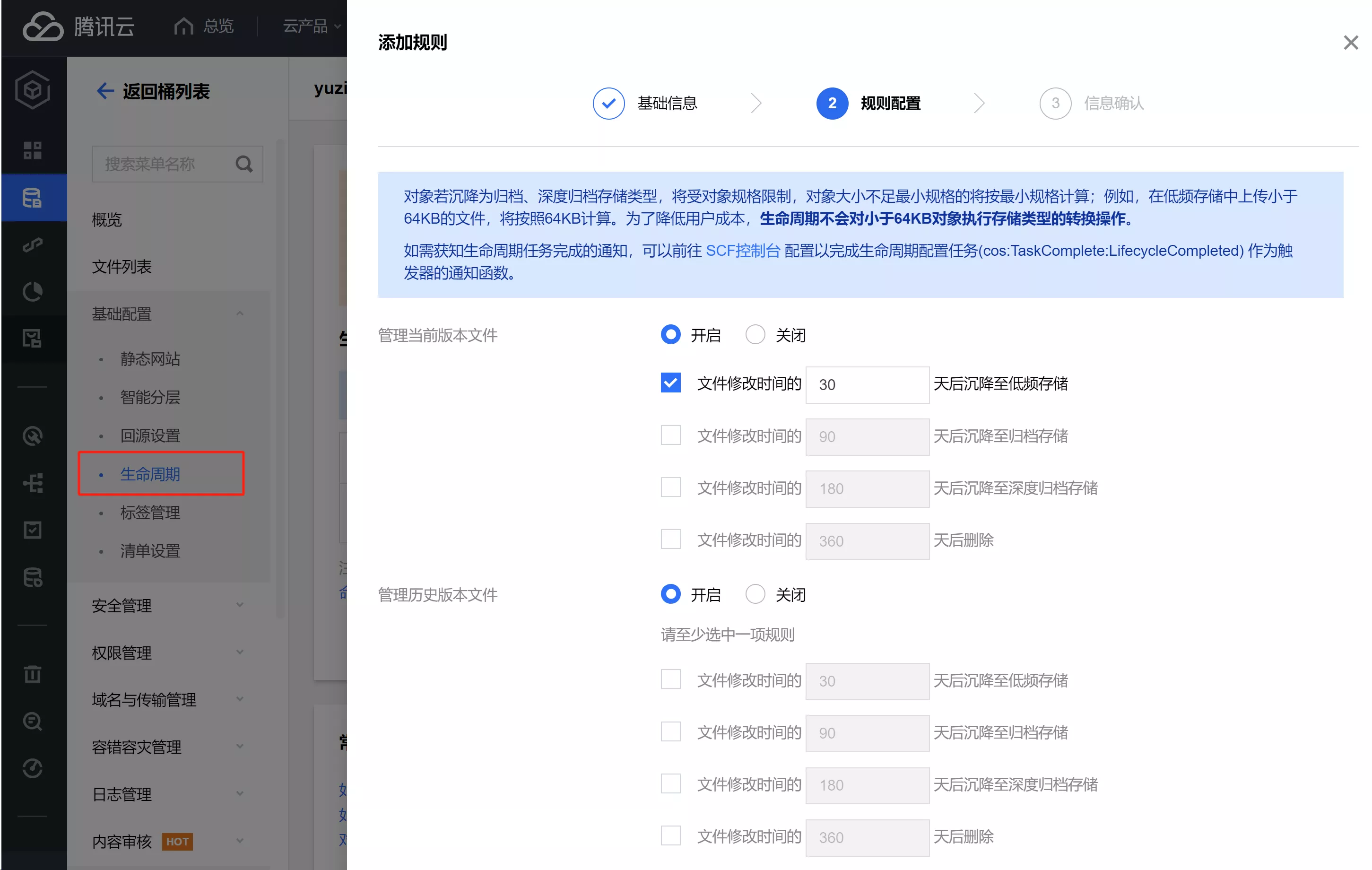
- 再沉降:可以直接通过对象存储提供的 生命周期 功能自动沉降数据
3. 减少访问
目的:降低流量费
- CDN 本质上也是一种缓存,虽然能减少对象存储的访问(回源),但是会有额外的 CDN 流量费用
4. 存储安全性优化
存储安全是至关重要的,目前对象存储访问权限为“公有读”,处于“半裸奔状态”
1. 官方建议
官方提供了很多种安全方案:官方文档
- KMS 白盒密钥:和设备绑定,安全性极高;但是成本较高
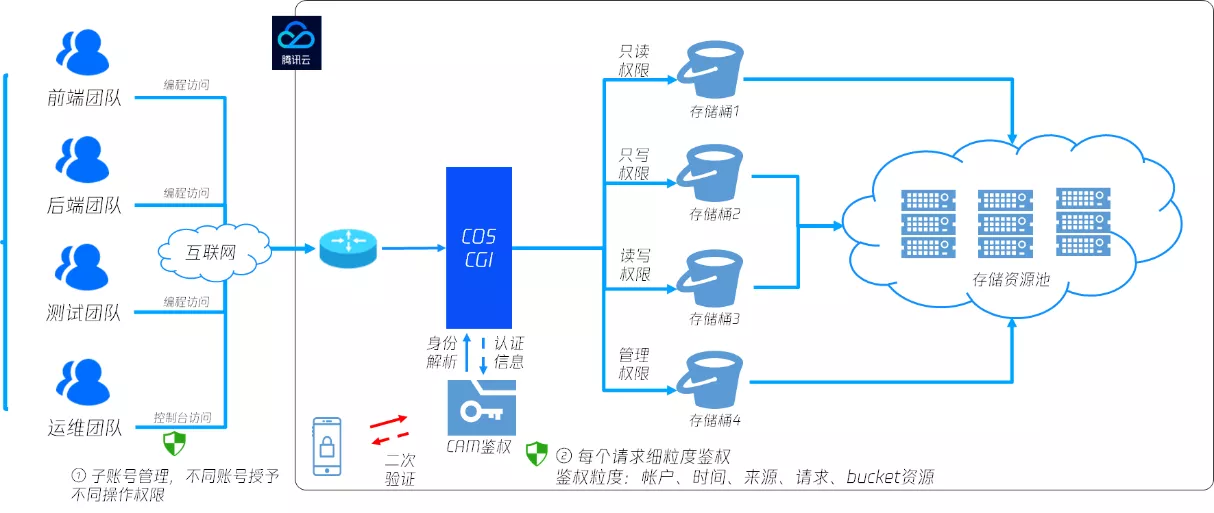
- 权限隔离:授权 CAM 用户 可以在哪种条件下,通过哪种方式对哪些资源进行哪种操作
- 对象锁定:对于一些核心敏感数据(如金融交易数据、医疗影像数据等),可通过对象锁定功能来防止文件在上传之后被删除或者篡改。配置对象锁定功能后,在配置的有效期内,存储桶内的所有数据将处于只读状态,不可覆盖写或删除
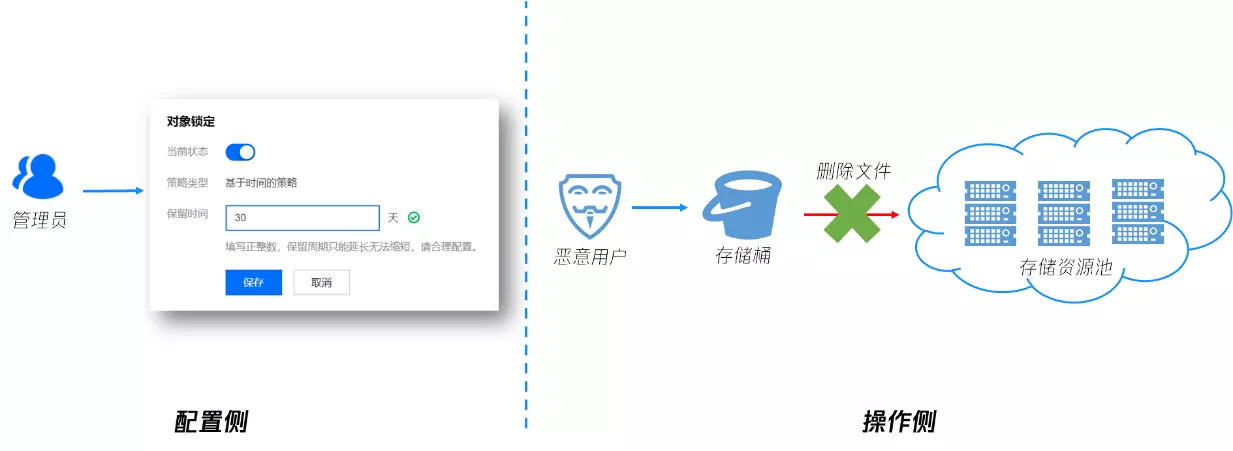
- 数据灾备:通过版本控制和存储桶复制实现异地容灾,进一步保证数据持久性,确保数据误删或被恶意删除时,可从备份站点恢复数据
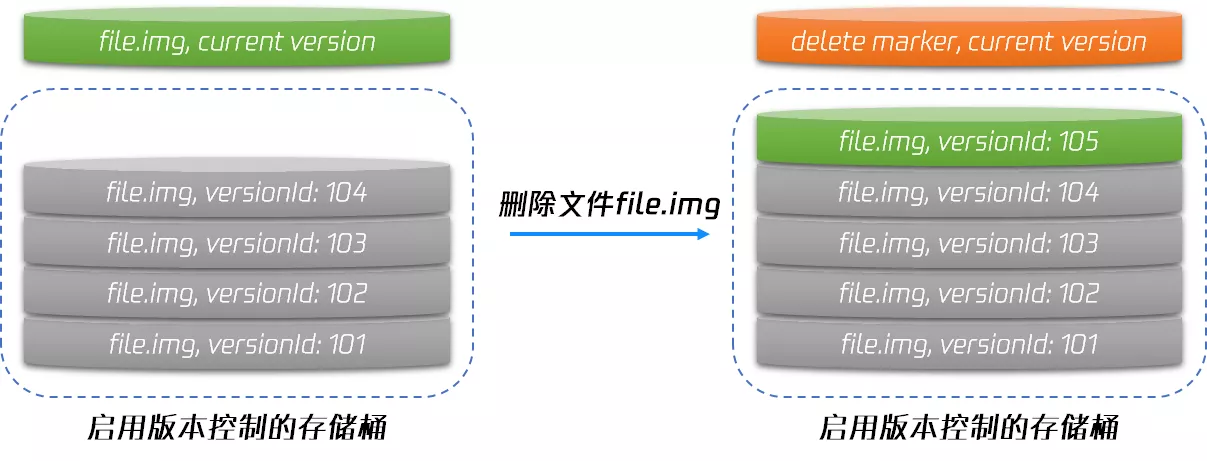
- 版本控制:每次操作都会创建一个新版本的文件,通过“删除标记”来区分文件是否被删除(逻辑删除)。可通过指定版本号访问过去任意版本的数据,还可以进行数据回滚,解决数据误删和覆盖的风险
- 存储桶复制:当主存储桶中的数据被删除时,可从备份存储桶中通过批量拷贝的方式恢复数据

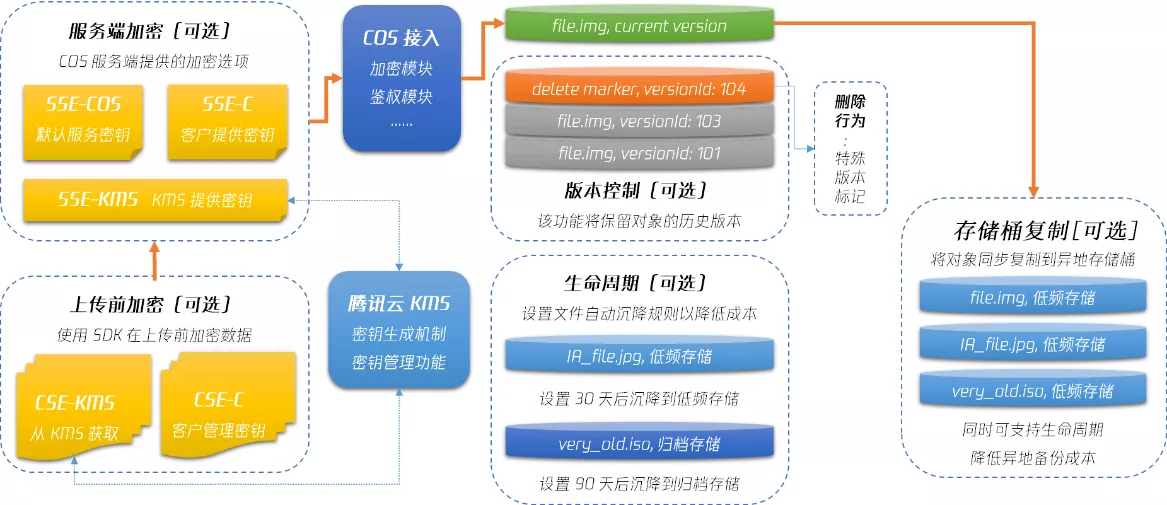
**冷备份:**考虑到版本控制和存储桶复制功能都可能造成文件数增加,用户也可以通过生命周期功能将一些备份数据沉降至低频或者归档存储等更便宜的存储类型,从而实现低成本冷备。完整的冷备方案
此外,还可以通过事中监控(操作对象存储时触发事件通知)、事后追溯(查看日志)等手段,帮助分析排查安全性问题
2. 安全管理
COS 对象存储的控制台中提供了几个安全管理功能
1. 跨域访问设置
通过 HTTP 请求,从一个域去请求另一个域的资源。只要协议、域名、端口有任何一个不相同,都会被当作是不同的域
注意:跨域是浏览器的限制,一般用于前端直传对象存储的场景
进入跨域访问设置控制台:设置跨域访问
可以自由添加规则,根据域名、请求方法、需要的请求头信息配置即可:
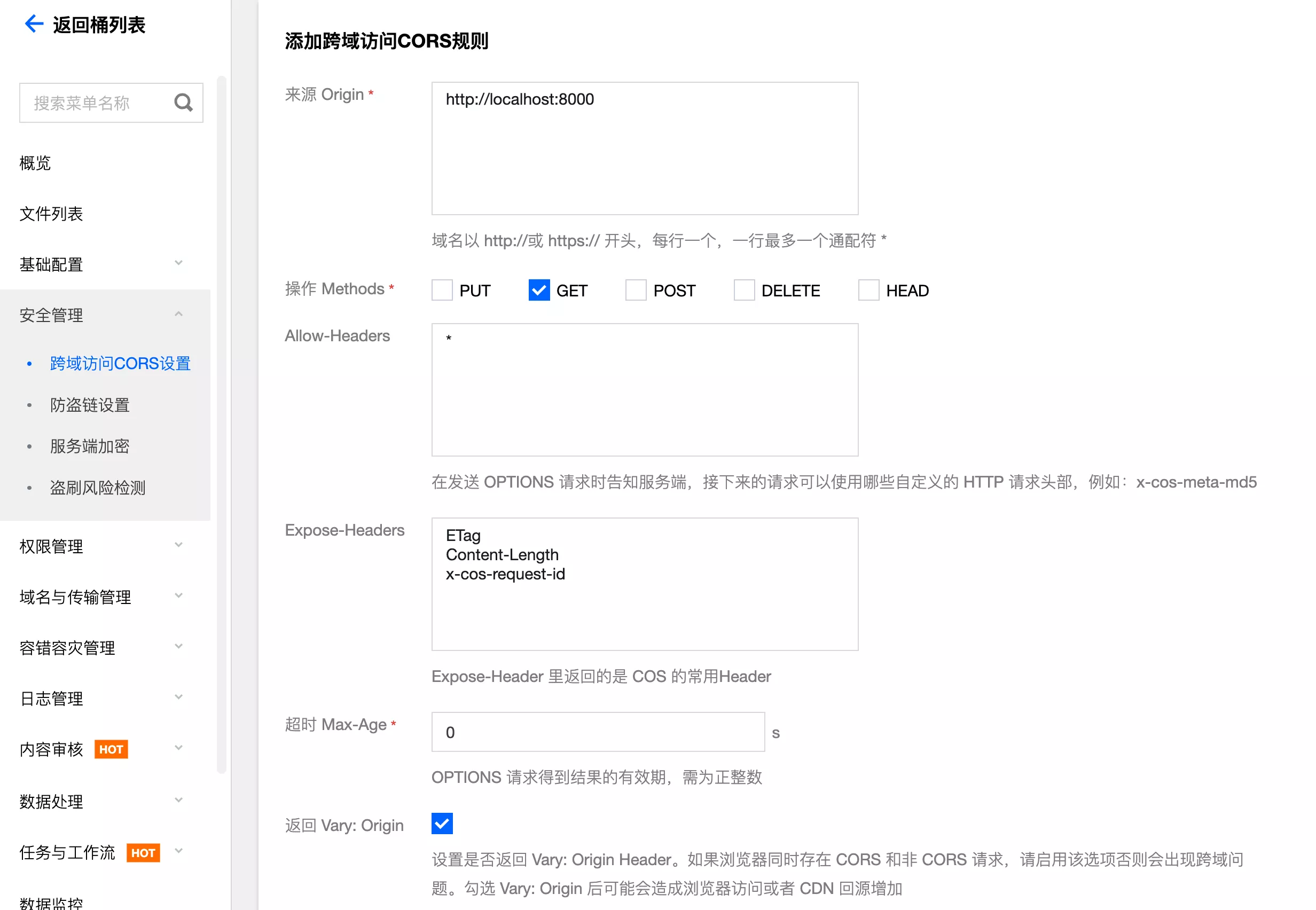
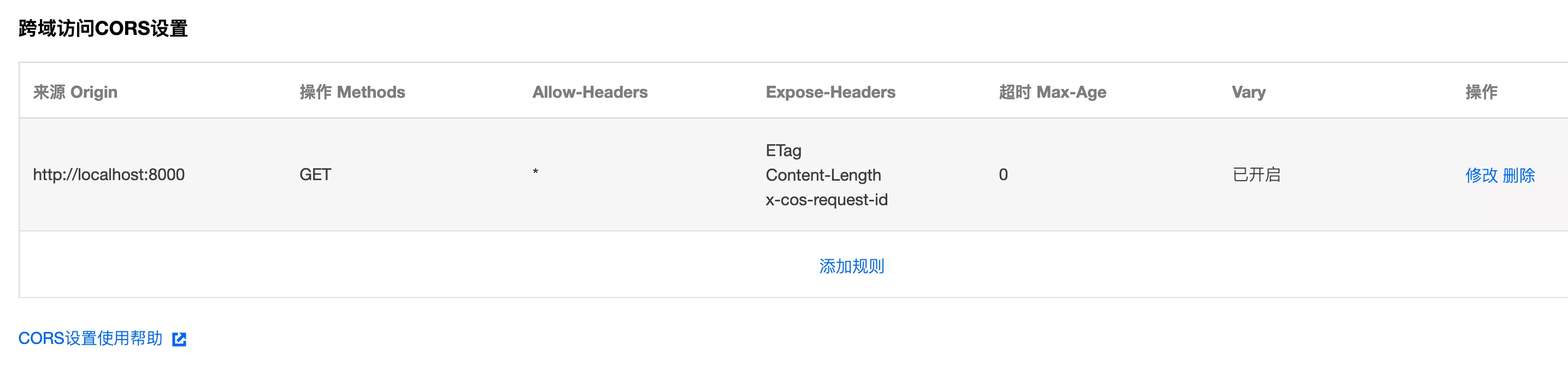
配置完成后,对象存储(服务端)就会允许该域名的跨域请求,可以灵活添加多条规则:
2. 防盗链
指在网站或应用程序中,直接引用并展示其他网站上的资源(如图片、音频、视频等),而未经该资源拥有者的许可
- A 用户有一个壁纸网站,B 用户直接把 A 用户网站的所有图片爬取到自己网站中,并且用 A 网站的图片地址展示,实际消耗的还是 A 网站的流量!这是一种成本极低、危害极大的攻击方式
- 原理:可以通过请求头中的
referer(网站请求来源)来进行校验,如果请求头中没有该字段,或不是预期的来源,就禁止请求
在控制台中进行防盗链配置 设置防盗链
- 假设项目上线的前端域名是
yupi.com,建议配置白名单,仅允许特定范围的域名访问,并且拒绝空 referer
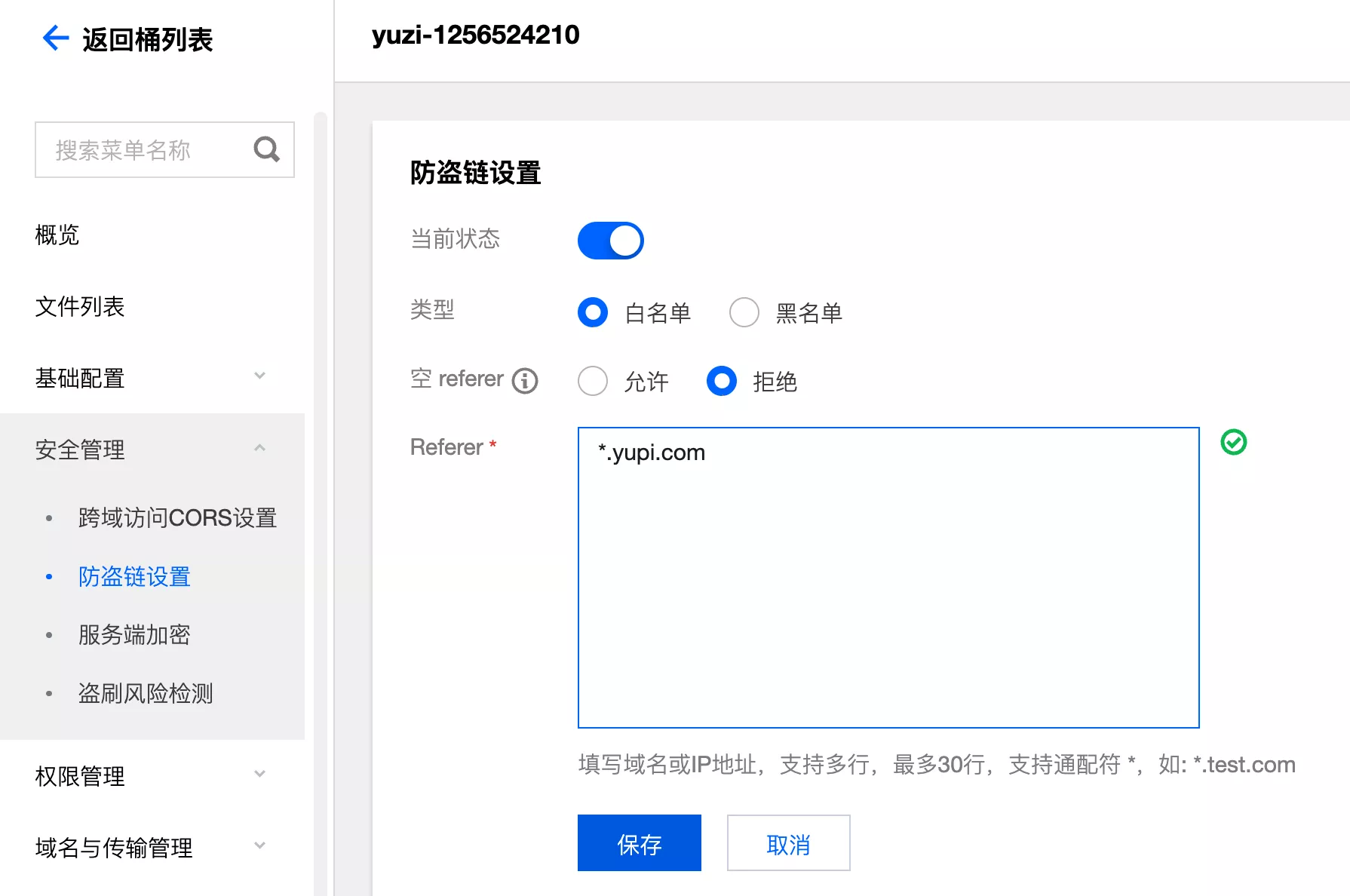
- 保存防盗链设置后,再打开本地域名为
localhost的前端网站,发现图片无法加载:
- 打开控制台,发现图片加载请求报错 403,访问被禁止,防盗链生效

- 再次修改防盗链允许的 Referer,增加
localhost域名
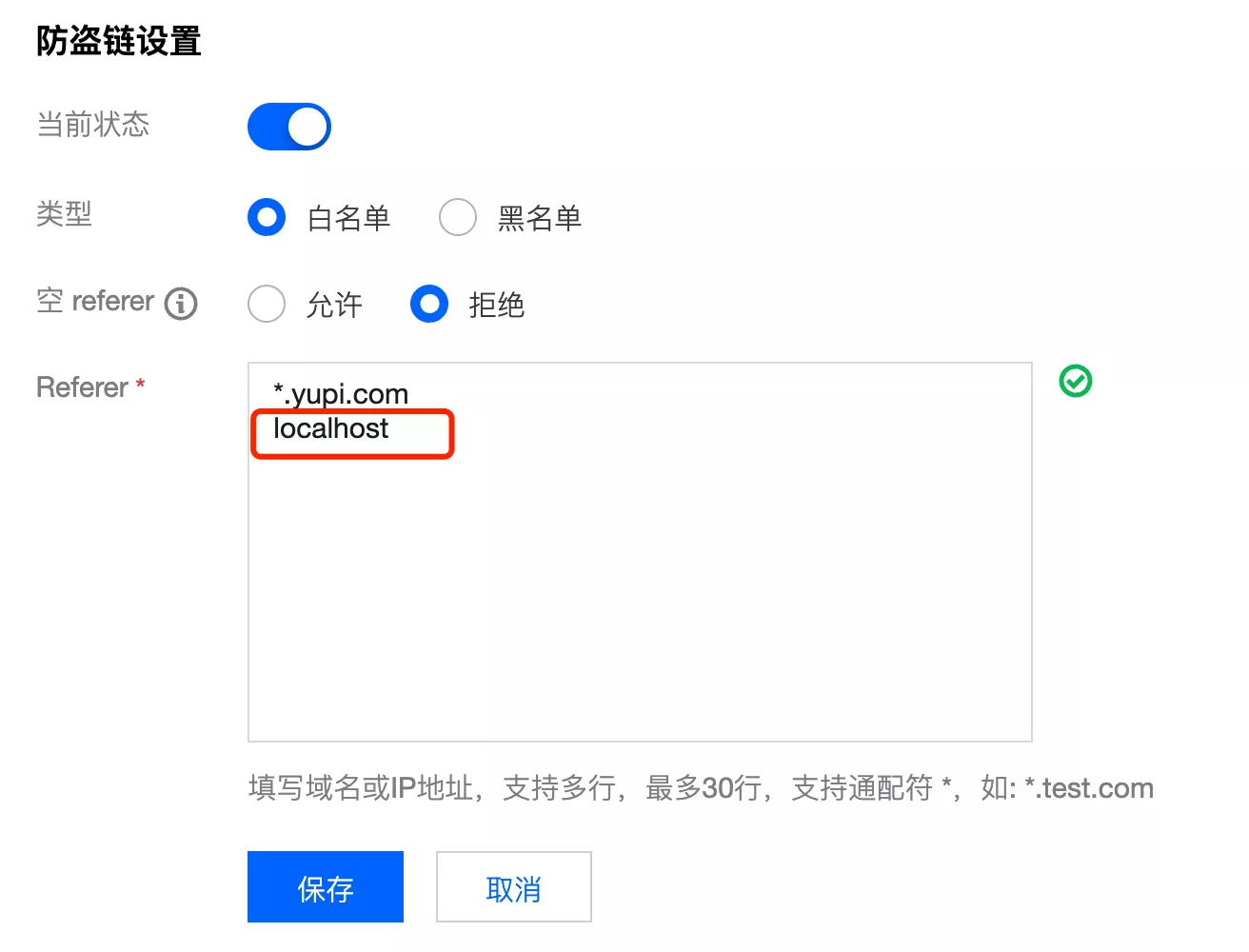
- 这次图片正常加载
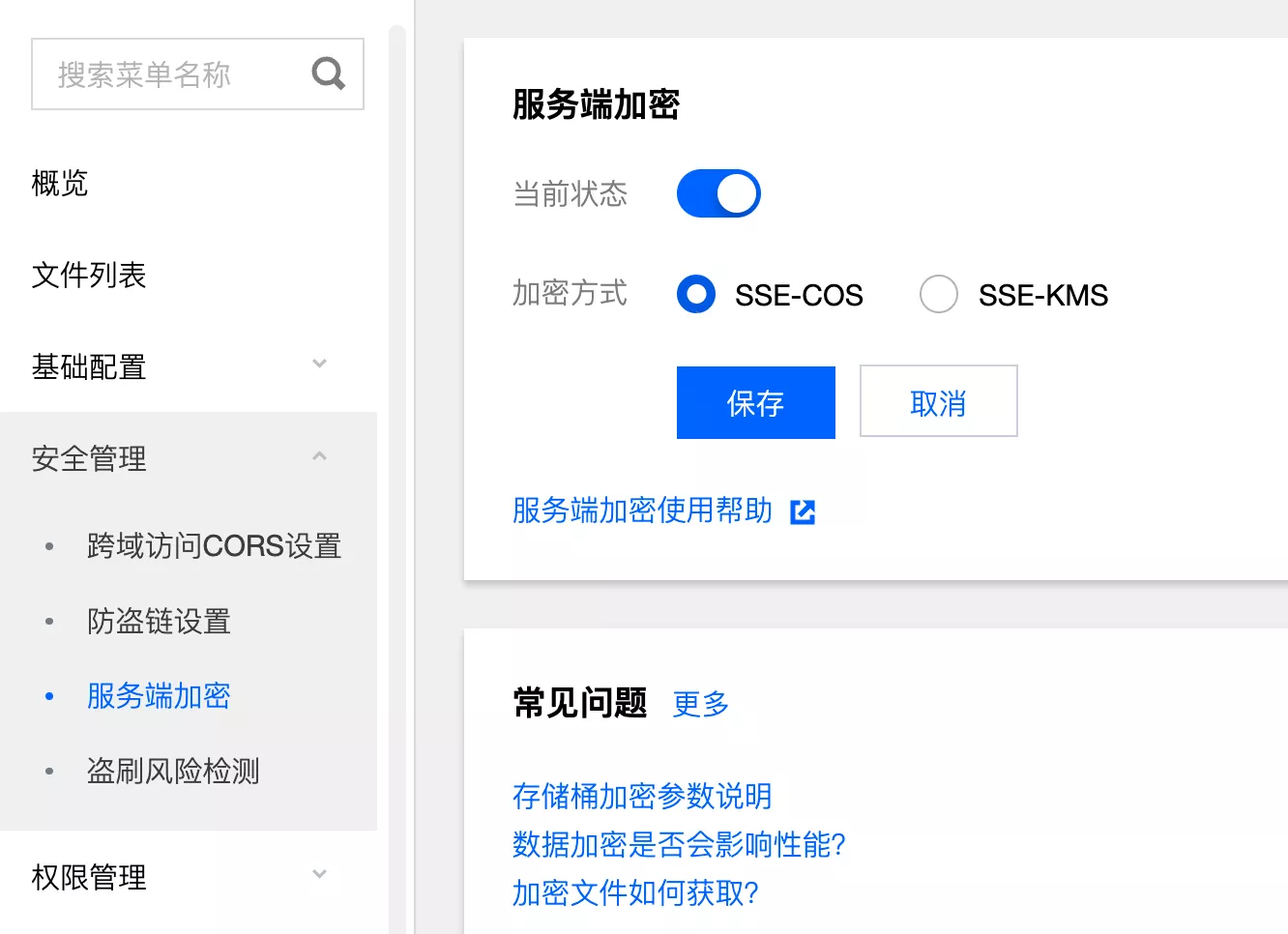
3. 服务端加密
- 加密存储:数据写入磁盘之前,对数据进行加密,并在访问数据时自动解密
- 加密传输:COS 提供用 HTTPS 部署 SSL 证书实现加密的功能,在传输链路层上建立加密层,确保数据在传输过程中不会被窃取及篡改
需要注意的是,文件加密会有一定的性能影响,慎重开启。官方原文:
文件加密需要用客户侧密钥,或者 COS 托管密钥,或者 KMS 密钥将文件内容加密成密文,因此会有一定的性能损耗,主要体现在访问延迟增加。这一延迟增加对大文件读写影响不明显,但在小文件读写中会有一定影响。
服务器加密控制台开启:
4. 盗刷风险检测
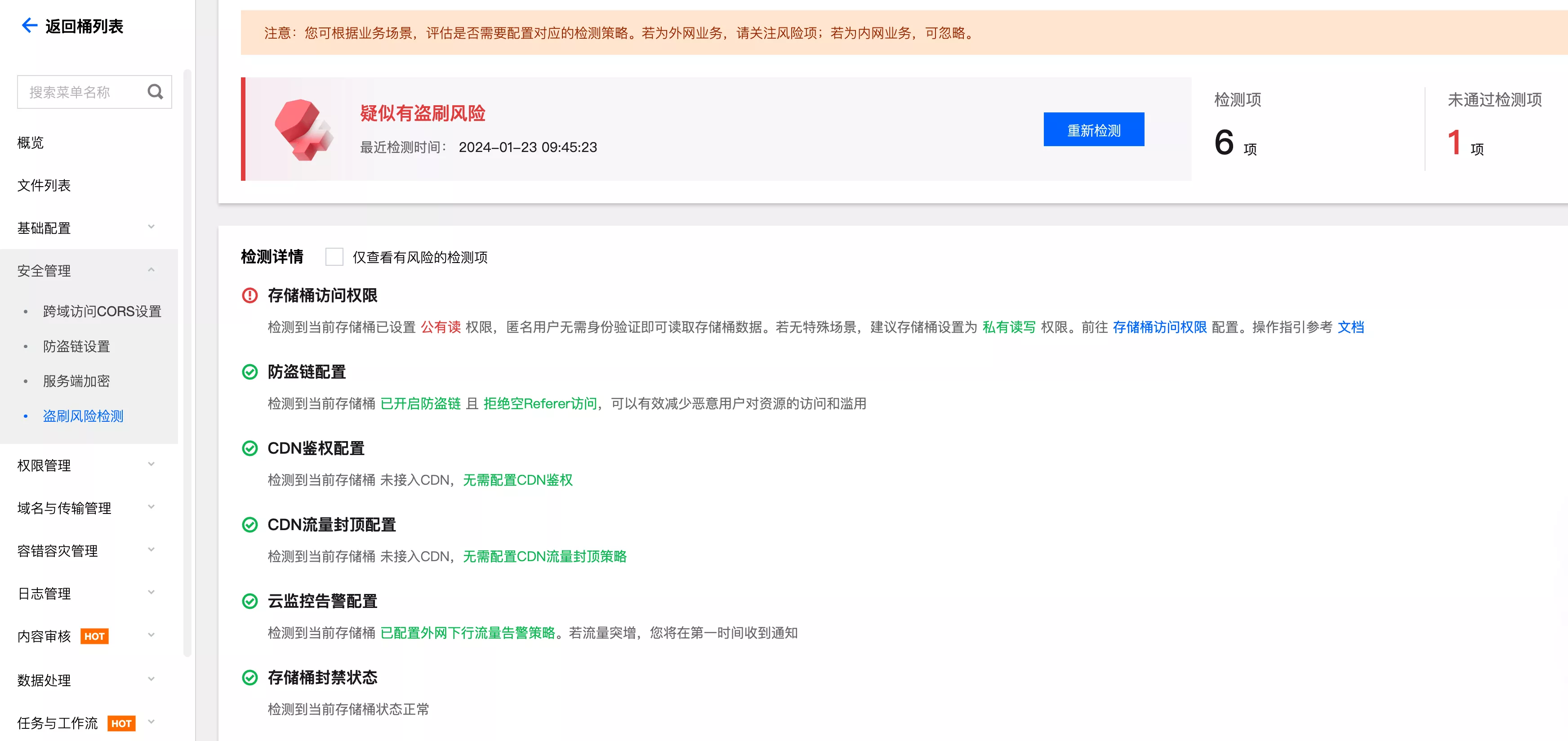
COS 提供了盗刷风险检测功能,非常实用,可以轻松发现潜在的安全风险
3. 现存权限风险
对系统的预期是,仅允许登录用户下载代码生成器文件。而现在用户只要知道文件在 COS 的存储地址,不用登录也可以直接访问下载。
- 比如访问:https://xxx.cos.ap-shanghai.myqcloud.com/generator_dist/1738875515482562562/7rkzyMn3-acm-template-pro-generator.zip(示例链接)
- 由于防盗链限制,无法直接得到文件:
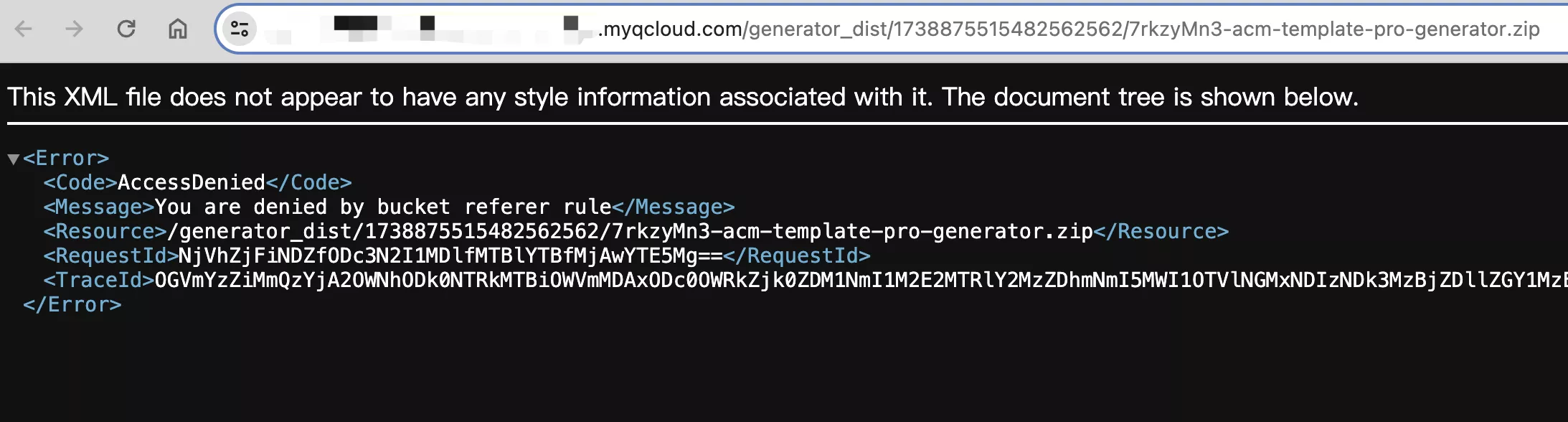
- 但别忘了,请求是可以构造的!比如复制请求信息为 cURL
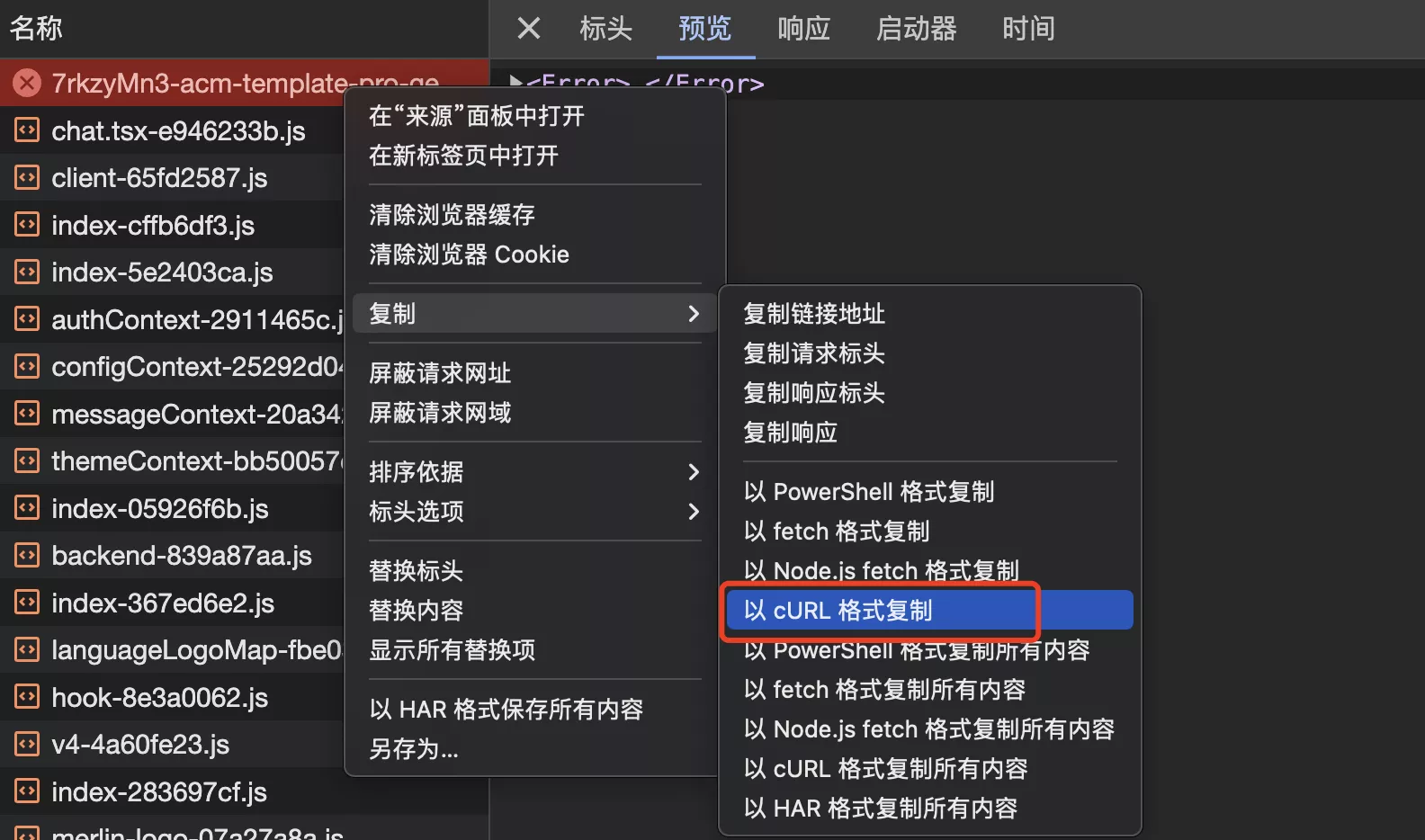
- 修改复制的脚本,追加请求头信息,并输出文件。文件能够被顺利下载
curl 'https://yuzi-1256524210.cos.ap-shanghai.myqcloud.com/generator_dist/1738875515482562562/7rkzyMn3-acm-template-pro-generator.zip' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'Accept-Language: zh-CN,zh;q=0.9' \
-H 'Cache-Control: no-cache' \
-H 'Referer: localhost:8000' \
-H 'Connection: keep-alive' \
-H 'Pragma: no-cache' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: none' \
-H 'Sec-Fetch-User: ?1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
--compressed
--output a.zip
4. 权限管理实践
需求:对于图片资源,允许所有用户读;对于其他文件(比如代码生成器产物包),禁止匿名用户访问
COS 对象存储提供了几种权限管理方法,用户的总权限为这三种管理方法的组合

- 存储桶访问权限:可以控制已有账号、子账号操作存储桶的权限。粒度较粗
- 自定义 policy 权限:可以更灵活地控制某个用户、在某个条件下、对某个资源的、某种操作权限。粒度更细
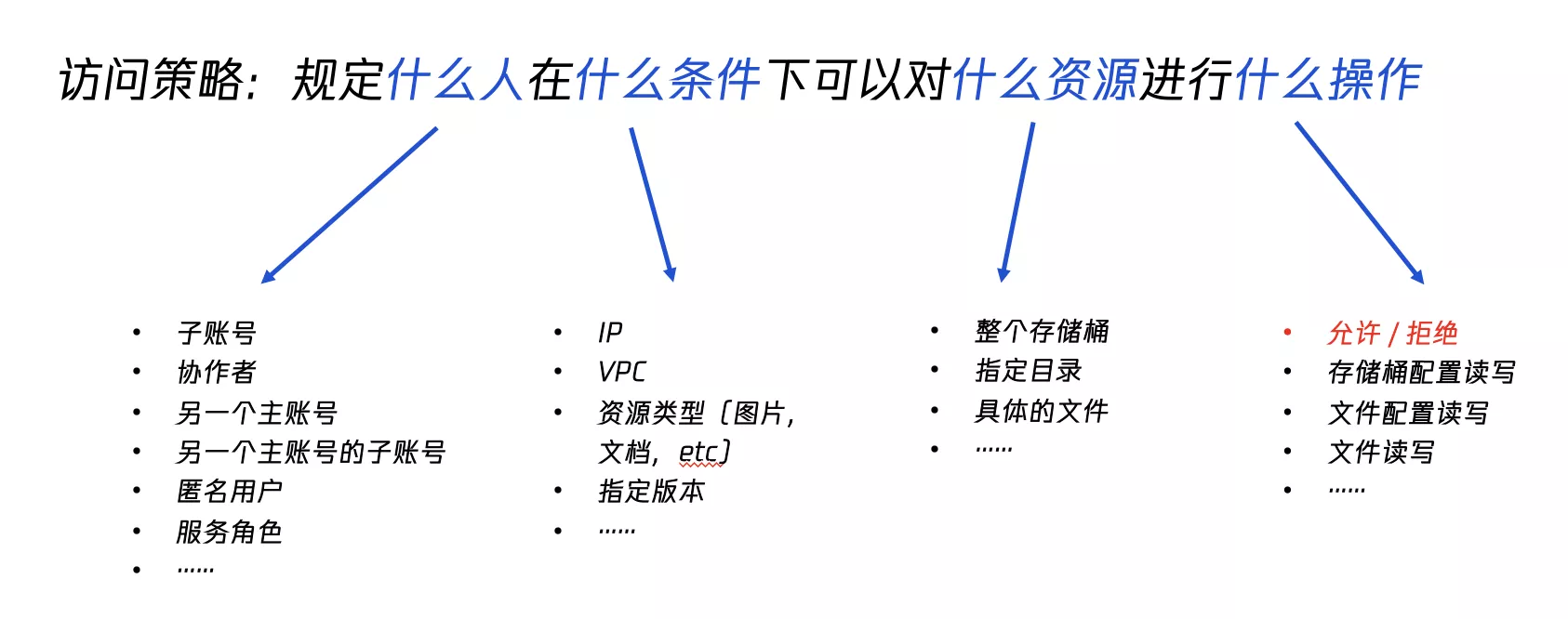
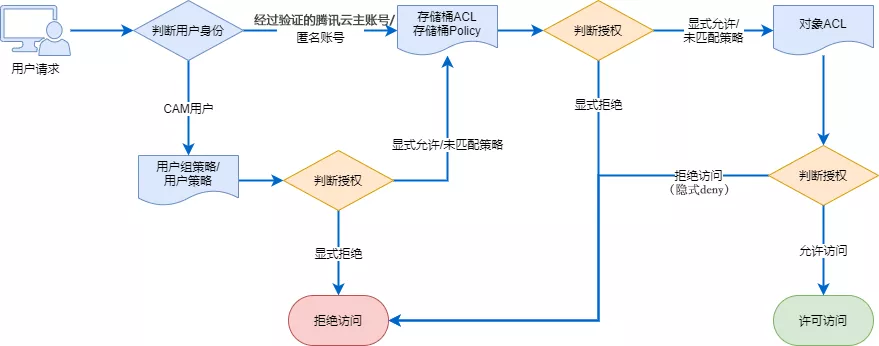
COS 对象存储权限校验流程图:访问策略评估流程
1. 创建子账户
首先创建一个子账户,不建议用主账户,因为权限过大,容易出现权限风险,管理控制台
快速创建子用户:
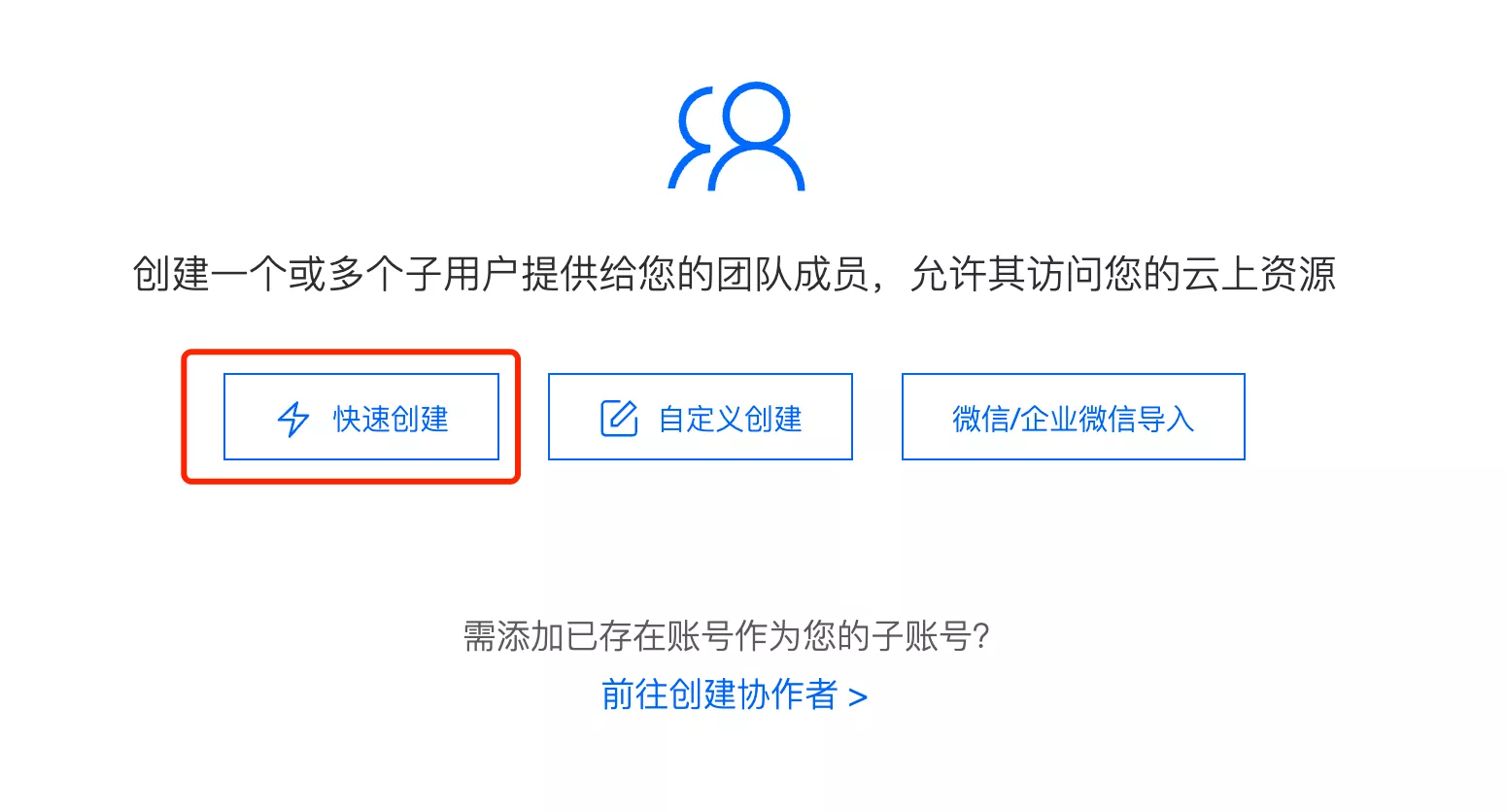
注意修改访问方式和用户具有的权限:
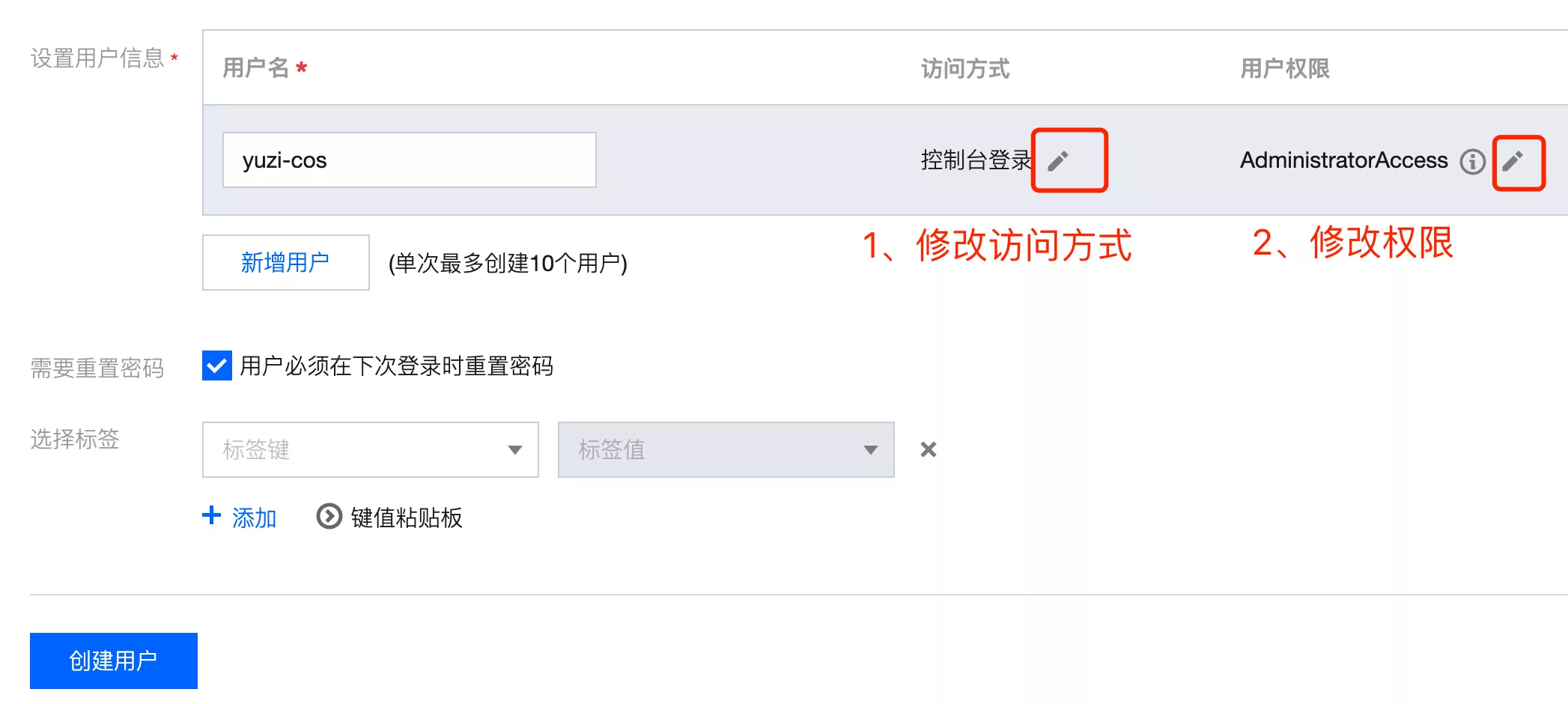
需要开启编程访问:

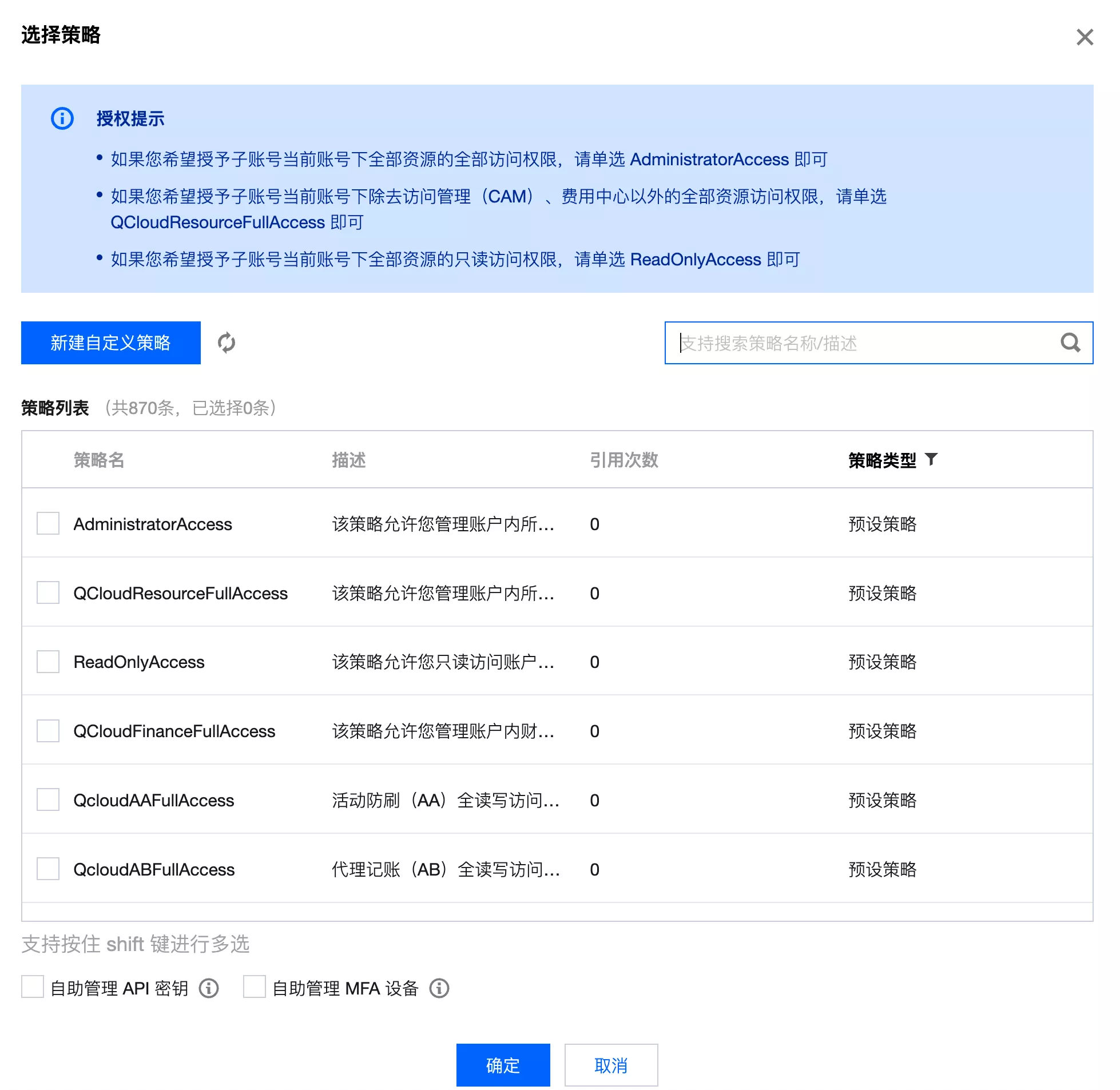
选择策略,直接取消所有默认权限,推荐一条一条按需添加:
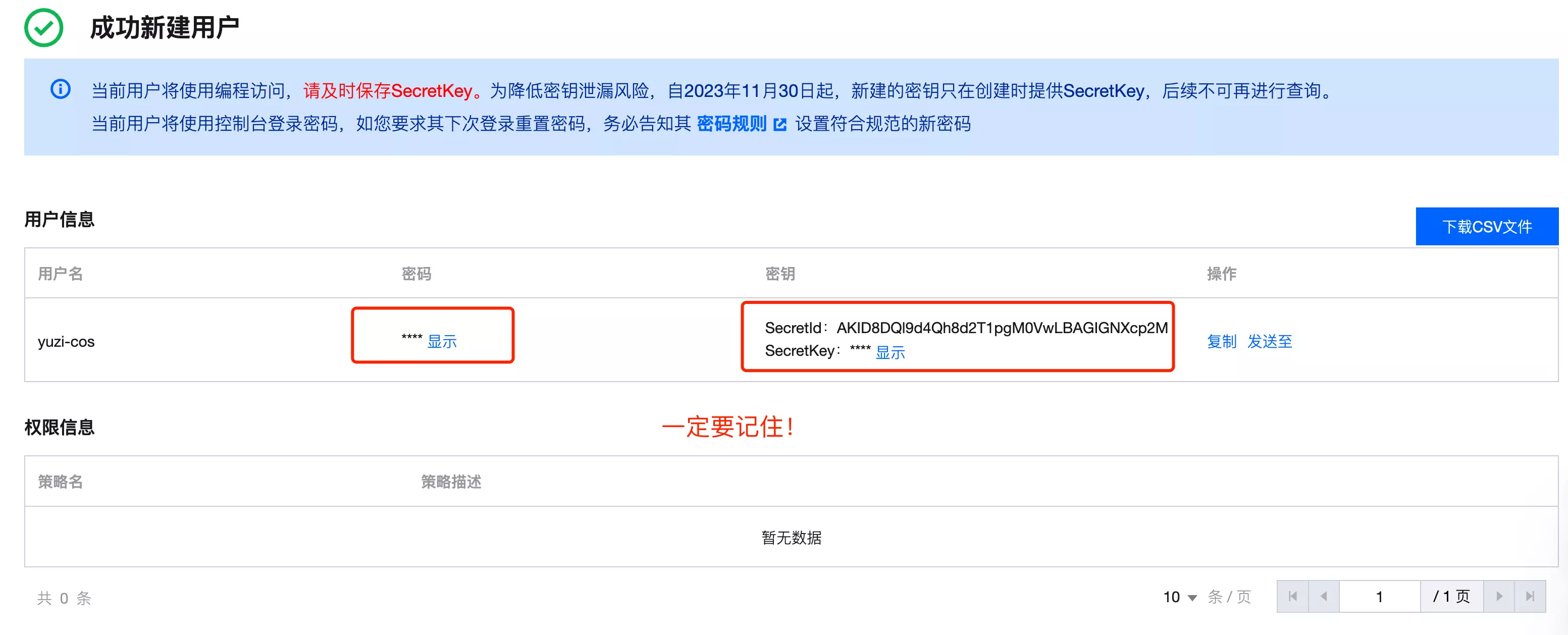
新建用户成功后,一定要保存好密码和 SecretKey!用于使用腾讯云 API 访问云资源(包括对象存储)。
2. 修改存储桶访问权限
遵循最小权限原则
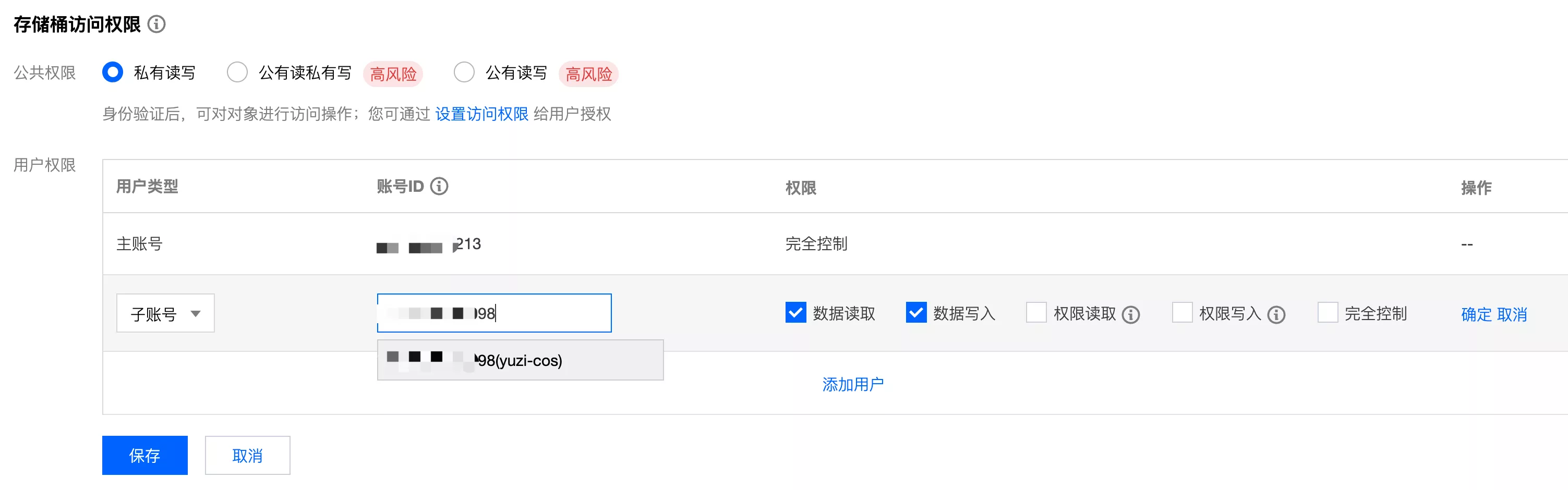
- 先将公共权限设置为 “私有读写”,保证只有授权用户才能访问
- 然后给新建的子用户增加访问存储桶的权限,注意保存:
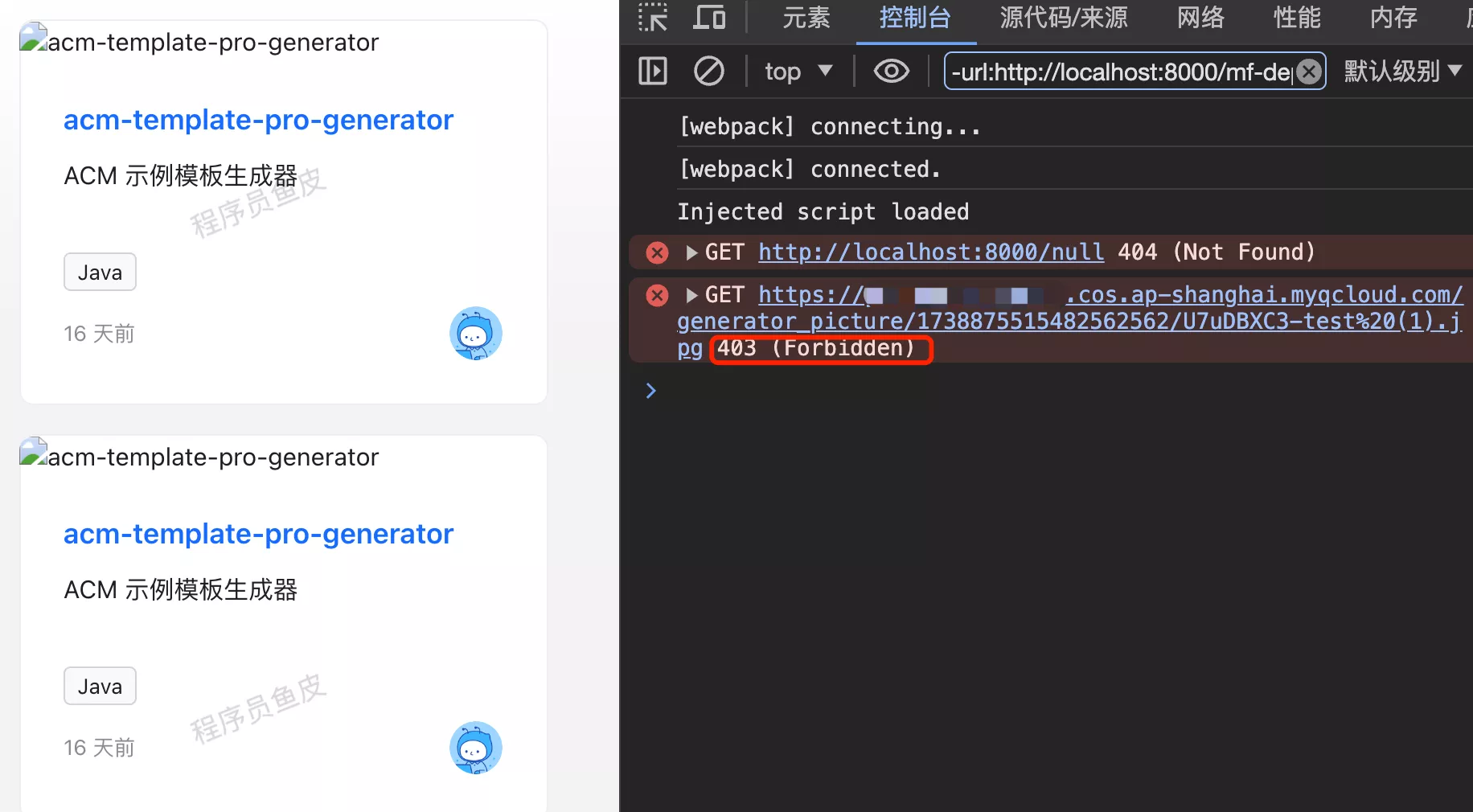
验证,图像已无法访问:
3. 配置Policy权限
开放图片的公开读权限,配置 policy 权限:
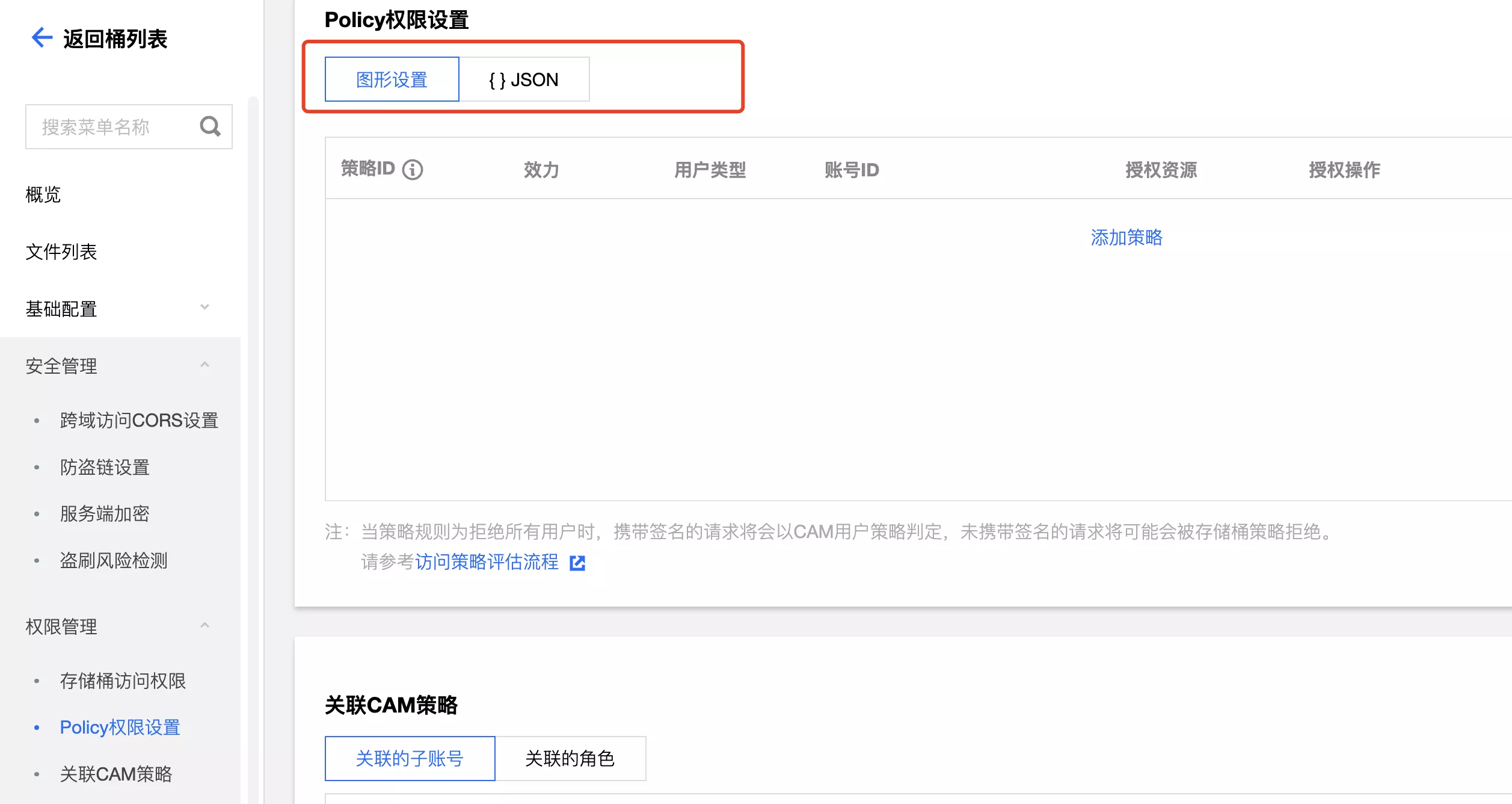
添加策略:
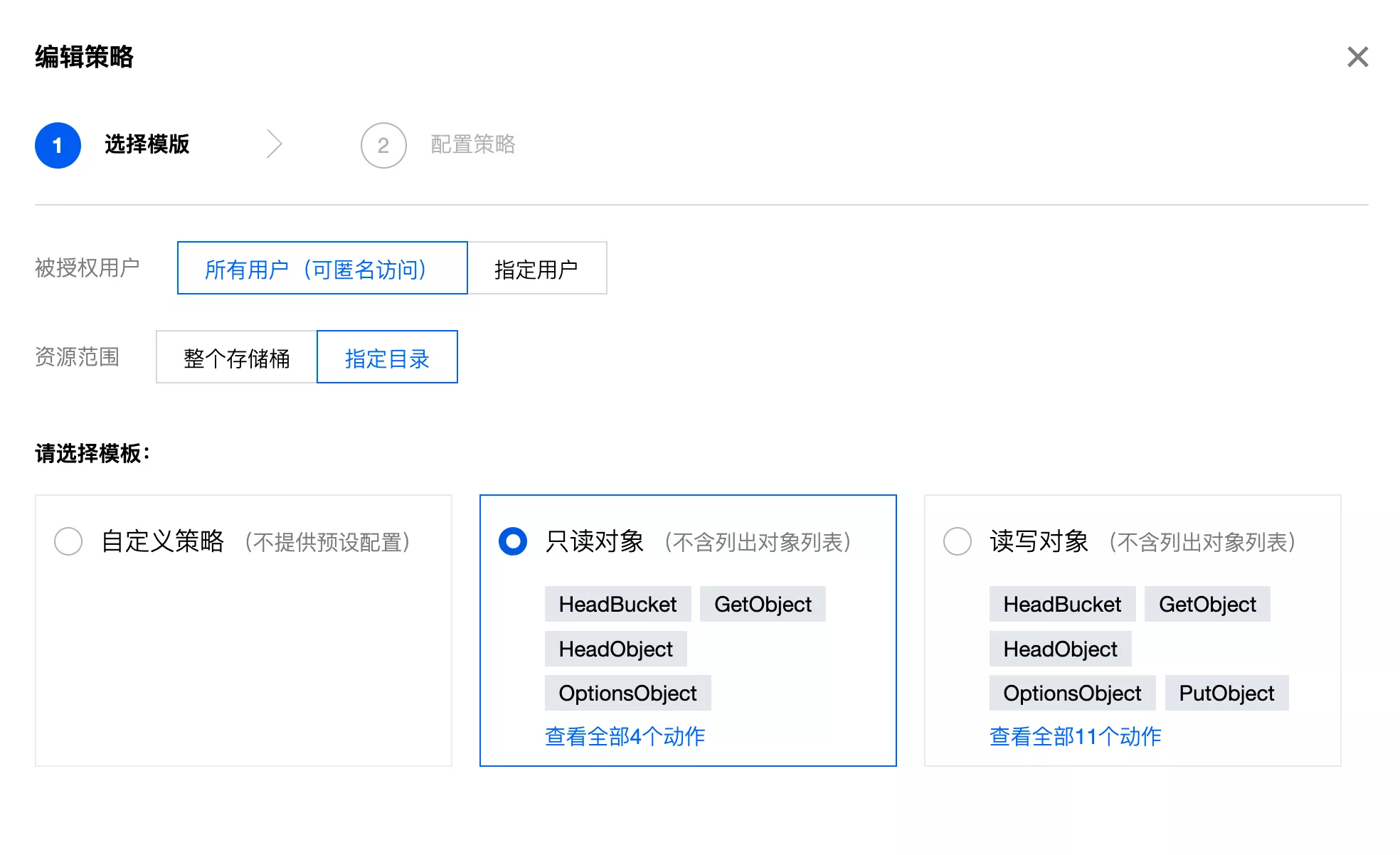
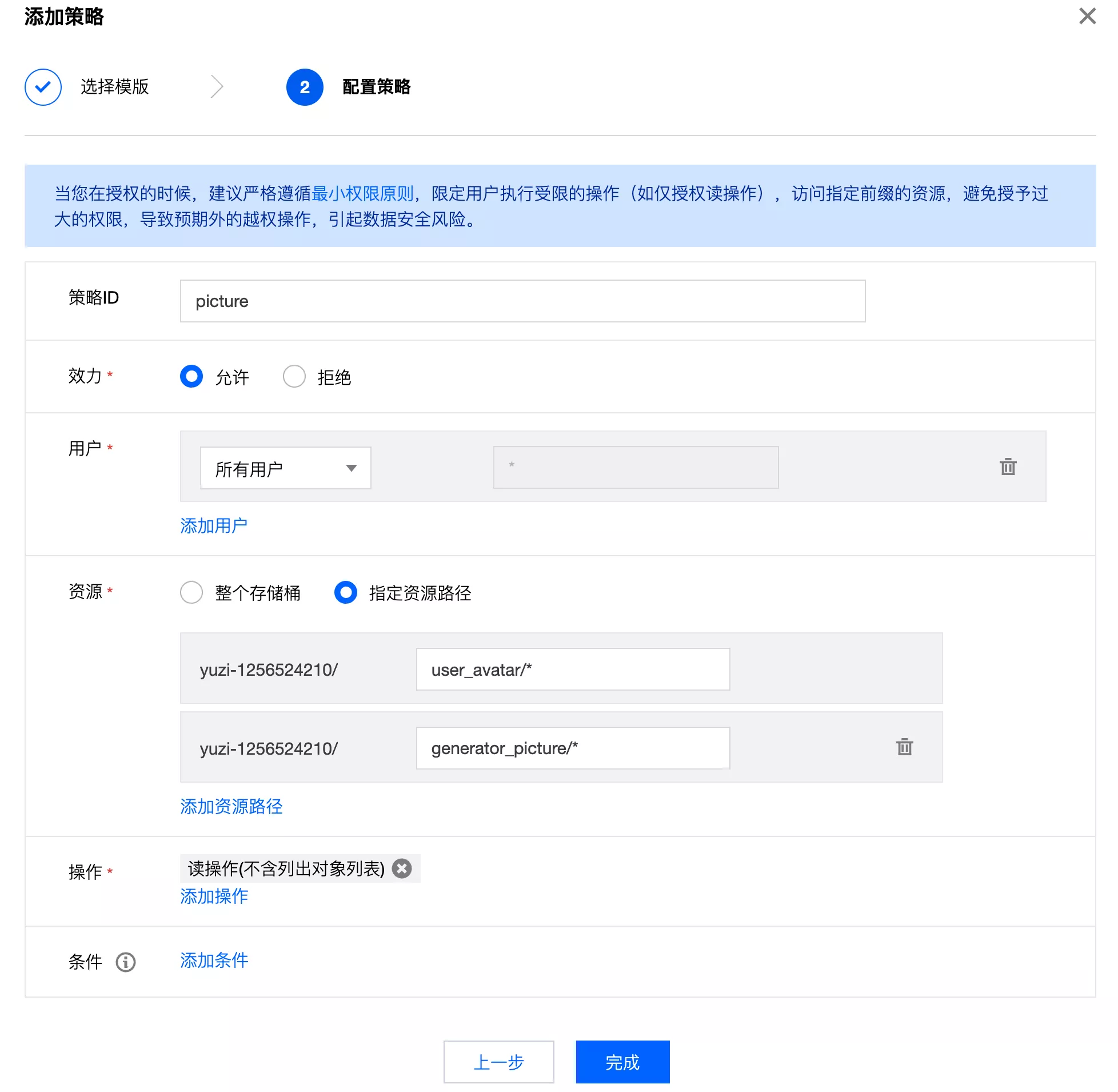
配置后再进行验证,用户头像和生成器封面能够正常加载。但是代码生成器无法直接通过客户端请求下载
可以先修改防盗链设置,允许空 referer,便于测试
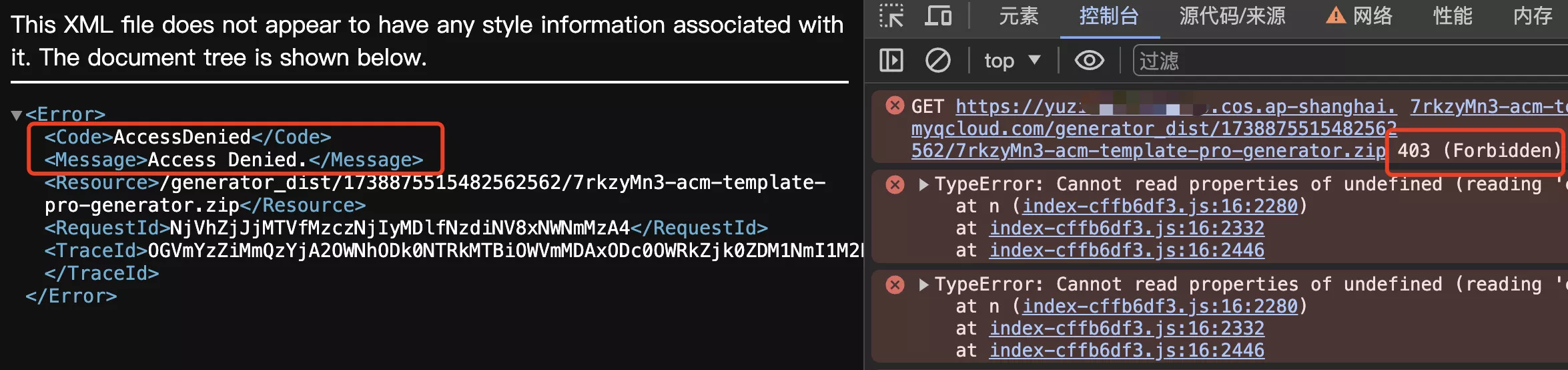
4. 验证程序访问
修改 application.yml,更换访问密钥为子用户的 SecretId 和 SecretKey。如果上传失败,请勿必保证已按上述步骤为子用户开通了权限。修改权限后可能 需要等待几分钟 才能生效
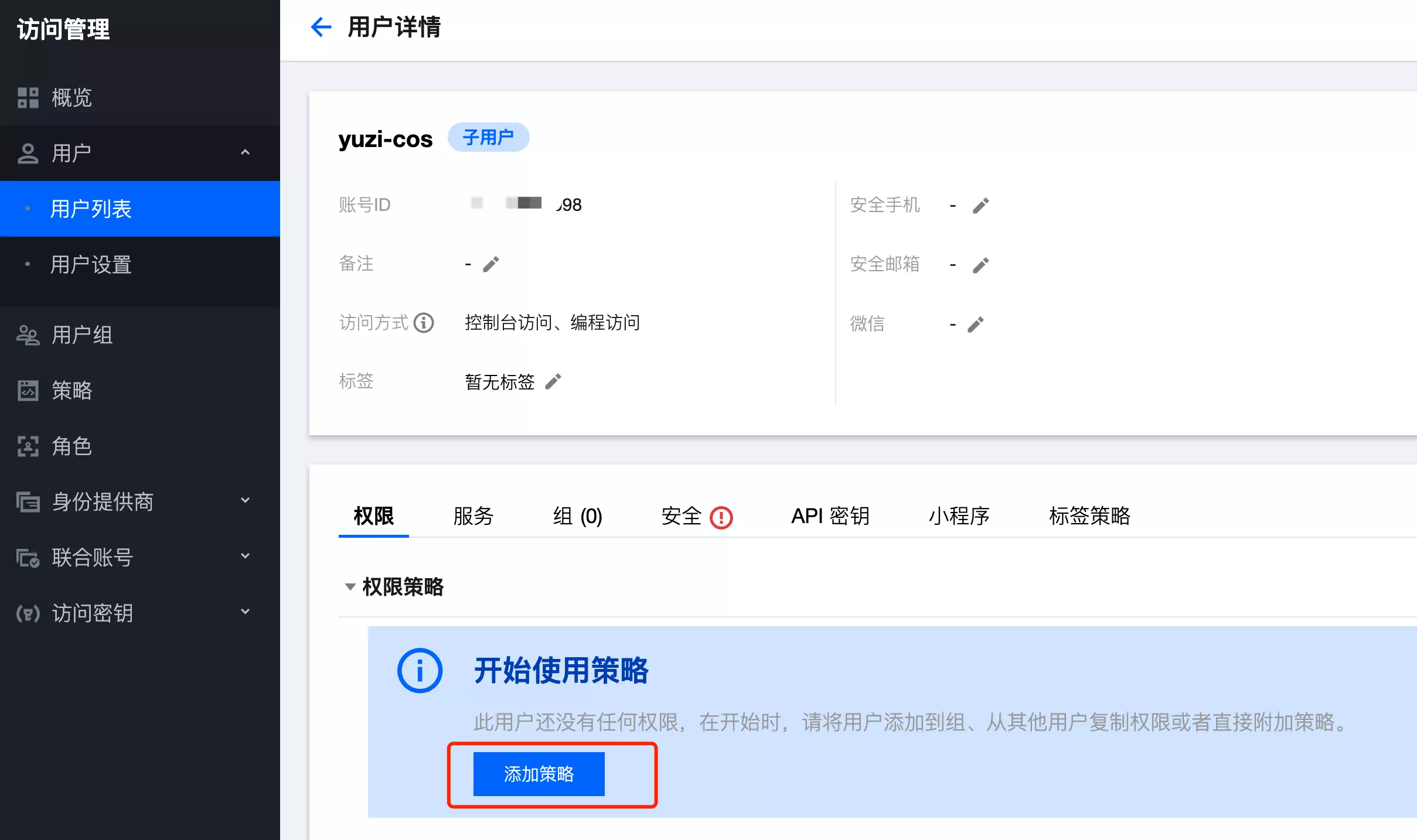
5. 其他授权方式
除了在修改存储桶访问权限中添加用户外,还可以直接给整个子用户添加存储桶访问权限。
- 进入用户详情页,添加使用策略:
- 添加对象存储数据读写权限
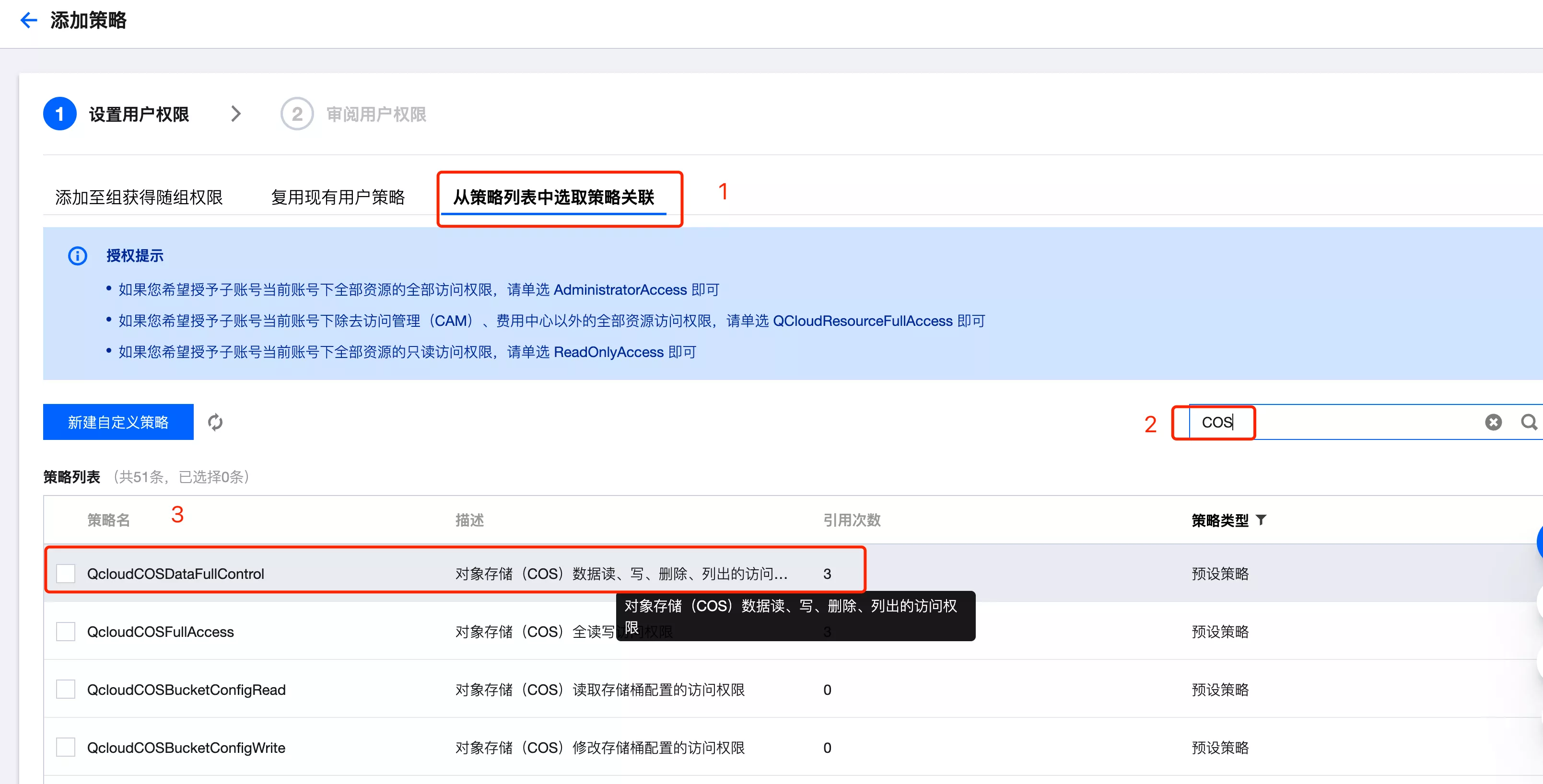
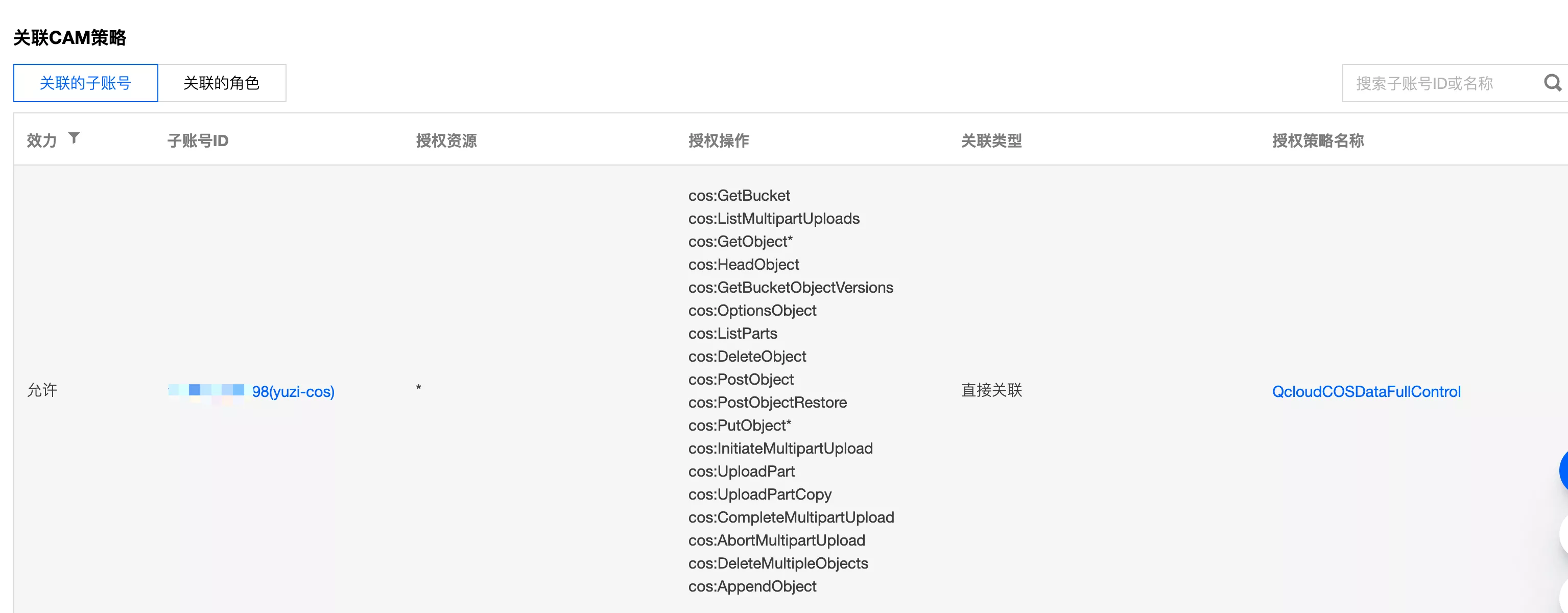
- 保存权限设置后,在权限管理的 “关联 CAM 策略” 中可以看到权限设置:
关联的 CAM 策略:分配的某个子账号或某个角色,具有的对象存储操作权限
还有一些保证安全性的方法。eg:生成临时操作对象的密钥,由于是服务端上传,而不是前端直传对象存储,所以不需要这么做