13-性能优化
1. 性能优化思路
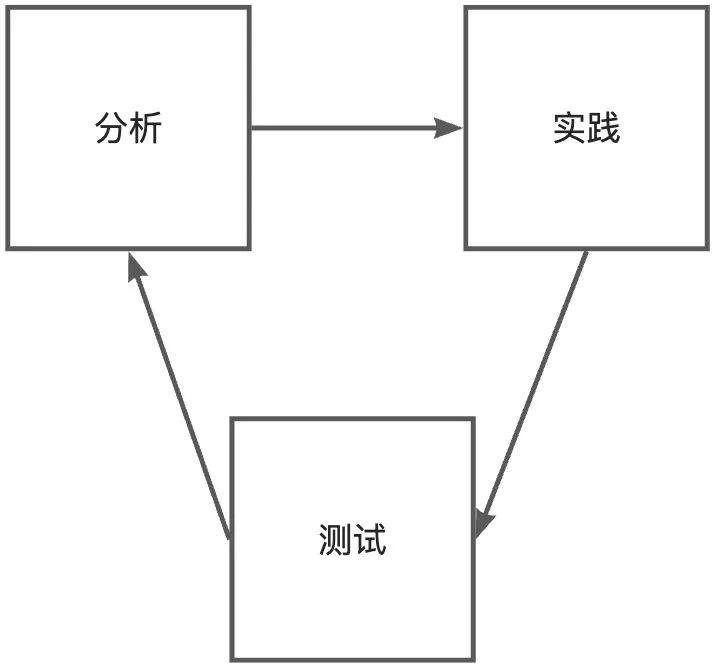
通过 持续的 分析、实践和测试,确保系统稳定高效运行,从而满足用户的诉求
1. 性能优化分类
- 通用优化
- 是指一些经典的、对于绝大多数情况都适用的优化策略
- eg:增大服务器的并发请求处理数、使用缓存减少数据库查询、通过负载均衡分摊请求、同步转异步等
- 对症下药
- 是指结合具体的业务特性和系统现状,先通过性能监控工具、压力测试等方式,分析出系统的性能瓶颈,再针对性地选取策略进行优化
- eg:数据库单次查询超过 1 秒,属于慢查询,根据实际的查询条件给对应的字段增加索引,一般就能提高查询性能
实际开发中,这两类性能优化策略通常都要使用
- 在系统设计和开发阶段,根据经验,本能地引入一些性能优化的手段,降低后续系统出现问题、需要迭代优化的概率
- 性能优化一定是持续的,随着需求、用户、系统用量的增多,原本性能符合要求的系统也可能会出现各种新的问题,很难面面俱到、一步到位
- 对于复杂的、对可用性和稳定性要求极高的项目,可以提前通过压力测试来模拟用户量极大的情况,并提前做好性能优化和应对措施
2. 通用性能优化手段
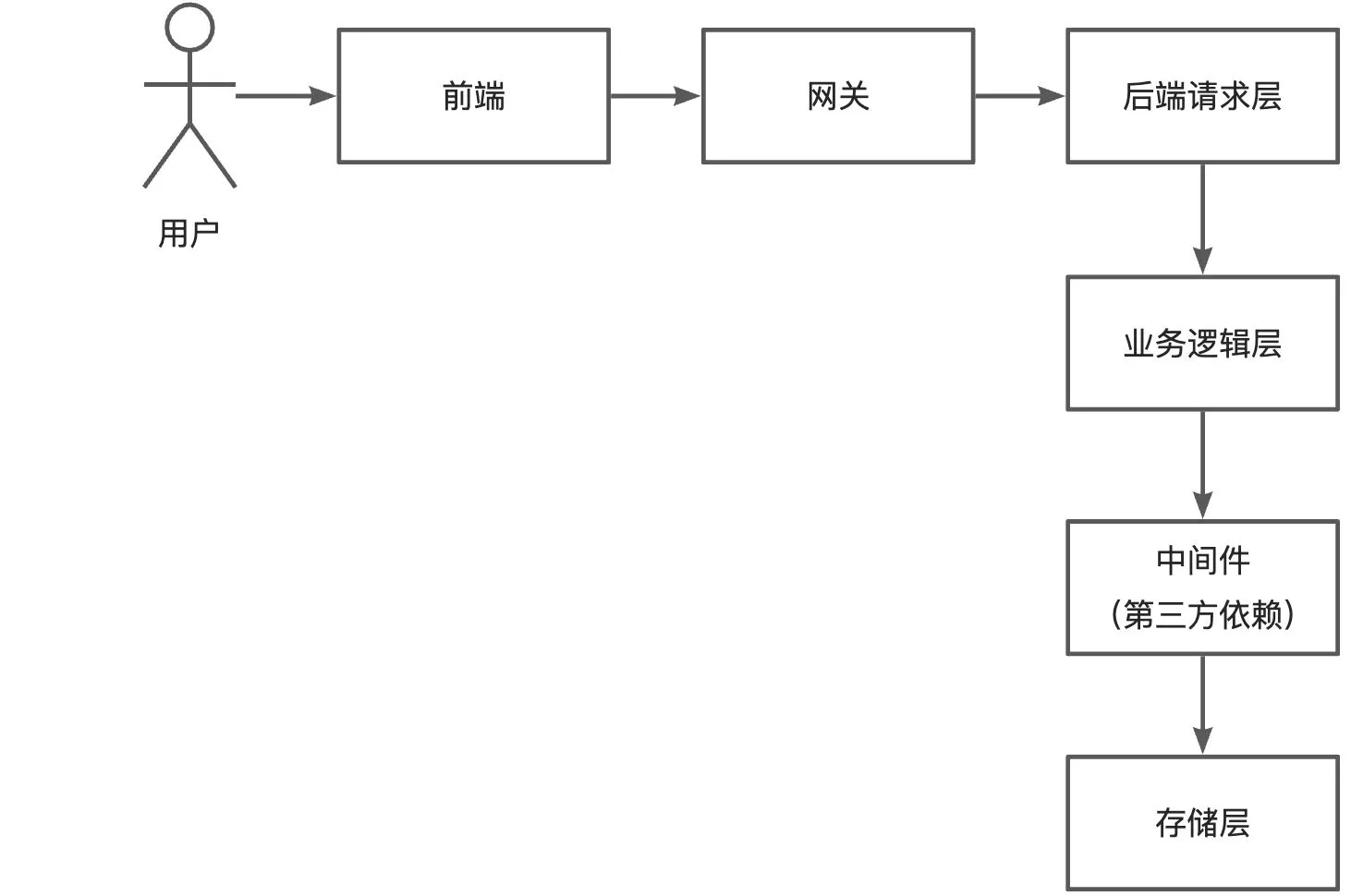
每个节点,对应的优化方法:
- 前端:
- 离线缓存:利用浏览器的缓存机制,请求过一次的资源就不用重复请求,提高页面加载速度
- 请求合并:页面请求过多时,将多个小请求合并成一个大请求,减少网络开销
- 懒加载:延迟加载页面的图片等元素,提高首屏加载速度
- 网关:
- 负载均衡:负责接受请求,根据一定的路由算法转发到对应的后端系统,实现多个后端服务器分摊请求,增大并发量
- 缓存:将后端返回的数据进行缓存,下次前端请求时,直接从网关获取数据,减少后端调用、提高数据获取速度
- 后端请求层:
- 服务器优化:根据业务特性,选择性能更高的服务器并调整参数,eg:Nginx、Undertow 等
- 微服务:将大型服务拆分为小型服务,并通过微服务网关进行转发,增大各服务的并发处理能力
- 业务逻辑层:
- 异步化:将同步的业务逻辑改为异步,尽早响应,提高并发处理能力
- 多线程:将复杂的操作拆分成多个任务,通过多线程并发执行,提高任务处理效率
- 中间件(第三方依赖):
- 缓存:将 DB 查询出的结果数据缓存到性能更高的服务(eg:Redis 或本地),减少 DB 的压力、并提高数据查询性能
- 队列:使用消息队列,对系统进行解耦、或将操作异步化,实现流量的削峰填谷
- 存储层:
- 分库分表:数据量极大时,对数据库进行垂直或水平切分,提高数据库并发处理能力
- 数据清理:定期清理无用或过期的数据,减少存储压力,必要时可以对数据进行备份转储
2. 核心功能性能优化
先从耗时较长的功能下手,优化空间会更大一些
1. 下载生成器接口
1. 整体测试分析
先不关注接口的细节,直接调用并查看接口的整体耗时
修改 application.yml 配置文件,解除文件上传大小限制:
# 文件上传
servlet:
multipart:
# 大小限制
max-request-size: 100MB
max-file-size: 100MB
测试上传并下载一个 30 MB 文件,发现性能急剧下降
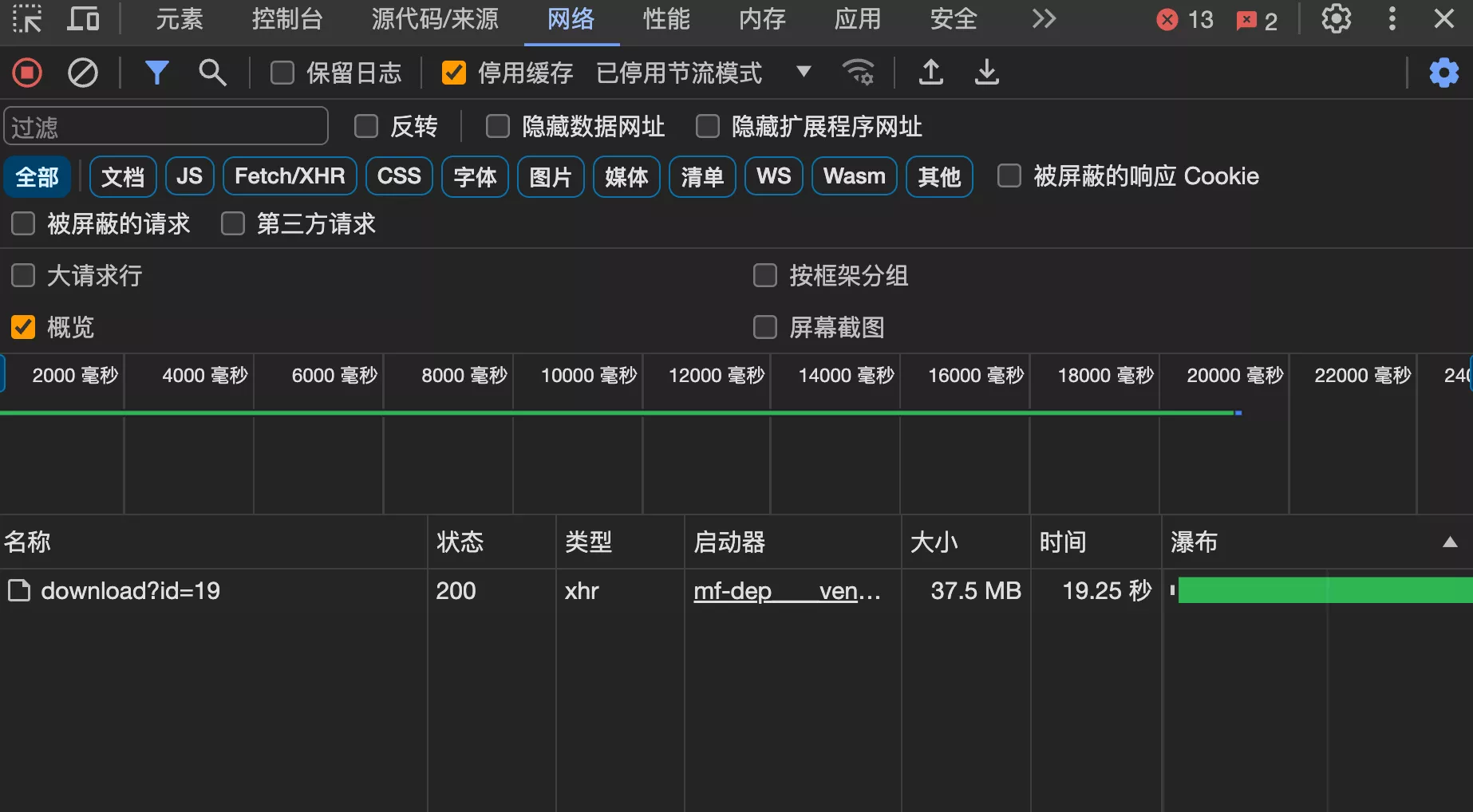
系统用户量不多的情况下,问题不大
- 多个用户同时下载
- 大量用户频繁下载这个文件,服务器的带宽可能会有压力
- 每次下载都会消耗对象存储的流量,都是成本!
2. 分析代码耗时
使用 Spring 提供的 StopWatch 计时器工具类,给下载接口添加统计耗时代码
StopWatch stopWatch = new StopWatch();
stopWatch.start();
COSObject cosObject = cosManager.getObject(filepath);
cosObjectInput = cosObject.getObjectContent();
// 处理下载到的流
byte[] bytes = IOUtils.toByteArray(cosObjectInput);
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
通过统计耗时发现,最核心的耗时因素在于 从第三方对象存储服务下载文件(先下载完整文件到服务器后,再整体写入到响应输出流
// 处理下载到的流,本质上是下载完整文件到服务器
byte[] bytes = IOUtils.toByteArray(cosObjectInput);
// 写入响应输出流
response.getOutputStream().write(bytes);
response.getOutputStream().flush();
3. 下载优化 - 遵循最佳实践
- 使用 CDN 就近下载(额外的开销)、调试下载操作相关对象的参数等

4. 下载优化 - 流式处理
下载大文件时,除了下载慢之外,还占用服务器的内存、硬盘空间,导致资源紧张
- 如果文件较大、并且服务端不用处理文件,可以选用流式处理,通过循环的方式,持续从
COSObjectInputStream读取数据并写进响应输出流,防止过大的文件占满内存
// 设置响应头
response.setHeader(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=" + fileName);
response.setContentType(MediaType.APPLICATION_OCTET_STREAM_VALUE);
// 将 InputStream 写入到 HttpServletResponse 的 OutputStream
try (OutputStream out = response.getOutputStream()) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = cosObjectInput.read(buffer)) != -1) {
out.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
// 处理异常
e.printStackTrace();
}
- 前端进行测试,发现采用这种方式后,下载文件时响应内容的大小会逐渐递增,而不是阻塞半天后一次性得到完整的响应结果
- 大文件整体的下载时间并没有减少。因为无论是否流失处理,服务器都要先从 COS 对象存储下载文件,再返回给前端
5. 下载优化 - 本地缓存
代码生成器文件的业务特点是 读多写少,典型的缓存适用场景
- 其实 CDN 本质上就是一种缓存,使用 CDN 增加开销
- 可以选用本地缓存。不需要引入额外的存储技术,只需要将下载过一次的代码生成器保存在服务器上,再下载时,直接读取并返回给前端即可
缓存的 4 个核心要素:
- 缓存哪些内容?
- 缓存如何淘汰?
- 缓存 key 如何设计?
- 如何保证缓存一致性?
- 在
GeneratorController中编写一个缓存生成器的接口cacheGenerator
/**
* 缓存代码生成器
*
* @param generatorCacheRequest
* @param request
* @param response
*/
@PostMapping("/cache")
@AuthCheck(mustRole = UserConstant.ADMIN_ROLE)
public void cacheGenerator(@RequestBody GeneratorCacheRequest generatorCacheRequest, HttpServletRequest request, HttpServletResponse response) {
if (generatorCacheRequest == null || generatorCacheRequest.getId() <= 0) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
// 获取生成器
long id = generatorCacheRequest.getId();
Generator generator = generatorService.getById(id);
if (generator == null) {
throw new BusinessException(ErrorCode.NOT_FOUND_ERROR);
}
String distPath = generator.getDistPath();
if (StrUtil.isBlank(distPath)) {
throw new BusinessException(ErrorCode.NOT_FOUND_ERROR, "产物包不存在");
}
// 缓存空间
String zipFilePath = getCacheFilePath(id, distPath);
// 新建文件
if (!FileUtil.exist(zipFilePath)) {
FileUtil.touch(zipFilePath);
}
// 下载生成器
try {
cosManager.download(distPath, zipFilePath);
} catch (InterruptedException e) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "压缩包下载失败");
}
}
- 设计缓存 key
- 缓存 key 相当于数据的 id,用来唯一标识和查找某个缓存内容
/**
* 获取缓存文件路径
*
* @param id
* @param distPath
* @return
*/
public String getCacheFilePath(long id, String distPath) {
String projectPath = System.getProperty("user.dir");
String tempDirPath = String.format("%s/.temp/cache/%s", projectPath, id);
String zipFilePath = String.format("%s/%s", tempDirPath, distPath);
return zipFilePath;
}
- 修改生成器下载接口,优先从缓存获取
// 追踪事件
log.info("用户 {} 下载了 {}", loginUser, distPath);
// 设置响应头
response.setContentType("application/octet-stream;charset=UTF-8");
response.setHeader("Content-Disposition", "attachment; filename=" + distPath);
// 优先从缓存读取
String zipFilePath = getCacheFilePath(id, distPath);
if (FileUtil.exist(zipFilePath)) {
// 写入响应
Files.copy(Paths.get(zipFilePath), response.getOutputStream());
return;
}
COSObjectInputStream cosObjectInput = null;
try {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
COSObject cosObject = cosManager.getObject(distPath);
cosObjectInput = cosObject.getObjectContent();
// 处理下载到的流
byte[] bytes = IOUtils.toByteArray(cosObjectInput);
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
// 写入响应
response.getOutputStream().write(bytes);
response.getOutputStream().flush();
} catch (Exception e) {
log.error("file download error, filepath = " + distPath, e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "下载失败");
} finally {
if (cosObjectInput != null) {
cosObjectInput.close();
}
}
- 测试调用
- 使用文件缓存后,接口响应时长大幅缩短!只需 100 多毫秒就能完成下载,快了 100 多倍!
实际项目开发中,还应该做以下几点:
- 除了调用接口缓存外,还可以通过一些方法自动识别出热点生成器并缓存
- 增加使用次数字段统计使用情况,然后通过定时任务(或每次下载后)检测使用情况是否超过热点阈值,超过的话表示是热点数据,设置缓存
推荐开源的热 key 发现系统。京东 HotKey
- 设置合适的缓存淘汰机制
- 比如编写一个清理缓存的接口,人工定期清理;或者给缓存设置一个过期时间,通过定时任务定期清理
- 保证缓存一致性
- 如果用户重新上传了代码生成器文件,应该保证用户下载到的不是缓存而是最新的文件
- 最简单的实现方式:更新时删除缓存,还可以使用延迟双删等策略
2. 使用生成器接口
相比生成器下载,这个接口的逻辑更复杂,耗时操作可能包括下载文件、执行脚本、压缩解压等
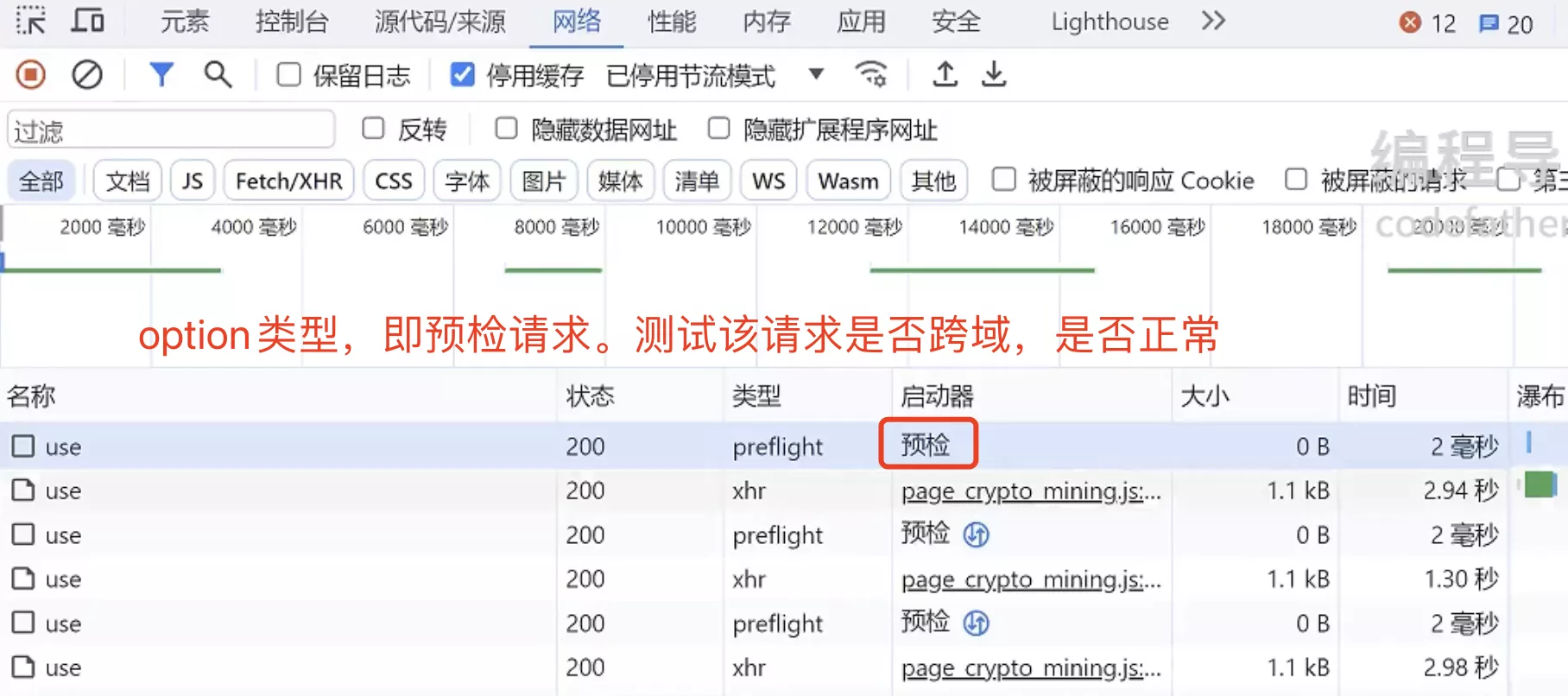
1. 整体测试
按 F12 打开网络请求控制台,先整体测试使用接口的耗时:
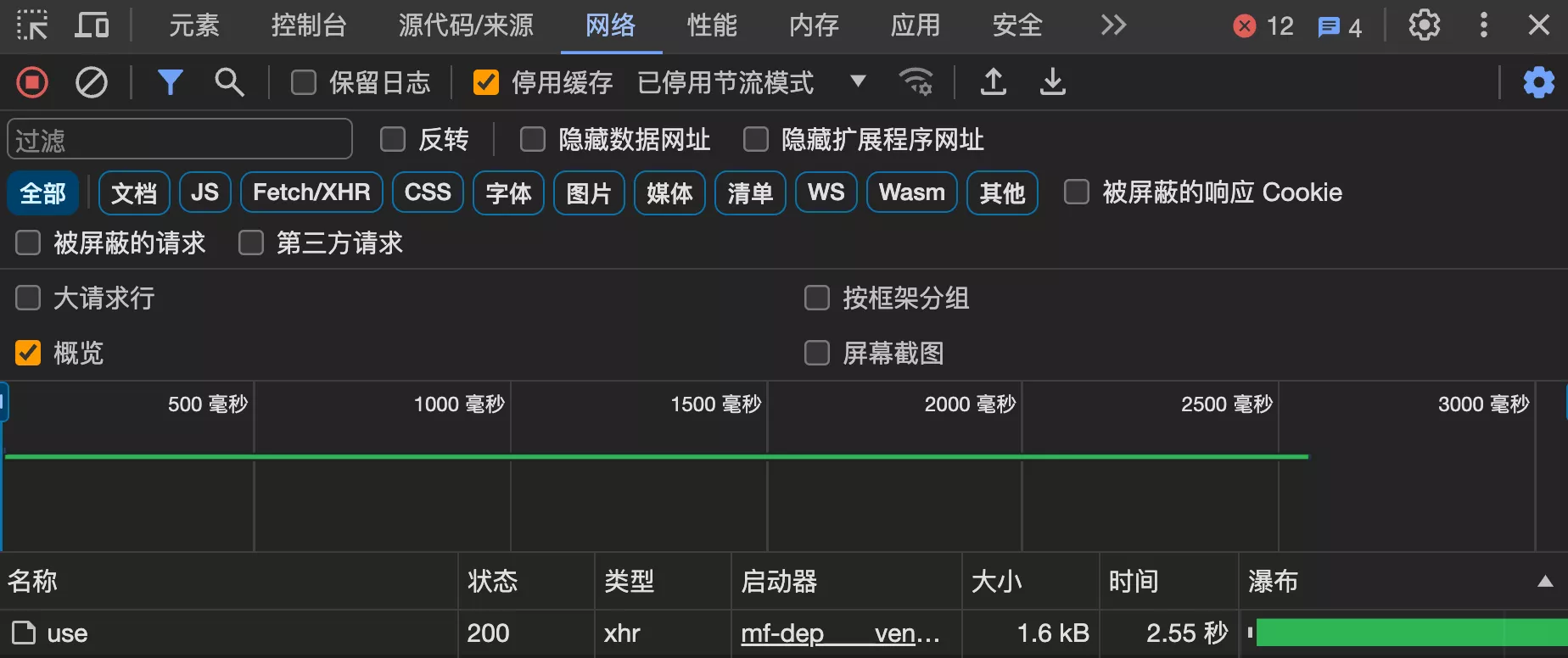
2. 分析代码耗时
@PostMapping("/use")
public void useGenerator(@RequestBody GeneratorUseRequest generatorUseRequest, HttpServletRequest request, HttpServletResponse response) throws IOException {
// 1)用户在前端输入模型参数
Long id = generatorUseRequest.getId();
Map<String, Object> dataModel = generatorUseRequest.getDataModel();
// 需要登录
User loginUser = userService.getLoginUser(request);
Generator generator = generatorService.getById(id);
if (generator == null) {
throw new BusinessException(ErrorCode.NOT_FOUND_ERROR);
}
// 2)从对象存储上下载生成器压缩包,到一个独立的工作空间
String distPath = generator.getDistPath();
if (StrUtil.isBlank(distPath)) {
throw new BusinessException(ErrorCode.NOT_FOUND_ERROR, "产物包不存在");
}
// 工作空间
String projectPath = System.getProperty("user.dir");
String tempDirPath = String.format("%s/.temp/use/%s", projectPath, id);
String zipFilePath = tempDirPath + "/dist.zip";
// 新建文件
if (!FileUtil.exist(zipFilePath)) {
FileUtil.touch(zipFilePath);
}
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 下载文件
try {
cosManager.download(distPath, zipFilePath);
} catch (InterruptedException e) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成器下载失败");
}
stopWatch.stop();
System.out.println("下载:" + stopWatch.getTotalTimeMillis());
// 3)解压,得到生成器
stopWatch = new StopWatch();
stopWatch.start();
File unzipDistDir = ZipUtil.unzip(zipFilePath);
stopWatch.stop();
System.out.println("解压:" + stopWatch.getTotalTimeMillis());
// 4)将用户输入的参数写入到 json 文件中
stopWatch = new StopWatch();
stopWatch.start();
String dataModelFilePath = tempDirPath + "/dataModel.json";
String jsonStr = JSONUtil.toJsonStr(dataModel);
FileUtil.writeUtf8String(jsonStr, dataModelFilePath);
stopWatch.stop();
System.out.println("写数据文件:" + stopWatch.getTotalTimeMillis());
// 5)执行脚本,构造脚本调用命令,传入模型参数 json 文件路径,调用脚本并生成代码
// 找到脚本文件所在路径
File scriptFile = FileUtil.loopFiles(unzipDistDir, 2, null).stream()
.filter(file -> file.isFile() && "generator".equals(file.getName()))
.findFirst()
.orElseThrow(RuntimeException::new);
// 添加可执行权限
try {
Set<PosixFilePermission> permissions = PosixFilePermissions.fromString("rwxrwxrwx");
Files.setPosixFilePermissions(scriptFile.toPath(), permissions);
} catch (Exception e) {
}
// 构造命令
File scriptDir = scriptFile.getParentFile();
String[] commands = new String[]{"./generator", "json-generate", "--file=" + dataModelFilePath};
ProcessBuilder processBuilder = new ProcessBuilder(commands);
processBuilder.directory(scriptDir);
try {
stopWatch = new StopWatch();
stopWatch.start();
Process process = processBuilder.start();
// 读取命令的输出
InputStream inputStream = process.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
// 等待命令执行完成
int exitCode = process.waitFor();
System.out.println("命令执行结束,退出码:" + exitCode);
stopWatch.stop();
System.out.println("执行脚本:" + stopWatch.getTotalTimeMillis());
} catch (Exception e) {
e.printStackTrace();
}
// 6)返回生成的代码结果压缩包
// 生成代码的位置
stopWatch = new StopWatch();
stopWatch.start();
String generatedPath = scriptDir.getAbsolutePath() + "/generated";
String resultPath = tempDirPath + "/result.zip";
File resultFile = ZipUtil.zip(generatedPath, resultPath);
stopWatch.stop();
System.out.println("压缩结果:" + stopWatch.getTotalTimeMillis());
// 下载文件
// 设置响应头
response.setContentType("application/octet-stream;charset=UTF-8");
response.setHeader("Content-Disposition", "attachment; filename=" + resultFile.getName());
// 写入响应
Files.copy(resultFile.toPath(), response.getOutputStream());
// 7)清理文件
CompletableFuture.runAsync(() -> {
FileUtil.del(tempDirPath);
});
}:


3. 优化策略
发现下载、执行脚本、解压都是耗时操作
- 生成器脚本是由 maker 制作工具提前生成好的,执行脚本的操作优化可能比较困难
- 重点优化:下载和解压操作。对于频繁使用的生成器,反复下载文件、解压文件是没必要的,可以使用缓存
3. 制作生成器接口
1. 整体测试
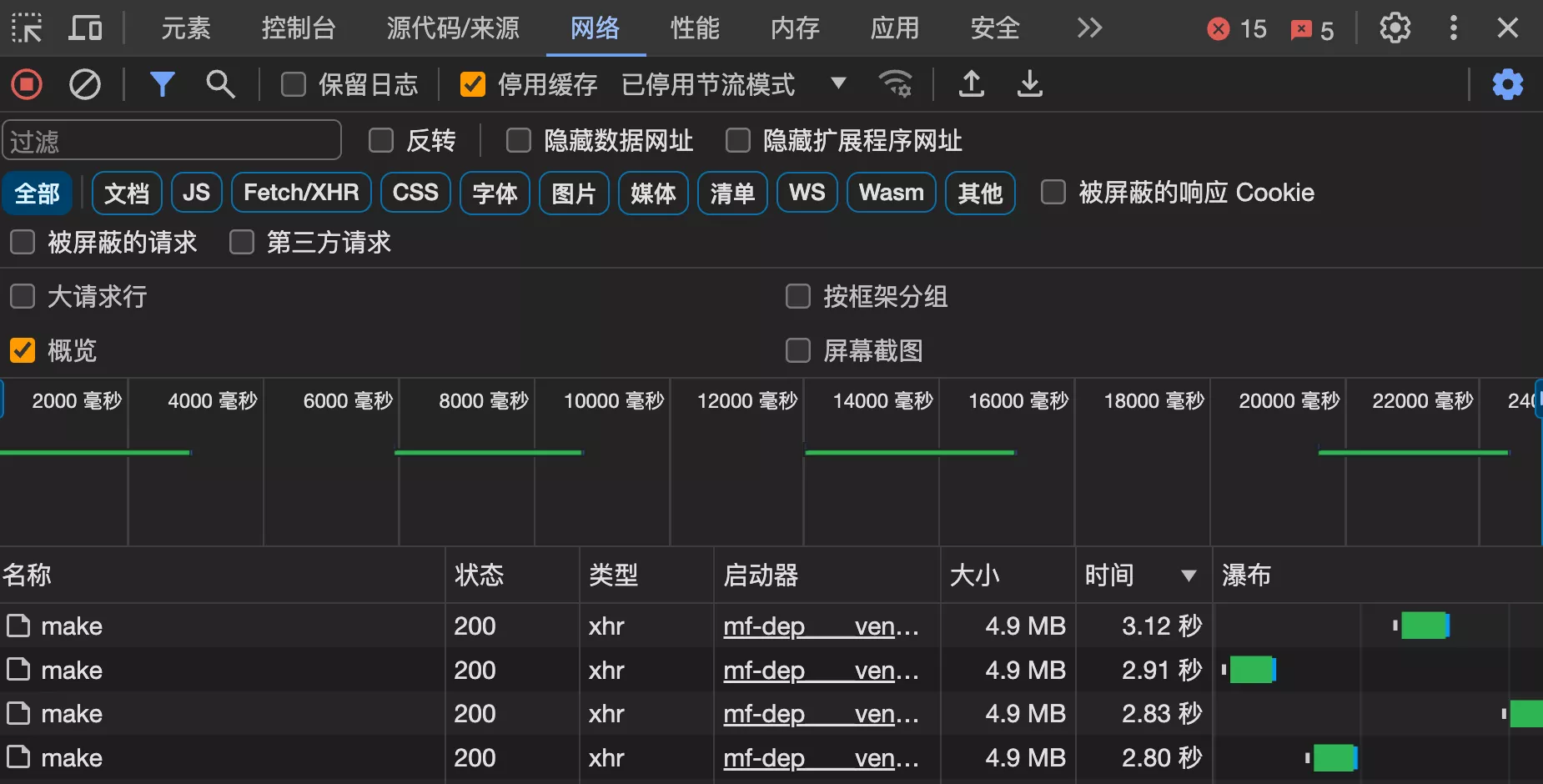
2. 分析代码耗时
try {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
cosManager.download(zipFilePath, localZipFilePath);
stopWatch.stop();
System.out.println("下载文件:" + stopWatch.getTotalTimeMillis());
} catch (InterruptedException e) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "压缩包下载失败");
}
// 3)解压,得到项目模板文件
File unzipDistDir = ZipUtil.unzip(localZipFilePath);
// 4)构造 meta 对象和输出路径
String sourceRootPath = unzipDistDir.getAbsolutePath();
meta.getFileConfig().setSourceRootPath(sourceRootPath);
MetaValidator.doValidAndFill(meta);
String outputPath = String.format("%s/generated/%s", tempDirPath, meta.getName());
// 5)调用 maker 方法制作生成器
GenerateTemplate generateTemplate = new ZipGenerator();
try {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
generateTemplate.doGenerate(meta, outputPath);
stopWatch.stop();
System.out.println("制作:" + stopWatch.getTotalTimeMillis());
} catch (Exception e) {
e.printStackTrace();
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "制作失败");
}

3. 优化策略
耗时操作是下载和制作
- 先让用户将模板文件上传到对象存储、再从对象存储下载的过程其实是没必要的。因为平台现在仅支持单次制作
- 制作操作耗时,由于调用了 maker 项目、使用 Maven 进行打包,优化的成本较大,暂不考虑
- 如果制作耗时超过 20 秒,可以考虑使用 异步化 ,将生成器制作封装为一个任务,用户可以通过前端页面自主查询任务的执行状态并下载制作结果
3. 查询性能优化
以下几个场景:
- 数据需要高频访问。优化主页调用的 分页查询生成器接口
- 数据量较大,查询缓慢
- 数据查询实时性要求高,追求用户体验
1. 精简数据
1. 整体测试
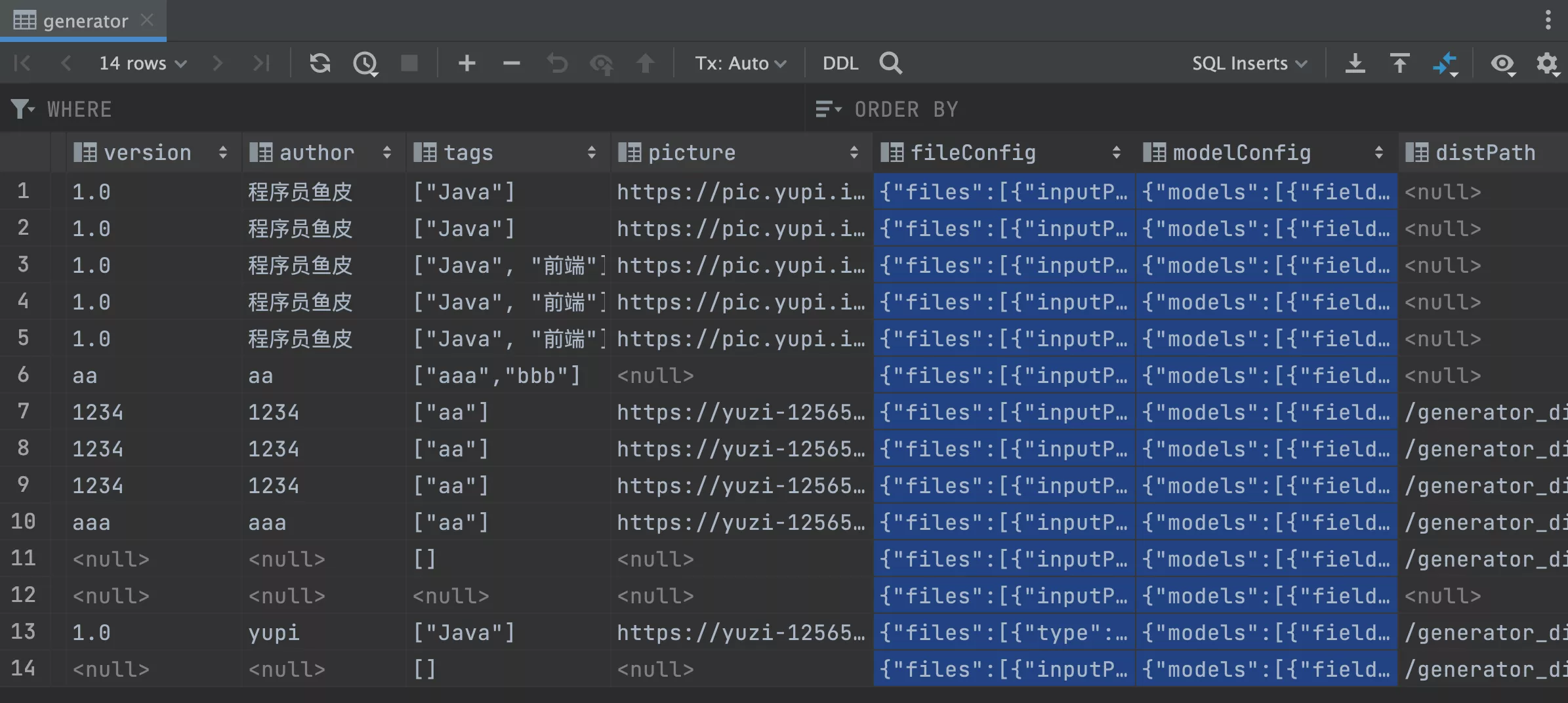
保证首页 12 条数据都是完整的,尤其是都要有 fileConfig 和 modelConfig 字段
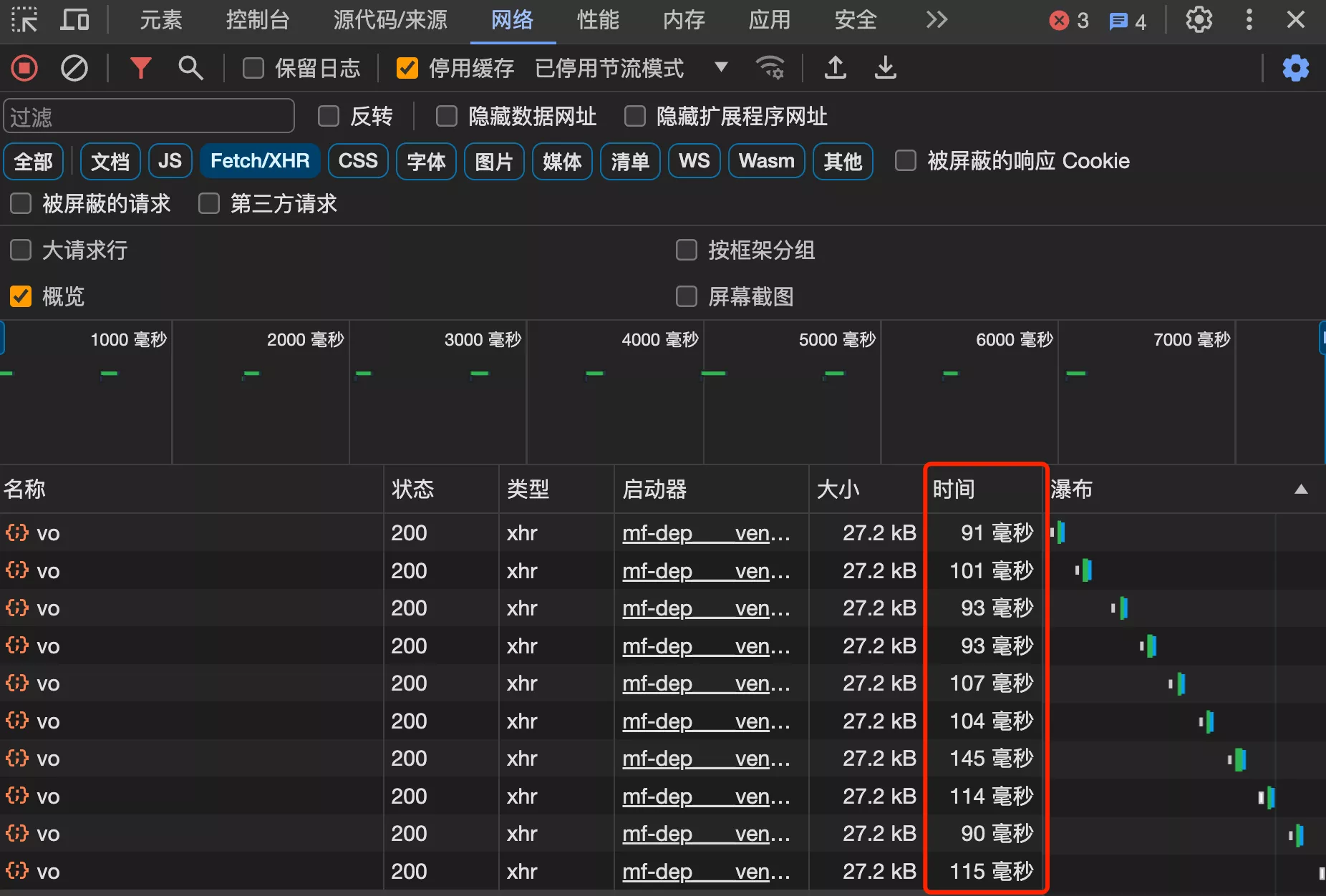
多测试几次查看平均值,查询 10 次的耗时,平均 100 毫秒左右
2. 分析代码耗时
/**
* 分页获取列表(封装类)
*
* @param generatorQueryRequest
* @param request
* @return
*/
@PostMapping("/list/page/vo")
public BaseResponse<Page<GeneratorVO>> listGeneratorVOByPage(@RequestBody GeneratorQueryRequest generatorQueryRequest,
HttpServletRequest request) {
long current = generatorQueryRequest.getCurrent();
long size = generatorQueryRequest.getPageSize();
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Page<Generator> generatorPage = generatorService.page(new Page<>(current, size),
generatorService.getQueryWrapper(generatorQueryRequest));
stopWatch.stop();
System.out.println("查询生成器:" + stopWatch.getTotalTimeMillis());
stopWatch = new StopWatch();
stopWatch.start();
Page<GeneratorVO> generatorVOPage = generatorService.getGeneratorVOPage(generatorPage, request);
stopWatch.stop();
System.out.println("查询关联数据:" + stopWatch.getTotalTimeMillis());
return ResultUtils.success(generatorVOPage);
}
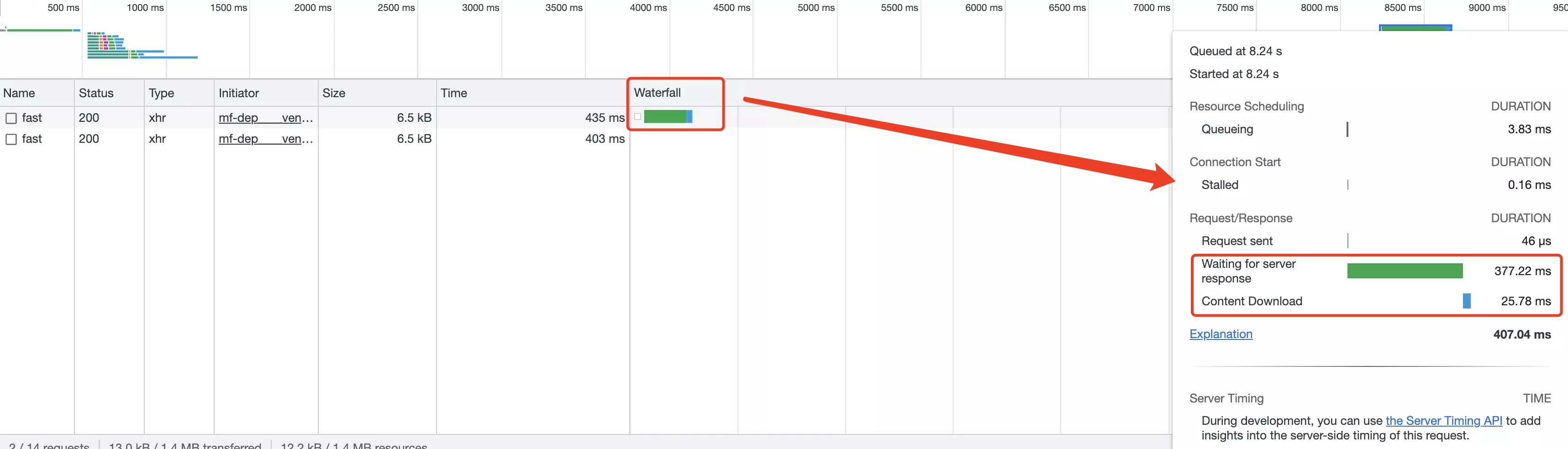
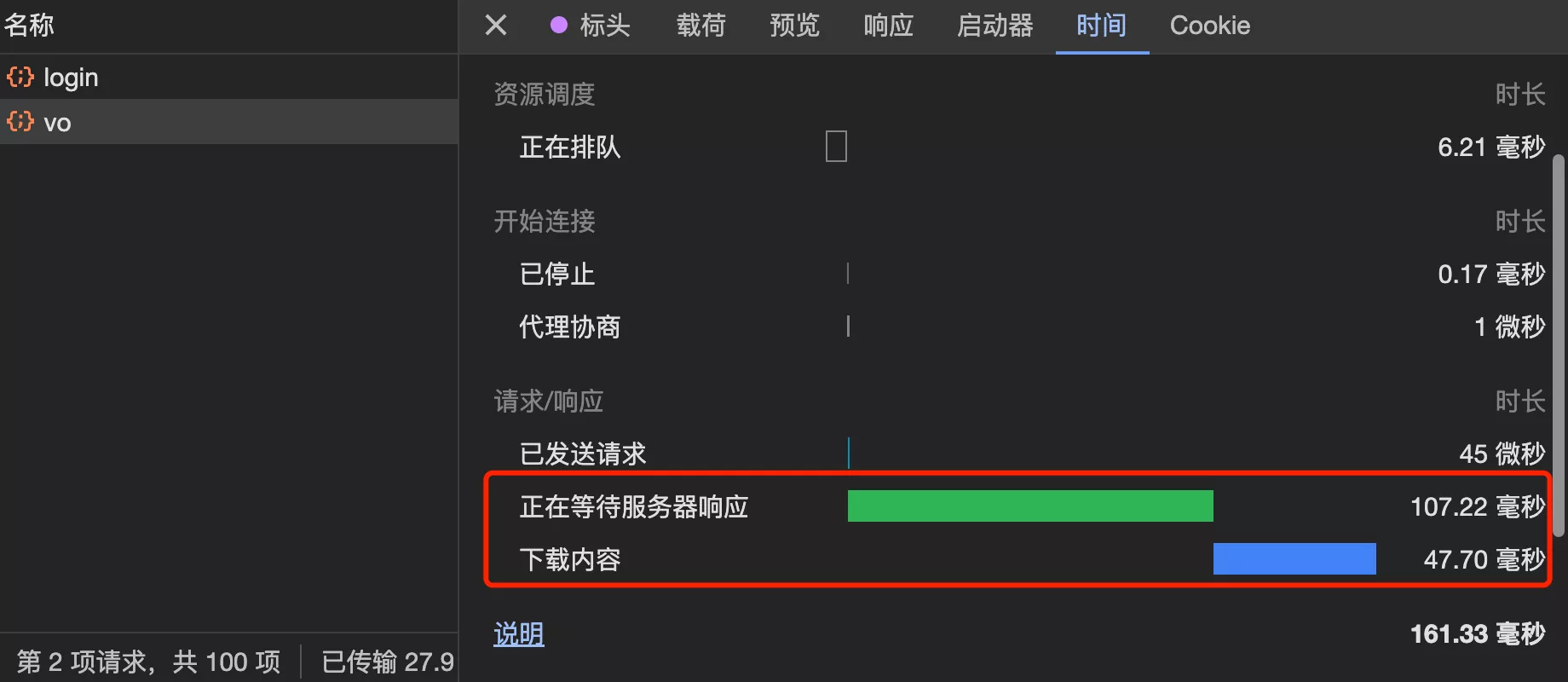
经过多次测试,数据库查询操作的总耗时接近 100 毫秒,为什么整个接口的响应需要 150 毫秒呢?

原因:服务器查询到数据后,需要传输数据给前端,存在一个下载耗时。在网页控制台中查看请求消耗的时间,发现前端下载内容花费了额外的时间
3. 优化
- 减少后端返回的数据体积,可以减少返回的数据、或者压缩数据
- 提高服务器的带宽
/**
* 快速分页获取列表(封装类)
*
* @param generatorQueryRequest
* @param request
* @return
*/
@PostMapping("/list/page/vo/fast")
public BaseResponse<Page<GeneratorVO>> listGeneratorVOByPageFast(@RequestBody GeneratorQueryRequest generatorQueryRequest,
HttpServletRequest request) {
long current = generatorQueryRequest.getCurrent();
long size = generatorQueryRequest.getPageSize();
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
Page<Generator> generatorPage = generatorService.page(new Page<>(current, size),
generatorService.getQueryWrapper(generatorQueryRequest));
Page<GeneratorVO> generatorVOPage = generatorService.getGeneratorVOPage(generatorPage, request);
generatorVOPage.getRecords().forEach(generatorVO -> {
generatorVO.setFileConfig(null);
generatorVO.setModelConfig(null);
});
return ResultUtils.success(generatorVOPage);
}
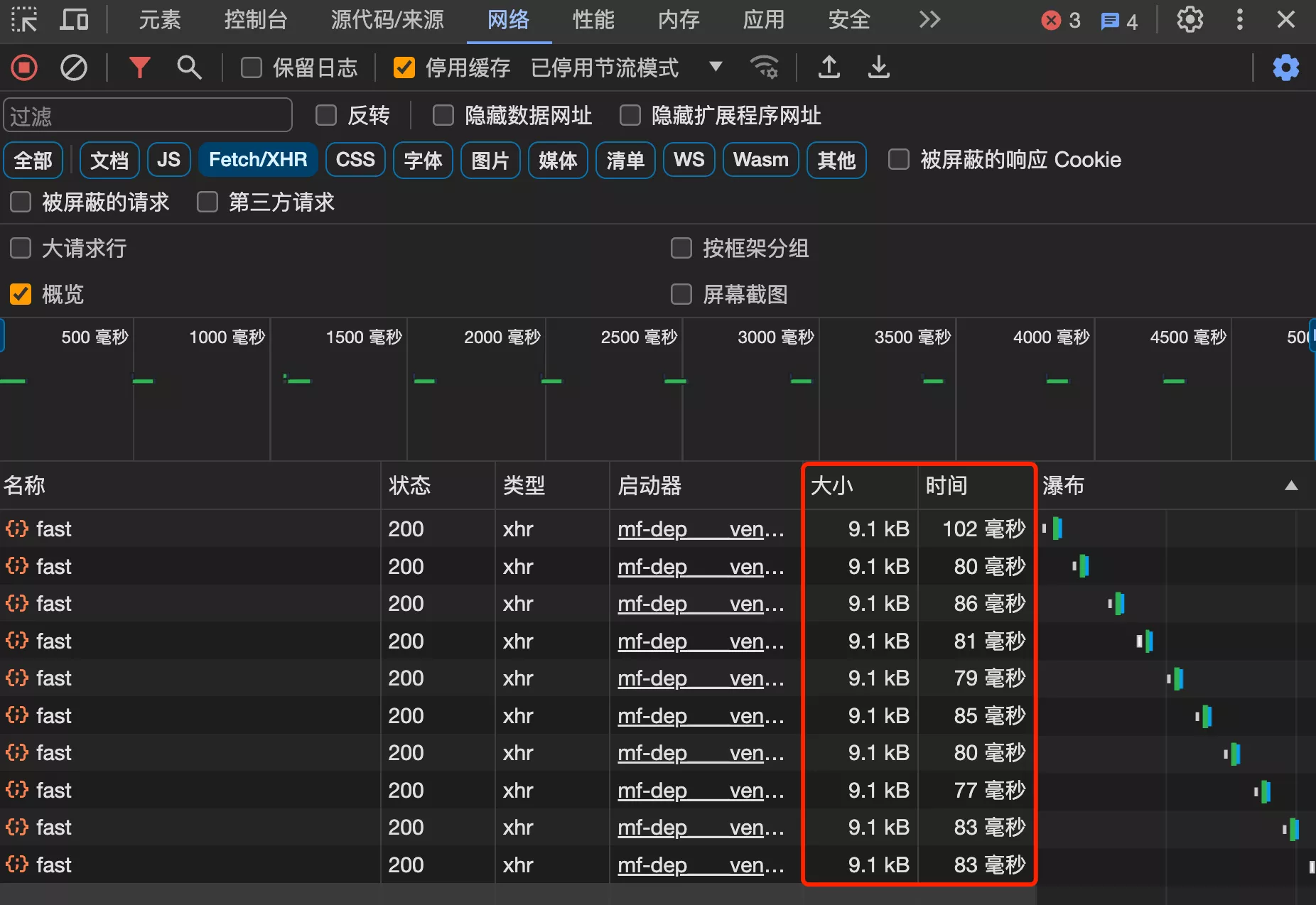
4. 测试
接口平均响应时长减少了 15%。
2. SQL 优化
向数据库插入 10 万条示例数据(ACM 示例模板生成器),模拟真实的系统用量
package com.yupi.web.service;
import com.yupi.web.model.entity.Generator;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
class GeneratorServiceTest {
@Resource
private GeneratorService generatorService;
@Test
public void testInsert() {
Generator generator = generatorService.getById(18L);
for (int i = 0; i < 100_000; i++) {
generator.setId(null);
generatorService.save(generator);
}
}
}
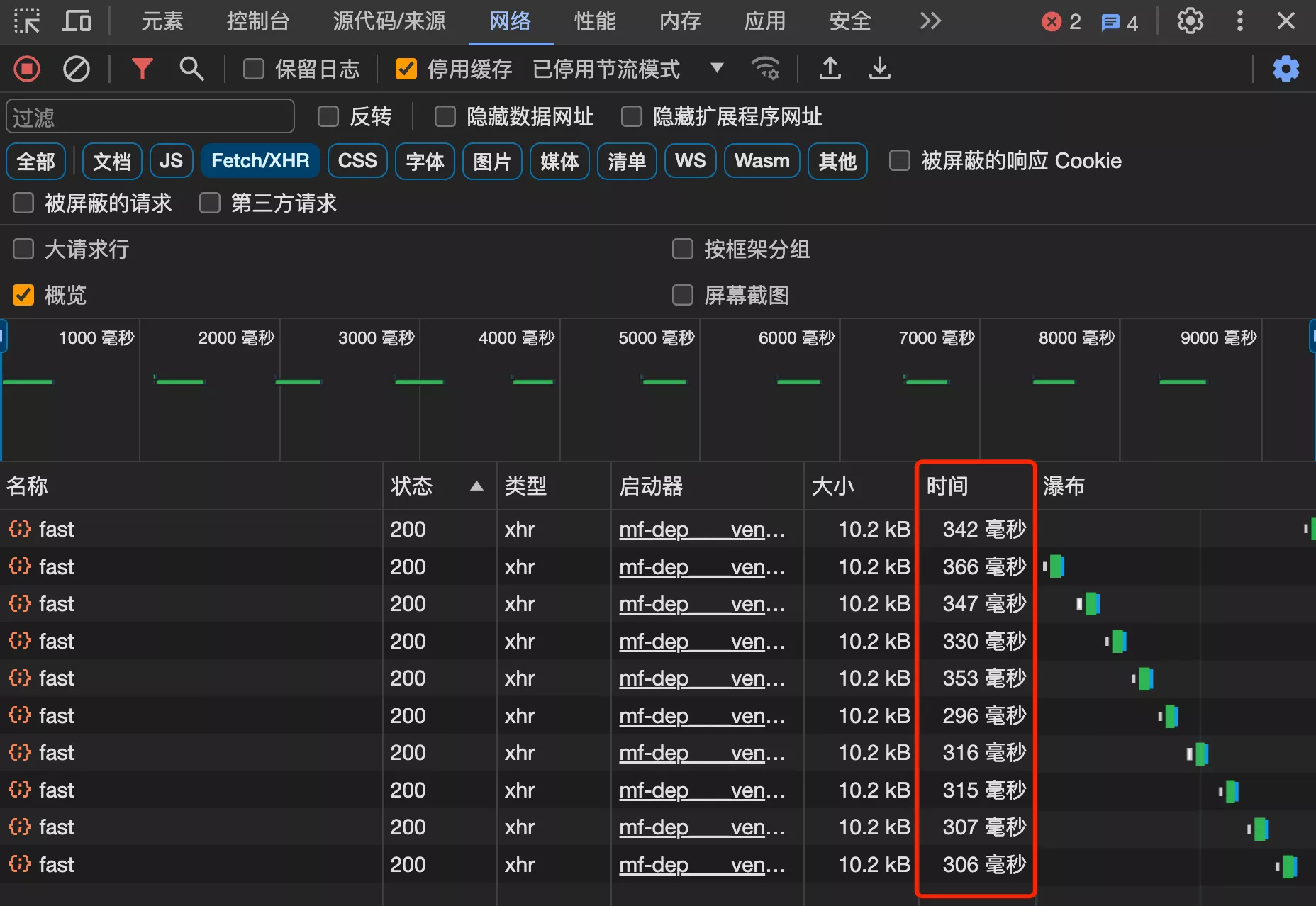
1. 整体测试
插入大量数据后,性能大幅降低,接口平均响应时长耗时 300 多毫秒
2. 分析耗时
由于数据量增大导致查询性能降低,数据库查询数据的耗时增大了
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
SELECT id,name,description,basePackage,version,author,tags,picture,fileConfig,modelConfig,distPath,status,userId,createTime,updateTime,isDelete FROM generator WHERE isDelete=0 ORDER BY createTime DESC LIMIT 12;
执行总耗时 1171 毫秒
3. 优化
- 减少查询次数,能不查数据库就不查数据库,比如使用缓存
- 优化 SQL 语句
- 添加合适的索引
不查询 fileConfig 和 modelConfig 字段,执行 10 次的总耗时 1020 毫秒,减少 10% 左右

只查询需要的字段
QueryWrapper<Generator> queryWrapper = generatorService.getQueryWrapper(generatorQueryRequest);
queryWrapper.select("id","name","description","tags","picture","status","userId","createTime","updateTime");
Page<Generator> generatorPage = generatorService.page(new Page<>(current, size), queryWrapper);
Page<GeneratorVO> generatorVOPage = generatorService.getGeneratorVOPage(generatorPage, request);
return ResultUtils.success(generatorVOPage);
4. 测试
接口的平均响应时间优化到了 200 多毫秒,减少了 1/3
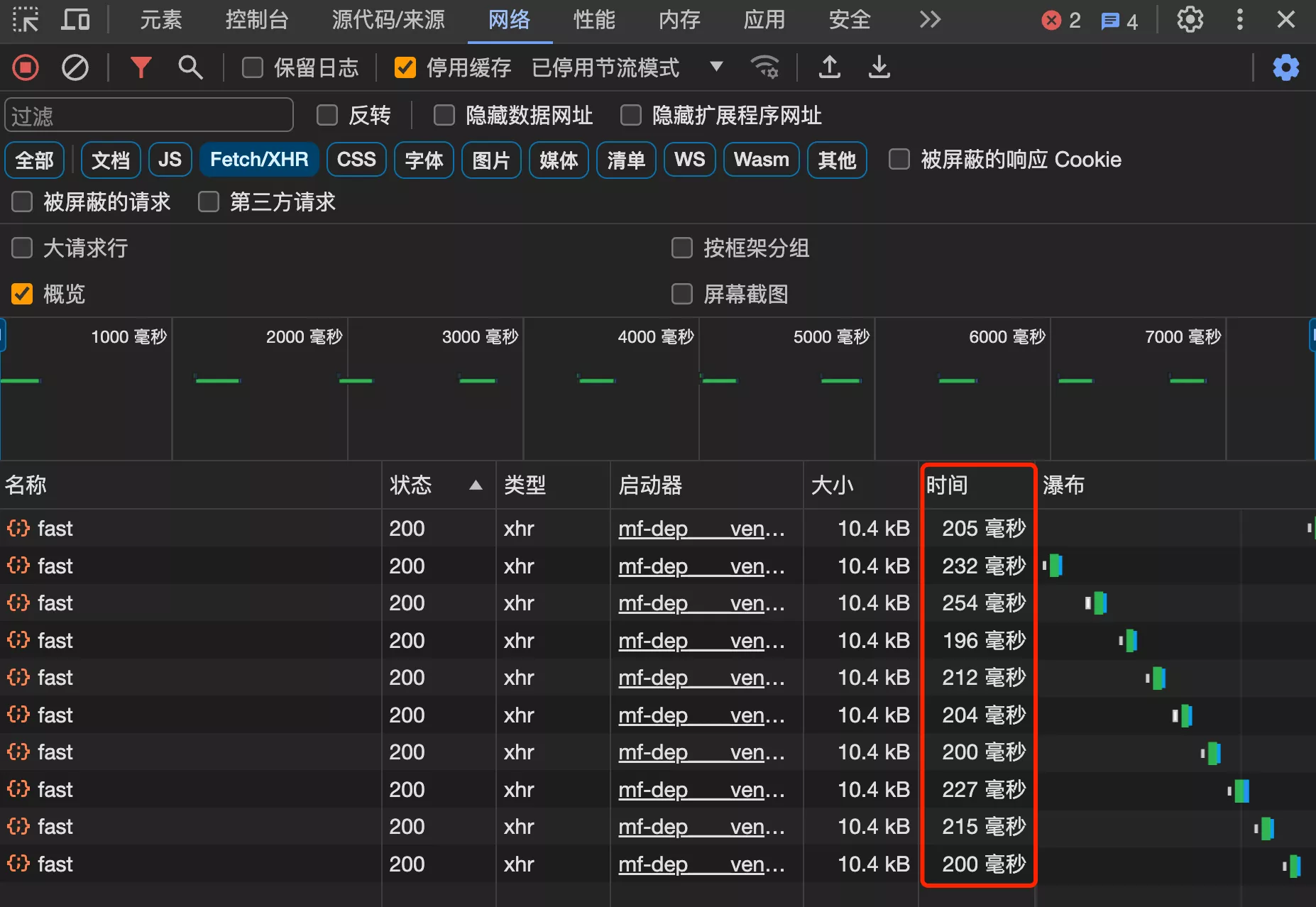
扩展:分页查询接口中,还有一个耗时的操作 —— 使用 count 语句统计总数,是否可以优化呢?
- 一般来说,单次查询时间超过 100ms、500ms 或者 1s 算是慢查询
3. 压力测试
主流的压力测试工具 Apache JMeter,演示模拟高并发场景来测试接口
0. 明确测试情况
首先,一定要明确测试的环境、条件和基准。
举个例子,谷牛本次的测试情况:
- 环境:使用 16 G 内存、10 核 CPU、百兆带宽的网速
- 条件:每次请求相同的接口、传递相同的参数
- 基准:始终保证接口异常率 0%,出现异常则需要重新测试
注意,压测前保证不会影响系统的正常运行,千万不要在线上压测!
线上压测 ≈ 造事故 ≈ 攻击
1. 下载 JMeter
- 官网下载 Apache JMeter
- 下载后解压,然后执行 bin 目录下的 jar 包即可
2. 压测配置
- 根据实际测试结果动态调整线程组,直到找到一个每次测试结果相对稳定的设置,从而消除线程组启动或者电脑配置不足导致的误差
- 注意:每秒启动的线程数要大于接口的 qps(每秒请求数),才能测试到极限,不能因为请求速度不够影响测试结果
- 统一性能测试标准:
- 线程数:1000 个 / 组
- 启动时长:10 秒
- 循环次数:10 组
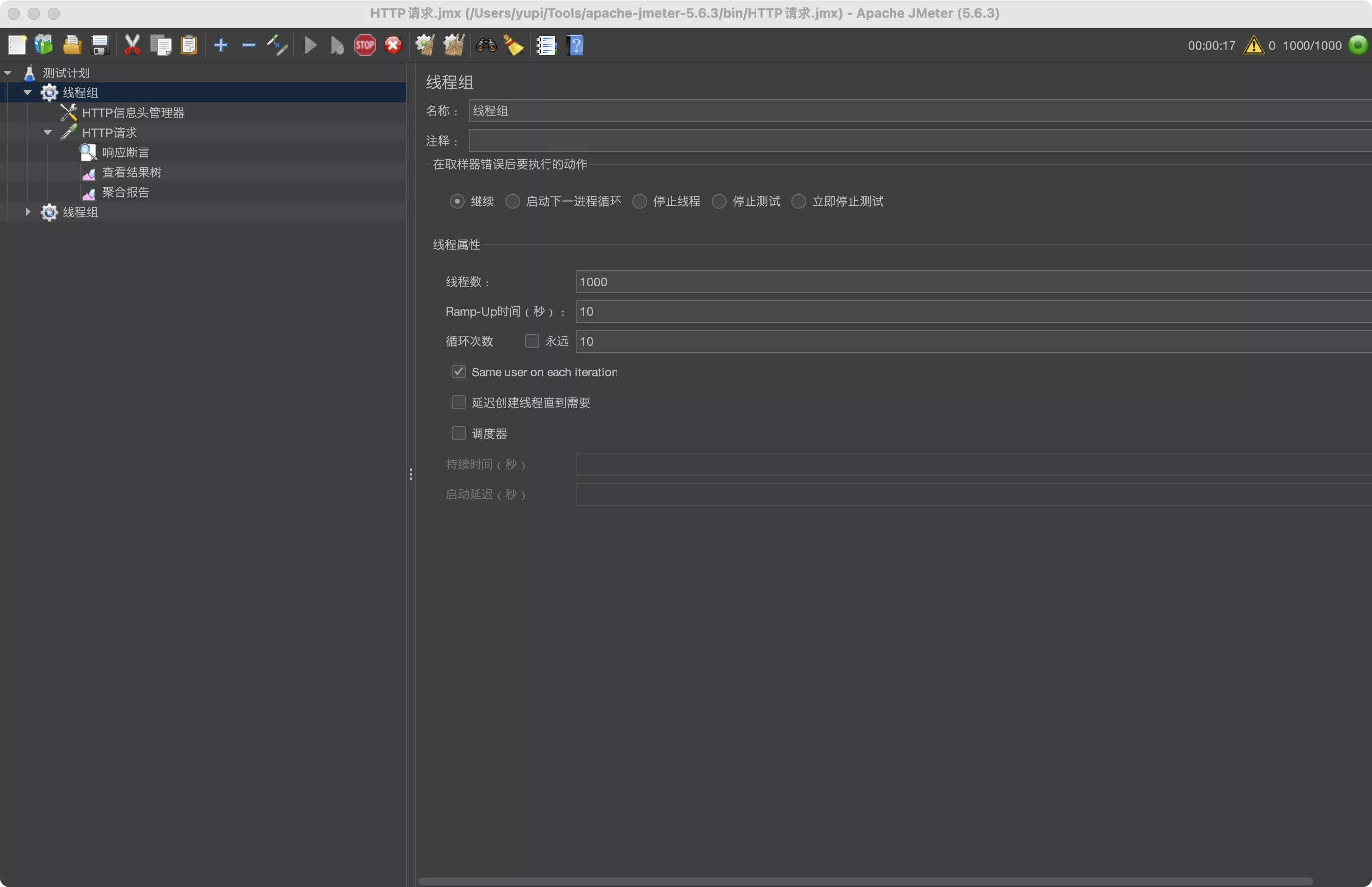
- 创建线程组
- 主要是填写《线程数》、《启动时间》、《循环次数》这 3 个值
- 线程数 * 循环次数 = 要测试的请求总数
- 启动时间的作用是控制线程的启动速率,从而控制请求速率。eg:10 秒启动 100 个线程,那么每秒启动 10 个线程,相当于最开始每秒会发 10 个请求
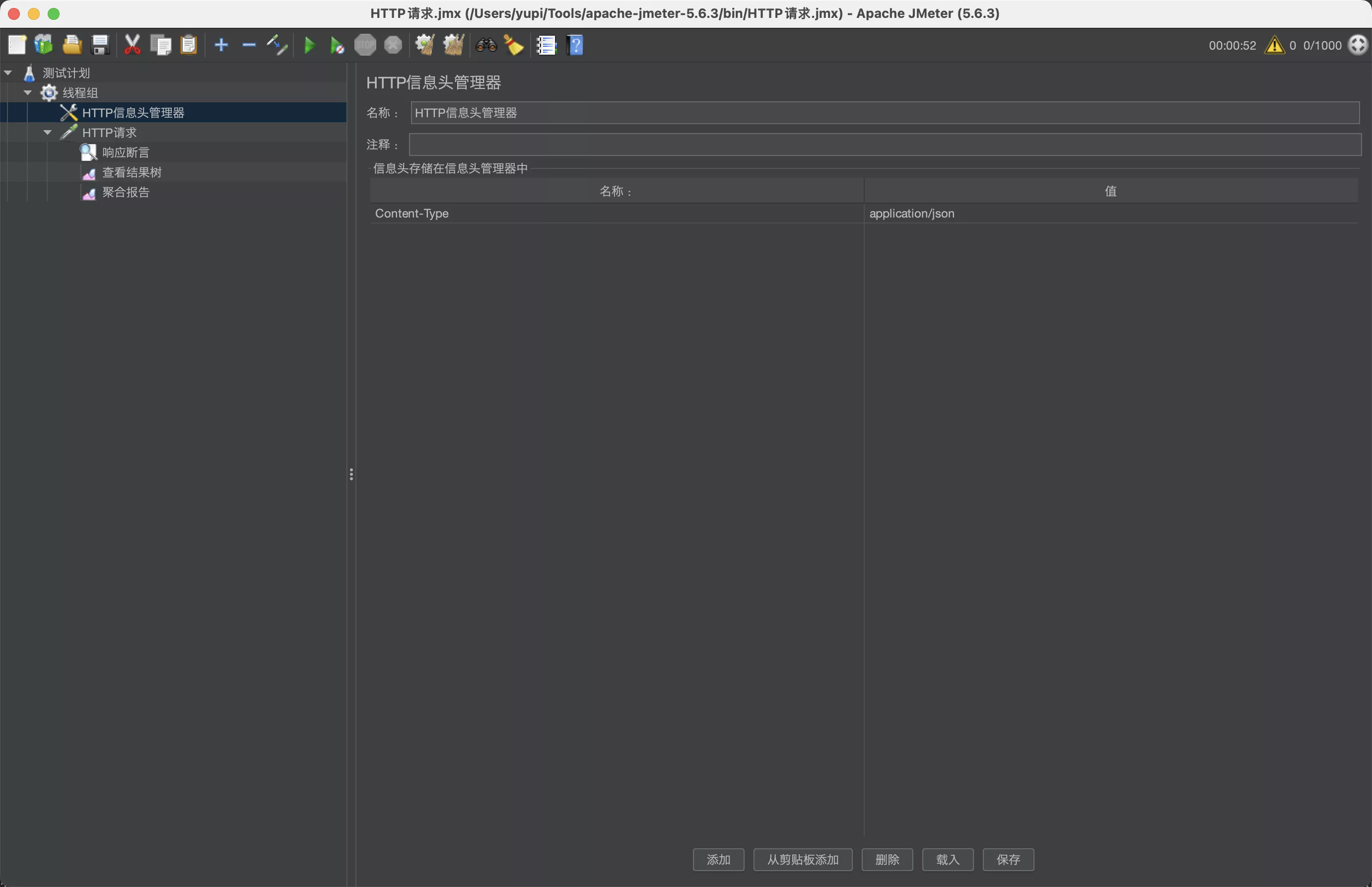
- 创建 HTTP 信息头管理
- 设置请求
Content-Type为application/json,和要测试的接口保持一致
- 设置请求
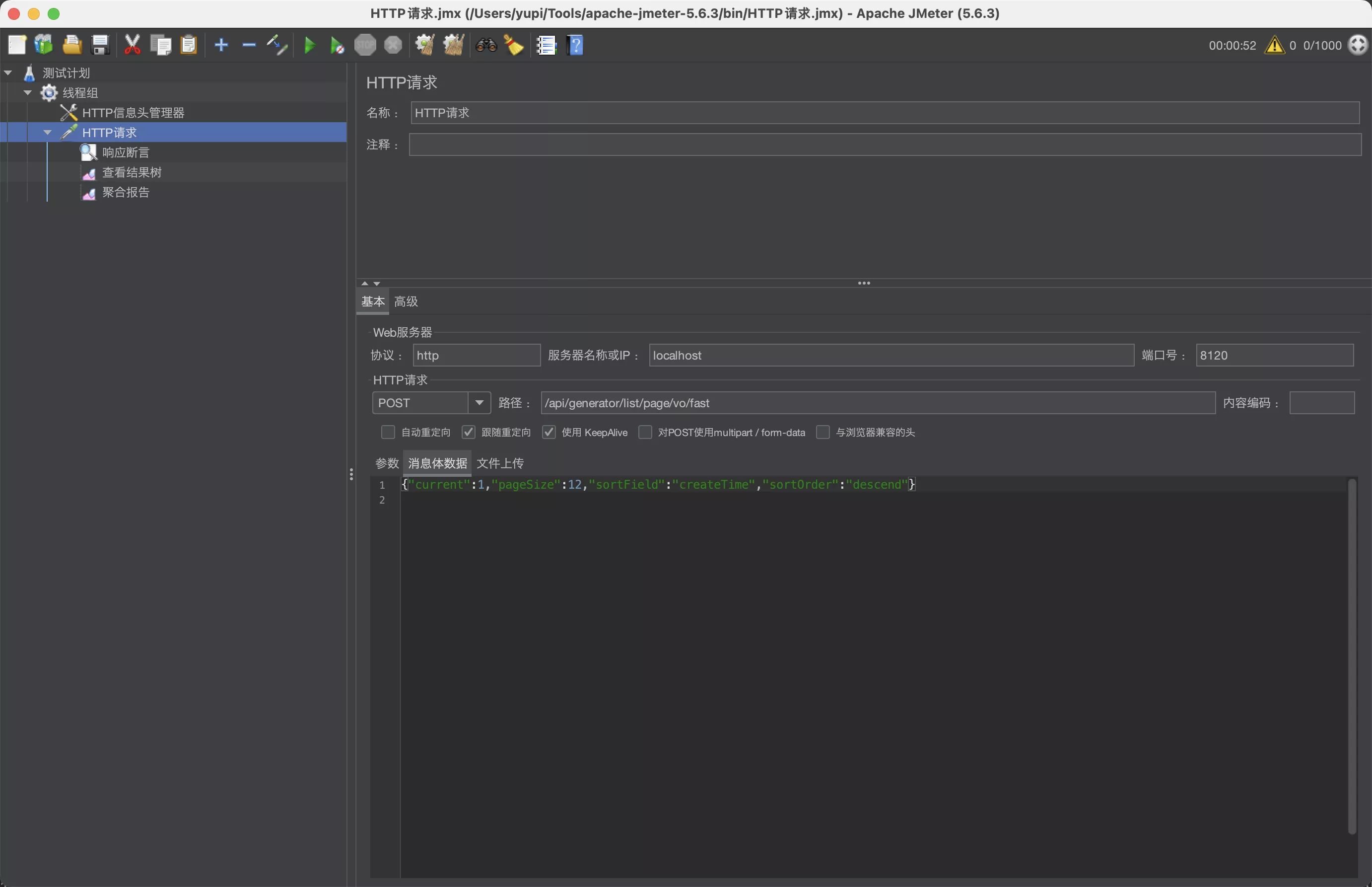
- 新建 HTTP 请求
- 填写要测试的接口路径、请求类型、请求参数等
- 请求参数跟前端进入主页时发送的请求保持一致
{"current":1,"pageSize":12,"sortField":"createTime","sortOrder":"descend"}
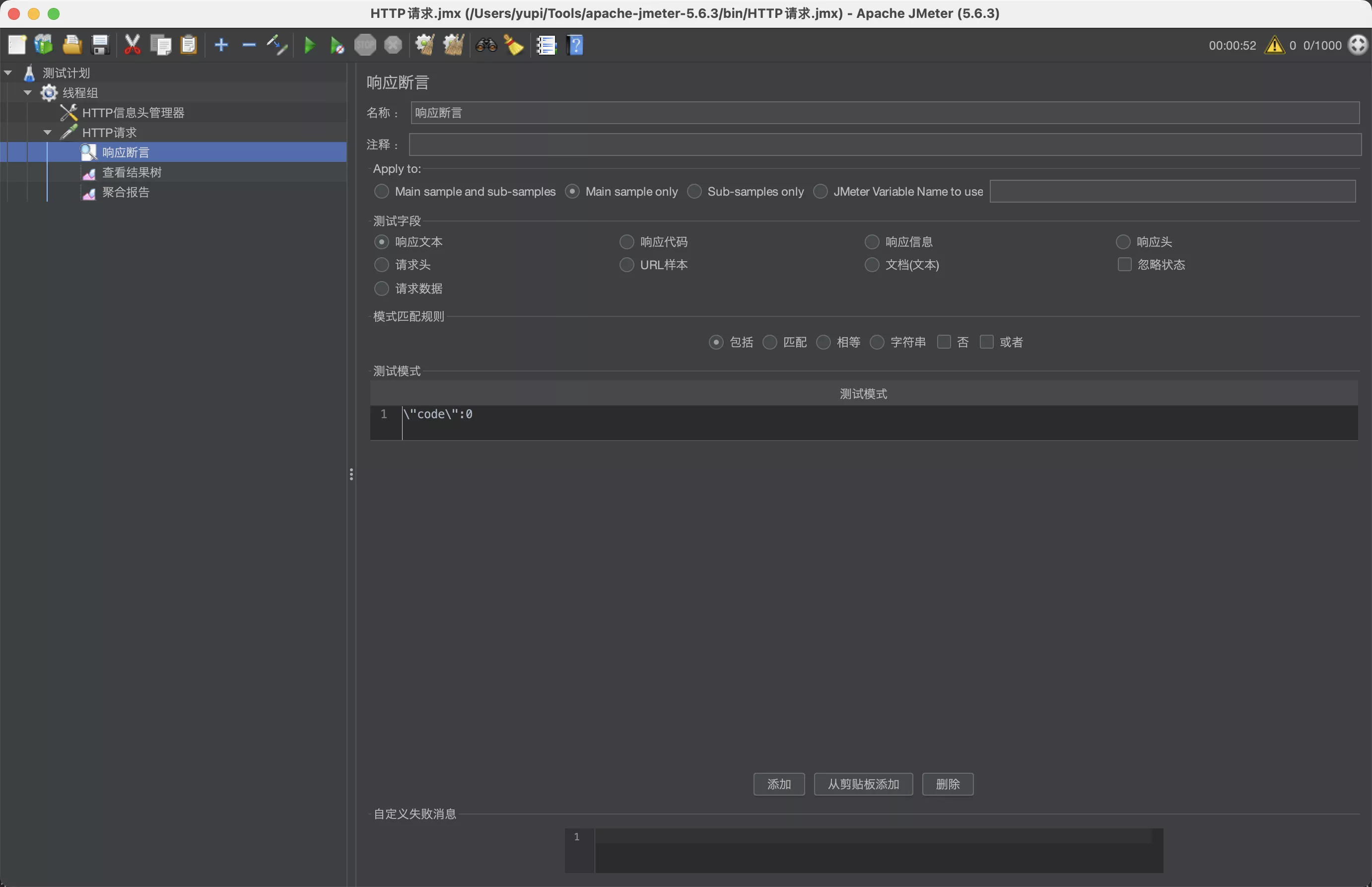
- 创建响应断言
- 作用:判断接口是否正常响应
- 定义的正常响应规则是:响应文本要包含
\"code\":0,否则为异常情况
- 配置压测结果展示
- 添加查看《结果树》《聚合报告》
3. 压测执行
- 做好配置后,右键线程组,点击启动,等待执行即可
- 执行过程中,软件可能会卡顿,因为压测是非常耗费系统资源的
- 执行完成后,查看结果树,能够查看到每次请求的响应结果:
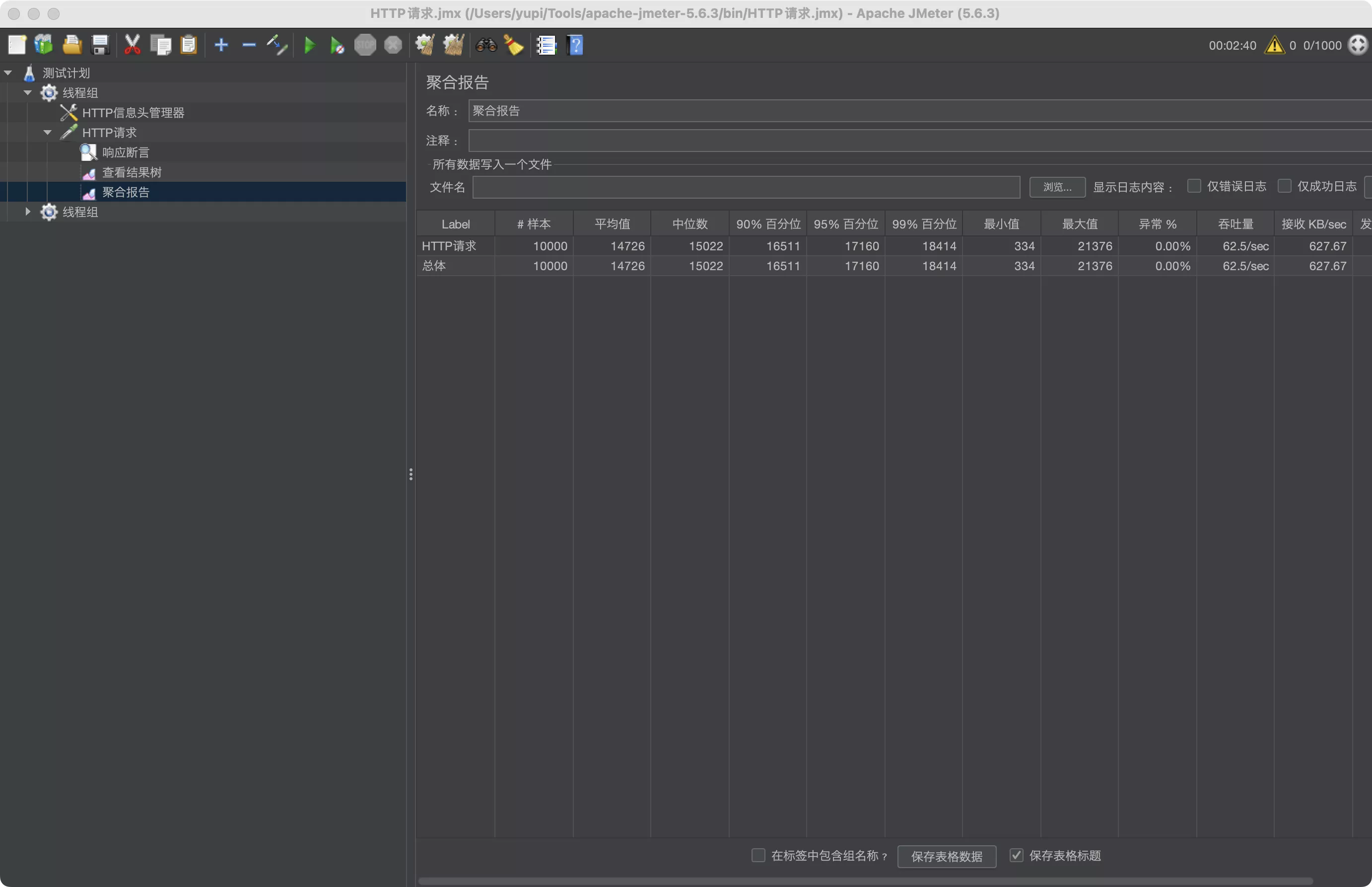
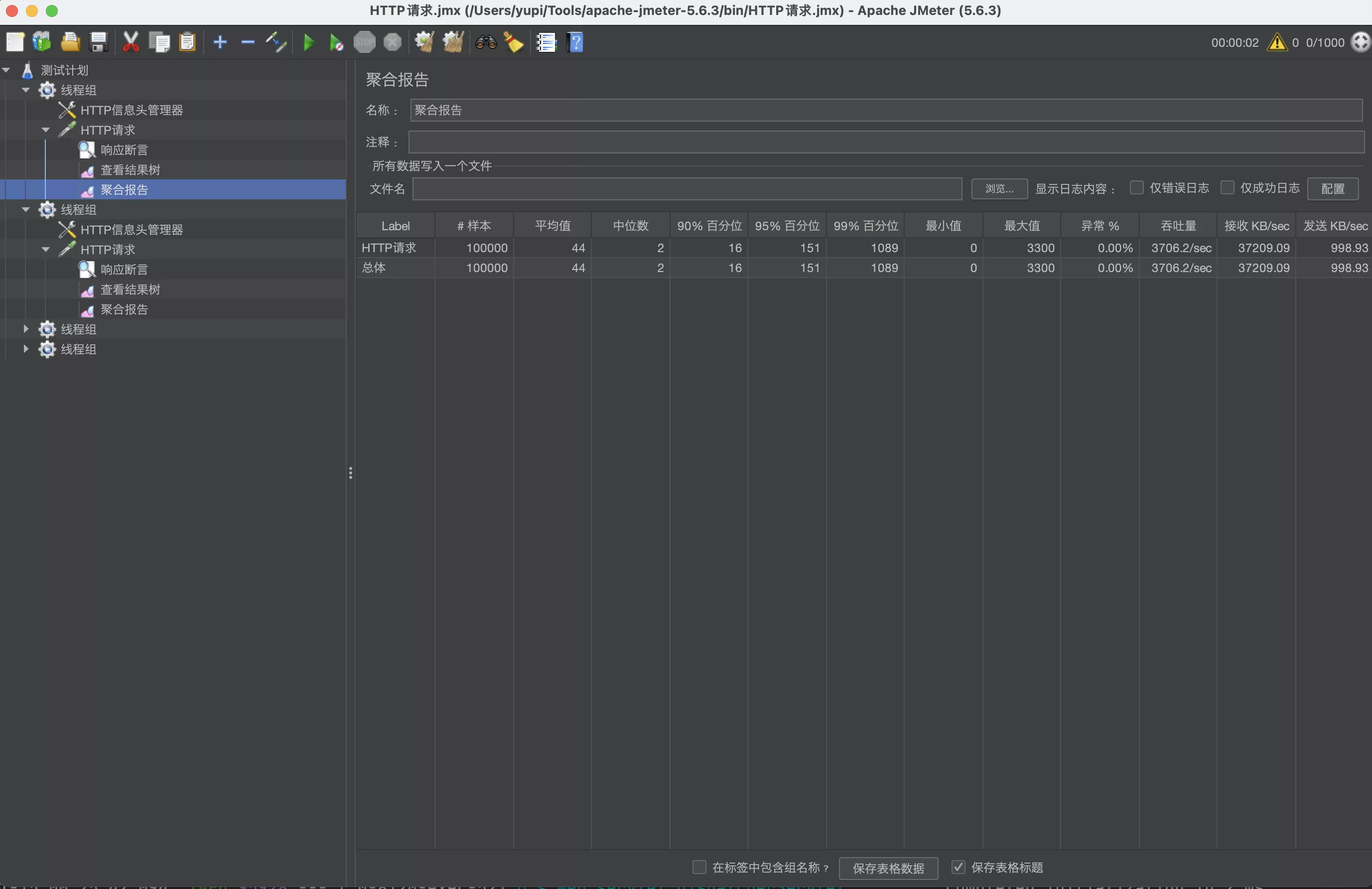
- 查看聚合报告,这里有最需要的数据
- 压测发现,1000 个线程、10 组、10 秒启动、保证 0 异常的前提下,qps(也就是结果中的吞吐量)为 62.5 / 秒 。而且因为后端处理能力跟不上请求速度,很多请求需要排队等待十几秒,甚至最大值要等 20 多秒,才能得到响应
1. qps 和 tps 的区别
- QPS(Queries Per Second)每秒查询数。 主要用于衡量系统的查询性能。通常在数据库、搜索引擎等场景中使用。每一个查询可以是数据库查询、HTTP请求、网络请求等
- TPS(Transactions Per Second)每秒事务数。主要用于衡量系统的事务处理能力。通常在交易、支付、订单处理等涉及多个步骤的场景中使用。每一个事务可以包括多个操作步骤
在实际应用中,这两个指标的选择取决于系统的特性和关注点。如果系统主要是处理查询请求,那么 QPS 更合适;如果系统主要是进行复杂的事务处理,那么 TPS 更合适
4. 分布式缓存
提升数据的查询性能,最有效的办法之一就是 缓存
- 缓存尤其适用于 读多写少,可以最大程度利用缓存、并且减少数据不一致的风险
- 生成器的修改频率一般是很低的,而且实际运营时,生成器应该是需要人工审核才能展示到主页
- 使用主流的、基于内存的分布式缓存 Redis,来存储生成器分页数据,其读写性能远超 MySQL
1. Redis 安装和管理
使用 IDEA 内置的可视化工具来管理 Redis
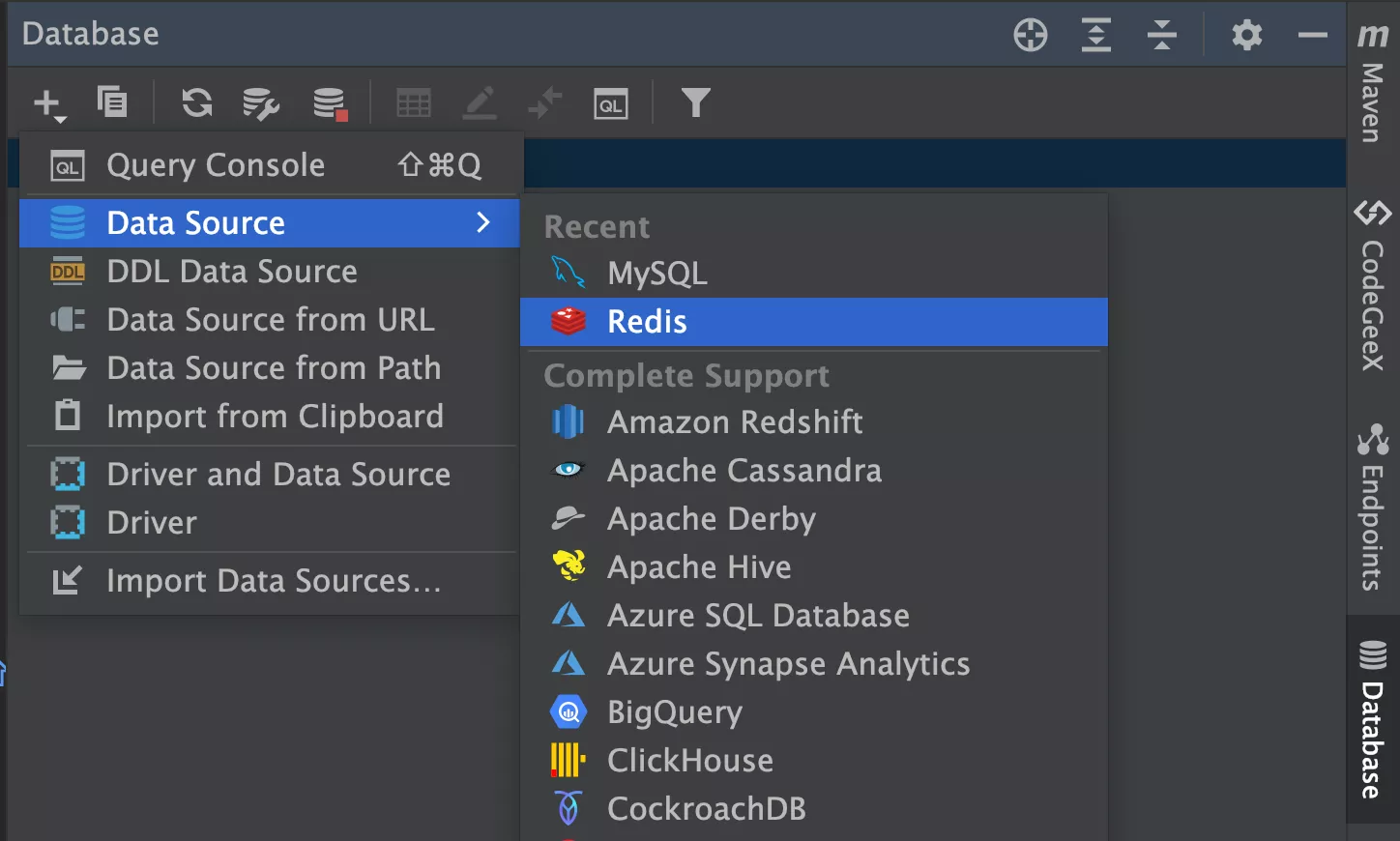
填写 Redis 配置
查看 Redis 内的数据
2. 使用缓存
- 引入 Redis
spring:
# Redis 配置
redis:
database: 1
host: localhost
port: 6379
timeout: 5000
// 取消移除 Redis 的代码
@SpringBootApplication(exclude = {RedisAutoConfiguration.class})
- 缓存 key 设计
- 规则为:
业务前缀:数据分类(接口标识):请求参数 - 业务前缀和数据分类的作用是为了区分不同业务和接口的缓存,防止冲突
- 将请求参数作为 key,就能实现不同的分页查询不同的缓存。需要注意的是,请求参数字符串可能很长,所以选用 base64 进行编码
- 规则为:
/**
* 获取分页缓存 key
*/
private static String getPageCacheKey(GeneratorQueryRequest generatorQueryRequest) {
String jsonStr = JSONUtil.toJsonStr(generatorQueryRequest);
String base64 = Base64Encoder.encode(jsonStr);
String key = "generator:page:" + base64;
return key;
}
- 分页数据缓存内容设计,redis如何缓存分页数据 ?
- 缓存整页数据。不仅开发成本更低、性能也更高,但缺点就是不利于分页中某一条数据的更新
- 先使用 Redis 的 string 数据结构,将分页对象转为 JSON 字符串后写入。相比于 JDK 自带的序列化机制,用 JSON 字符串会使缓存的可读性更好
- 分页的每条数据单独缓存。查询时先获取到 id 集合,再根据 id 集合去批量查询缓存
- 缓存整页数据。不仅开发成本更低、性能也更高,但缺点就是不利于分页中某一条数据的更新
一般情况下,建议按需缓存,只缓存数据高频访问的情况,以提高缓存的利用率(命中率),比如只缓存首页数据的第一页。
- 应用缓存
- 一定要给缓存设置过期时间
/**
* 快速分页获取列表(封装类)
*
* @param generatorQueryRequest
* @param request
* @return
*/
@PostMapping("/list/page/vo/fast")
public BaseResponse<Page<GeneratorVO>> listGeneratorVOByPageFast(@RequestBody GeneratorQueryRequest generatorQueryRequest,
HttpServletRequest request) {
long current = generatorQueryRequest.getCurrent();
long size = generatorQueryRequest.getPageSize();
// 优先从缓存读取
String cacheKey = getPageCacheKey(generatorQueryRequest);
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
String cacheValue = valueOperations.get(cacheKey);
if (StrUtil.isNotBlank(cacheValue)) {
Page<GeneratorVO> generatorVOPage = JSONUtil.toBean(cacheValue,
new TypeReference<Page<GeneratorVO>>() {
},
false);
return ResultUtils.success(generatorVOPage);
}
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
Page<Generator> generatorPage = generatorService.page(new Page<>(current, size),
generatorService.getQueryWrapper(generatorQueryRequest));
Page<GeneratorVO> generatorVOPage = generatorService.getGeneratorVOPage(generatorPage, request);
generatorVOPage.getRecords().forEach(generatorVO -> {
generatorVO.setFileConfig(null);
generatorVO.setModelConfig(null);
});
// 写入缓存
valueOperations.set(cacheKey, JSONUtil.toJsonStr(generatorVOPage), 100, TimeUnit.MINUTES);
return ResultUtils.success(generatorVOPage);
}
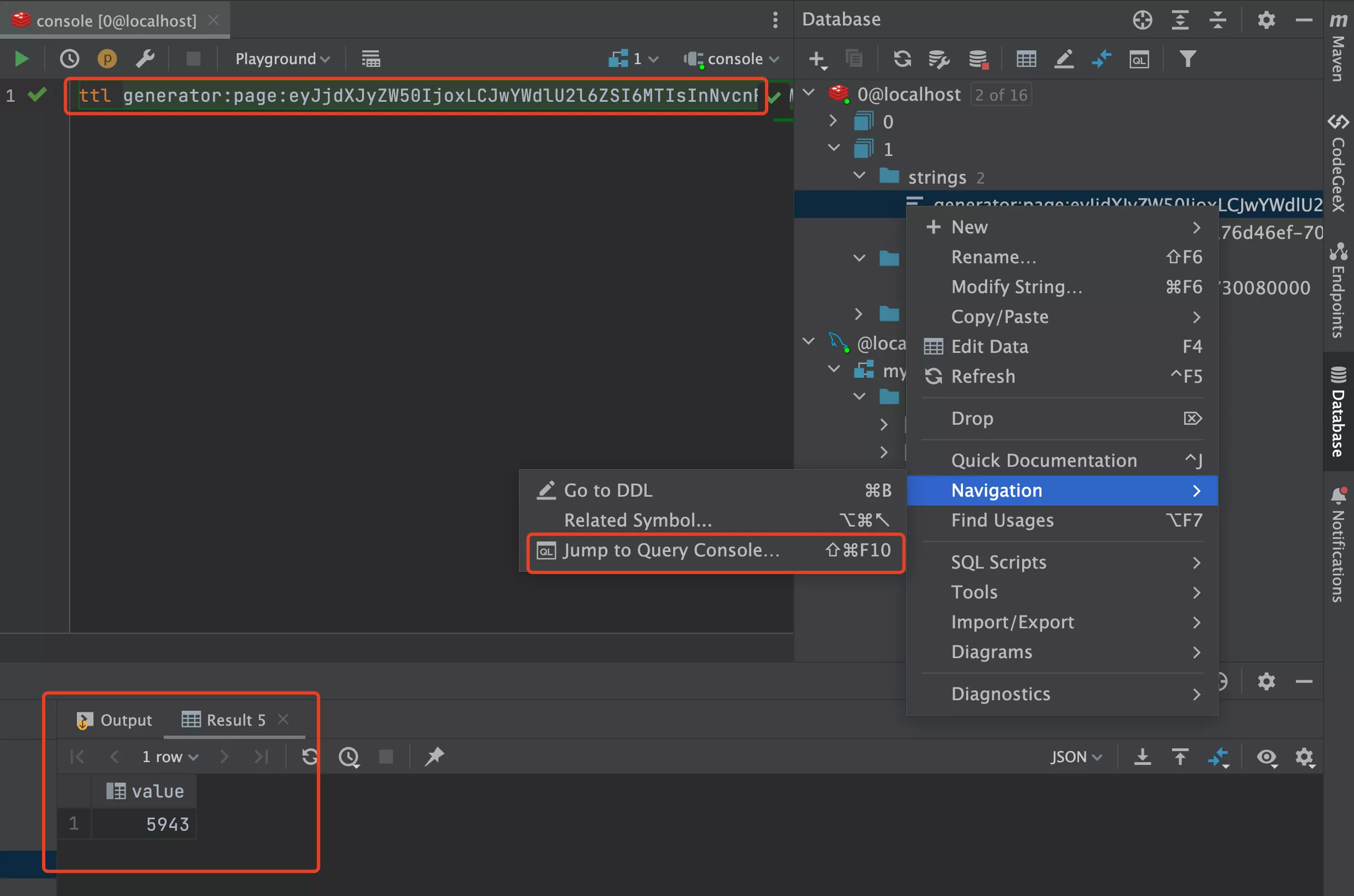
- 测试访问接口后,在 Redis 中查看到缓存的信息
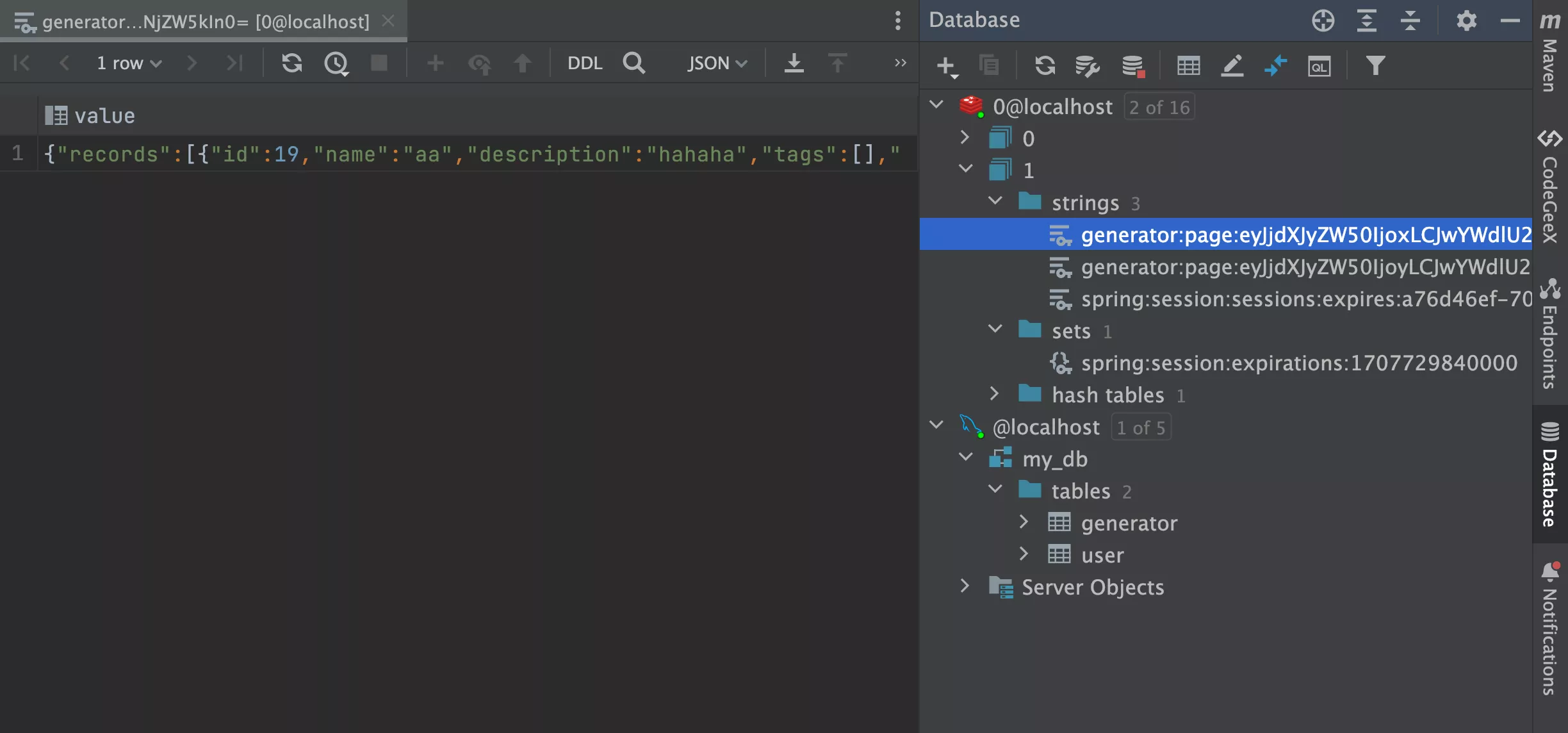
在 Redis 控制台中使用 ttl 命令查看过期时间,单位为秒:
3. 测试
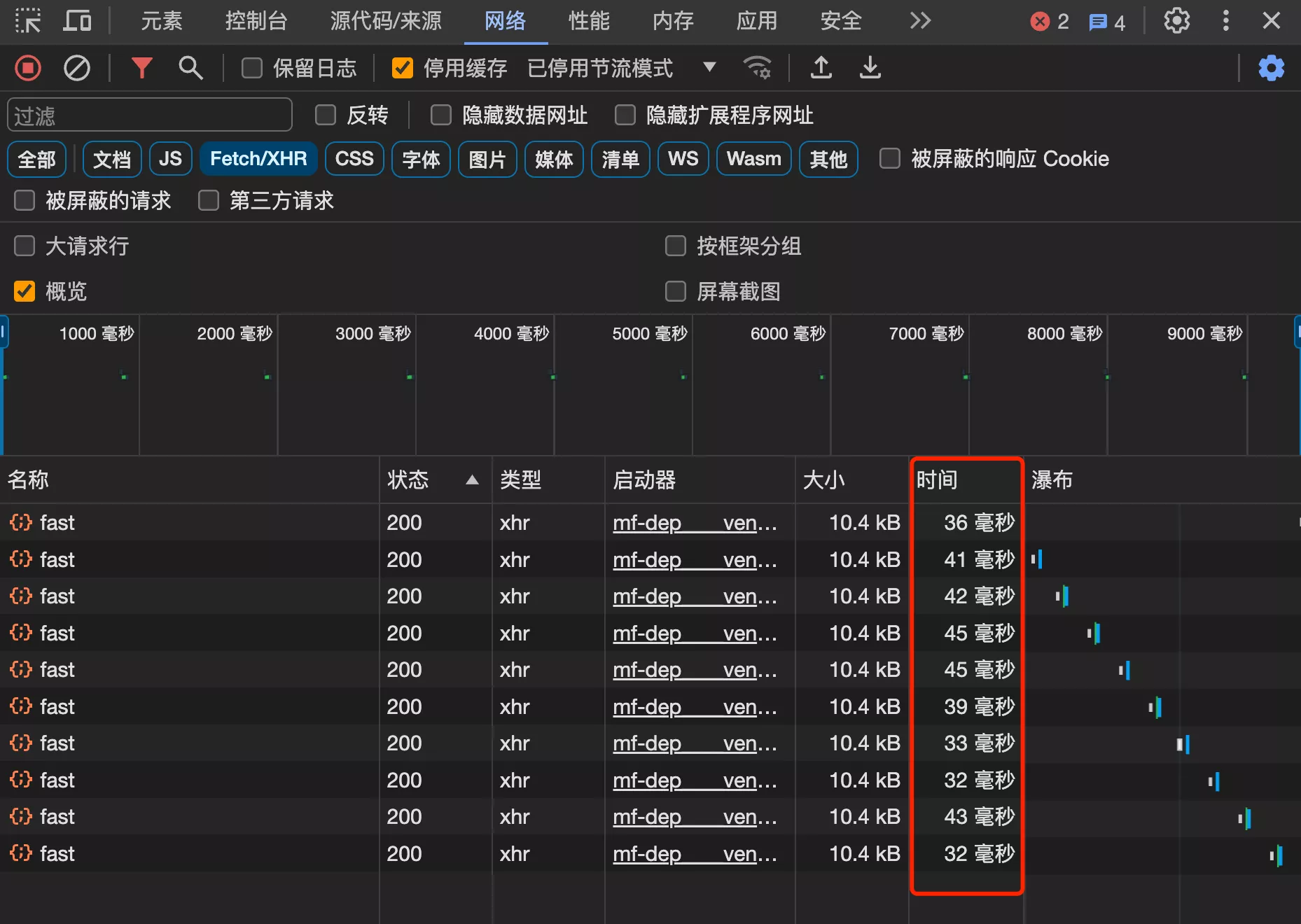
测试发现,使用缓存后,响应时间大幅减少,平均耗时 40 毫秒,缩短了 80%!
qps 达到 200.8/sec,已经是之前的 3 倍 了!
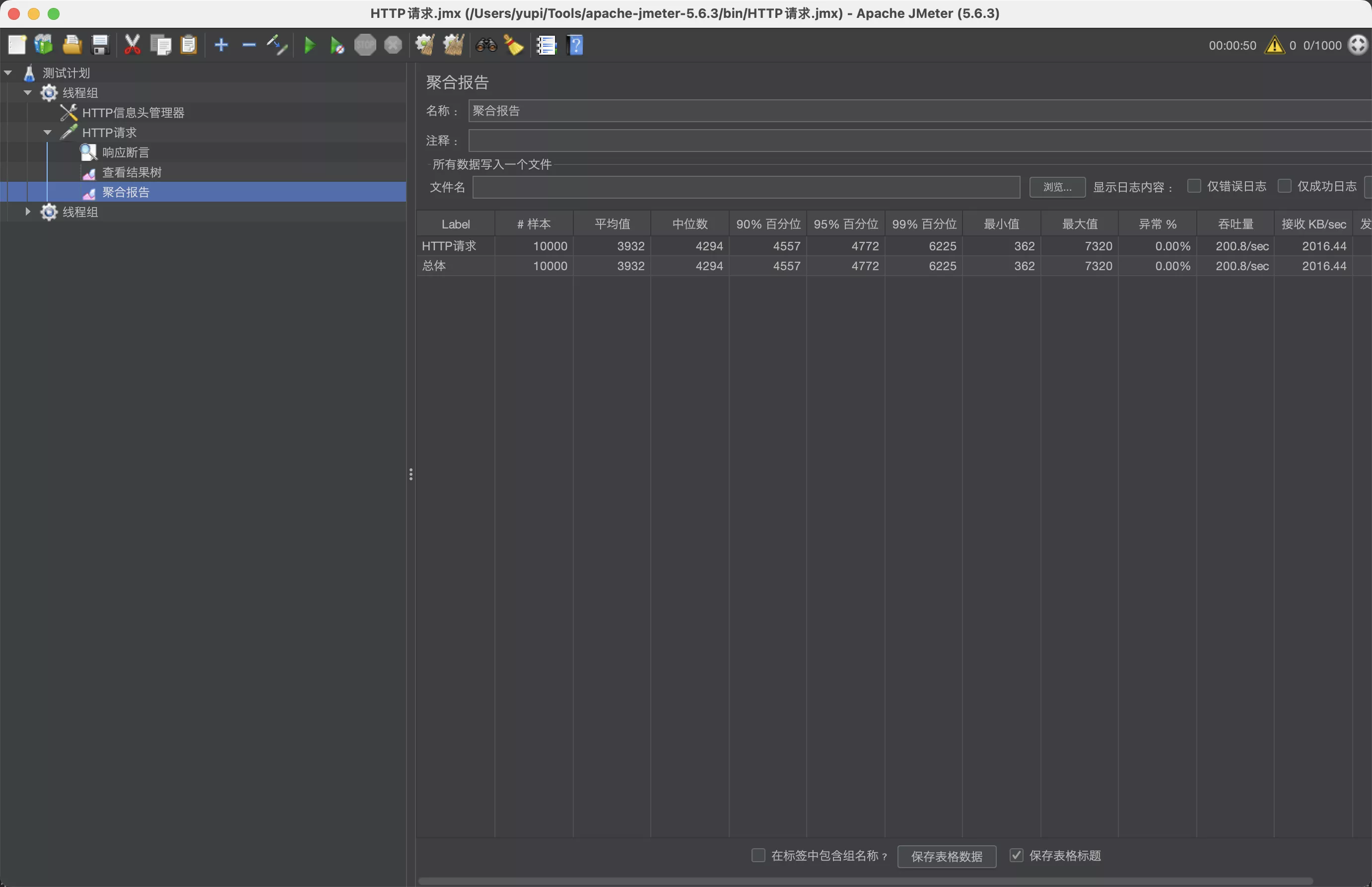
但是因为系统处理能力还是跟不上请求速度,很多线程需要排队等待 4 秒,最大值要等 7 多秒。所以还需要再进一步优化
5. 多级缓存
如果 Redis 缓存还不够快,还可以使用本地缓存,直接从内存中读取缓存、不需要任何网络请求,一般能得到进一步的性能提升
1. Caffeine 本地缓存
在 Java 中使用本地缓存,推荐使用 Caffeine 库,这是一个主流的、高性能的本地缓存库。相比于自己构造 HashMap,Caffeine 还支持多种数据淘汰、数据通知、异步刷新等能力,更易用
注意,根据官方文档,Caffeine 3 版本需要 Java 11 或以上,Java 8 请用 Caffeine 2 版本!
Cache<Key, Graph> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
// 查找一个缓存元素, 没有查找到的时候返回null
Graph graph = cache.getIfPresent(key);
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回null
graph = cache.get(key, k -> createExpensiveGraph(key));
// 添加或者更新一个缓存元素
cache.put(key, graph);
// 移除一个缓存元素
cache.invalidate(key);
2. 多级缓存设计
对于分布式系统,一般不会单独使用本地缓存,而是将本地缓存和分布式缓存进行组合,形成多级缓存
- Caffeine 一级缓存:将数据存储在应用程序的内存中,性能更高。但是仅在本地生效,而且应用程序关闭后,数据会丢失
- Redis 二级缓存:将数据存储在 Redis 中,所有的程序都从 Redis 内读取数据,可以实现数据的持久化和缓存的共享
二者结合,请求数据时,首先查找本地一级缓存;如果在本地缓存中没有查询到数据,再查找远程二级缓存,并且写入到本地缓存;如果还没有数据,才从数据库中读取,并且写入到所有缓存
- 使用多级缓存,可以充分利用本地缓存的快速读取特性,以及远程缓存的共享和持久化特性
3. 多级缓存开发
首先在 manager 包下新建一个通用的多级缓存类 CacheManager,并分别编写读取缓存、写入缓存、清理缓存的方法
package com.yupi.web.manager;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
* 多级缓存
*/
@Component
public class CacheManager {
@Resource
private StringRedisTemplate stringRedisTemplate;
// 本地缓存
Cache<String, String> localCache = Caffeine.newBuilder()
.expireAfterWrite(100, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
/**
* 写缓存
*
* @param key
* @param value
*/
public void put(String key, String value) {
localCache.put(key, value);
stringRedisTemplate.opsForValue().set(key, value, 100, TimeUnit.MINUTES);
}
/**
* 读缓存
*
* @param key
* @return
*/
public String get(String key) {
// 先从本地缓存中尝试获取
String value = localCache.getIfPresent(key);
if (value != null) {
return value;
}
// 本地缓存未命中,尝试从 Redis 中获取
value = stringRedisTemplate.opsForValue().get(key);
if (value != null) {
// 将从 Redis 获取的值放入本地缓存
localCache.put(key, value);
}
return value;
}
/**
* 移除缓存
*
* @param key
*/
public void delete(String key) {
localCache.invalidate(key);
stringRedisTemplate.delete(key);
}
}
然后就可以在查询接口中使用多级缓存
/**
* 快速分页获取列表(封装类)
*
* @param generatorQueryRequest
* @param request
* @return
*/
@PostMapping("/list/page/vo/fast")
public BaseResponse<Page<GeneratorVO>> listGeneratorVOByPageFast(@RequestBody GeneratorQueryRequest generatorQueryRequest,
HttpServletRequest request) {
long current = generatorQueryRequest.getCurrent();
long size = generatorQueryRequest.getPageSize();
String cacheKey = getPageCacheKey(generatorQueryRequest);
// 多级缓存
String cacheValue = cacheManager.get(cacheKey);
if (cacheValue != null) {
Page<GeneratorVO> generatorVOPage = JSONUtil.toBean(cacheValue,
new TypeReference<Page<GeneratorVO>>() {
},
false);
return ResultUtils.success(generatorVOPage);
}
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
QueryWrapper<Generator> queryWrapper = generatorService.getQueryWrapper(generatorQueryRequest);
queryWrapper.select("id", "name", "description", "tags", "picture", "status", "userId", "createTime", "updateTime");
Page<Generator> generatorPage = generatorService.page(new Page<>(current, size), queryWrapper);
Page<GeneratorVO> generatorVOPage = generatorService.getGeneratorVOPage(generatorPage, request);
// 写入多级缓存
cacheManager.put(cacheKey, JSONUtil.toJsonStr(generatorVOPage));
return ResultUtils.success(generatorVOPage);
}
4. 测试
使用本地缓存后,响应时间进一步减少,平均 30 毫秒,缩短了 25%
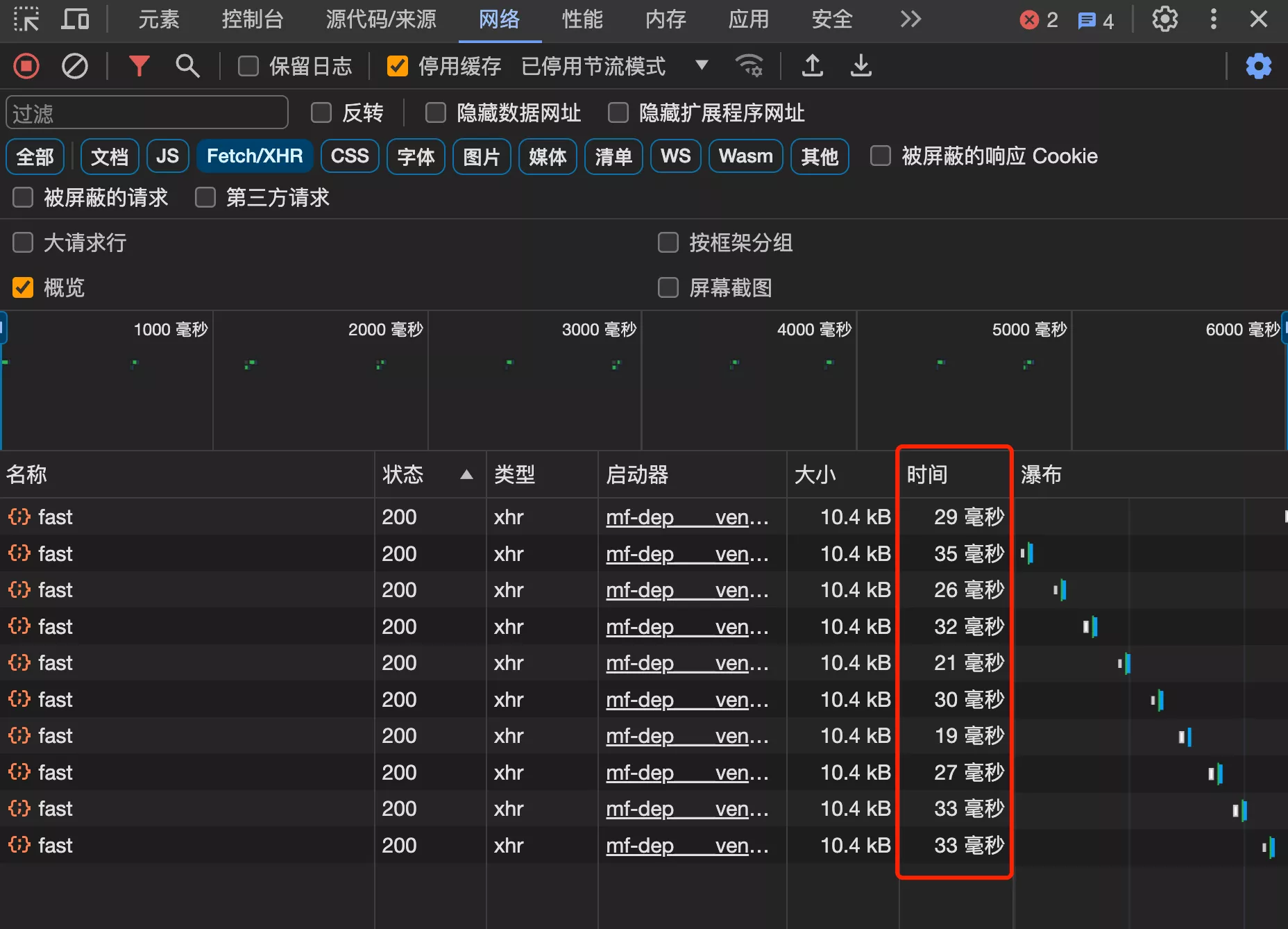
压力测试,qps 达到 208.8 / 秒
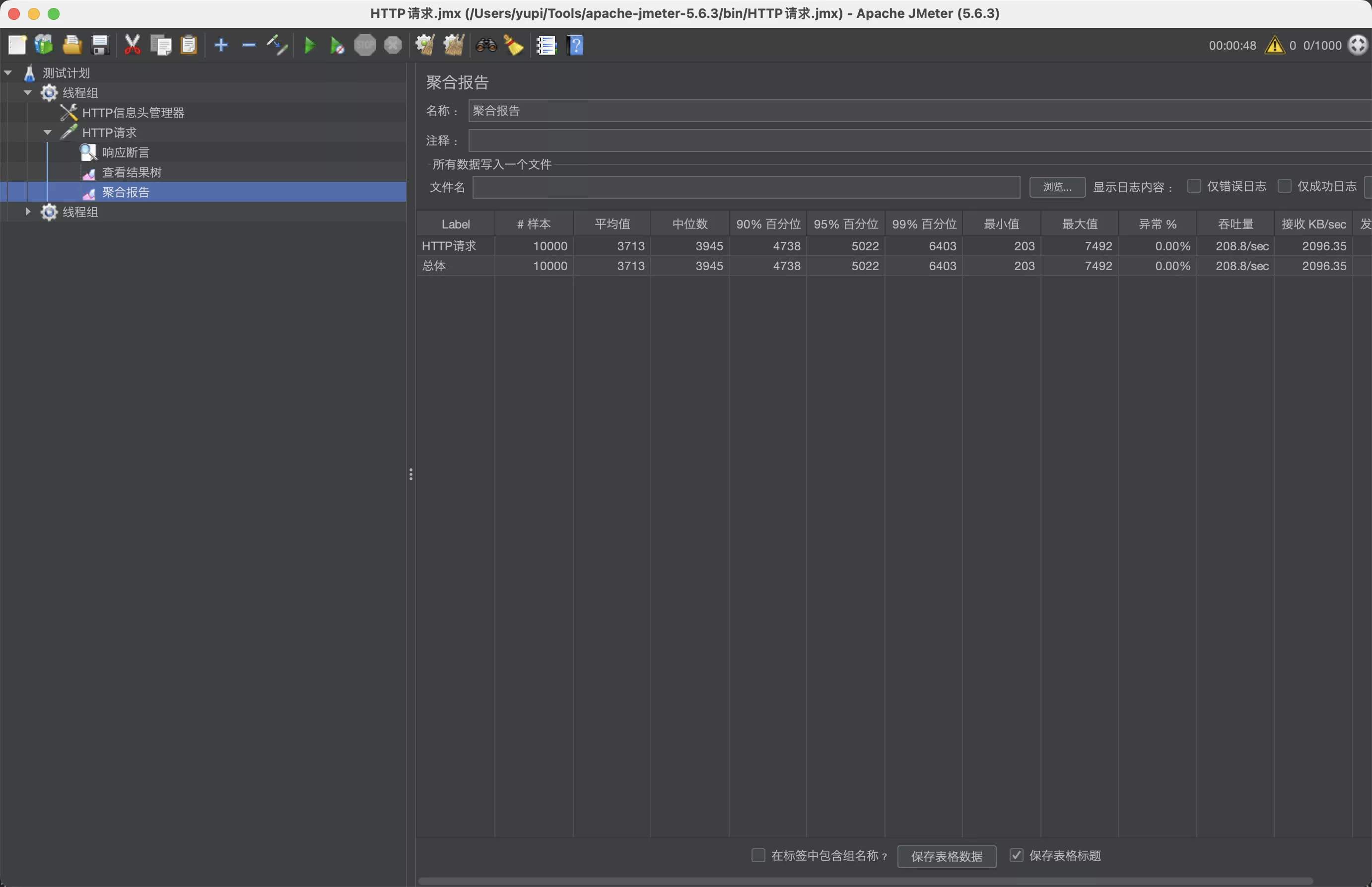
6. 计算优化
1. 分析
任何计算都会消耗系统的 CPU 资源,在 CPU 资源有限的情况下,减少不必要的计算
- 可能消耗计算资源的操作应该就是 JSON 序列化(反序列化)。直接用 JDK 默认的序列化工具读写缓存
在 JSON 序列化中,需要遍历数据结构并将其转换为 JSON 格式的字符串。这个过程中可能涉及到字符串拼接、字符编码转换等计算密集型操作
2. 开发
- 首先修改 maker 项目中,Meta 对象的所有子类,给它们都添加序列化支持
@NoArgsConstructor
@Data
public static class FileConfig implements Serializable {
private String inputRootPath;
private String outputRootPath;
private String sourceRootPath;
private String type;
private List<FileInfo> files;
@NoArgsConstructor
@Data
public static class FileInfo implements Serializable {
private String inputPath;
private String outputPath;
private String type;
private String generateType;
private String condition;
private String groupKey;
private String groupName;
private List<FileInfo> files;
}
}
- 修改
CacheManager,将缓存类型从 String 改为 Object
package com.yupi.web.manager;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
* 多级缓存
*/
@Component
public class CacheManager {
@Resource
private RedisTemplate<String, Object> redisTemplate;
// 本地缓存
Cache<String, Object> localCache = Caffeine.newBuilder()
.expireAfterWrite(100, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
/**
* 写缓存
*
* @param key
* @param value
*/
public void put(String key, Object value) {
localCache.put(key, value);
redisTemplate.opsForValue().set(key, value, 100, TimeUnit.MINUTES);
}
/**
* 读缓存
*
* @param key
* @return
*/
public Object get(String key) {
// 先从本地缓存中尝试获取
Object value = localCache.getIfPresent(key);
if (value != null) {
return value;
}
// 本地缓存未命中,尝试从 Redis 中获取
value = redisTemplate.opsForValue().get(key);
if (value != null) {
// 将从 Redis 获取的值放入本地缓存
localCache.put(key, value);
}
return value;
}
/**
* 移除缓存
*
* @param key
*/
public void delete(String key) {
localCache.invalidate(key);
redisTemplate.delete(key);
}
}
- 修改查询接口,移除序列化相关的代码
@PostMapping("/list/page/vo/fast")
public BaseResponse<Page<GeneratorVO>> listGeneratorVOByPageFast(@RequestBody GeneratorQueryRequest generatorQueryRequest,
HttpServletRequest request) {
long current = generatorQueryRequest.getCurrent();
long size = generatorQueryRequest.getPageSize();
String cacheKey = getPageCacheKey(generatorQueryRequest);
// 本地缓存
Object cacheValue = cacheManager.get(cacheKey);
if (cacheValue != null) {
return ResultUtils.success((Page<GeneratorVO>) cacheValue);
}
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
QueryWrapper<Generator> queryWrapper = generatorService.getQueryWrapper(generatorQueryRequest);
queryWrapper.select("id", "name", "description", "tags", "picture", "status", "userId", "createTime", "updateTime");
Page<Generator> generatorPage = generatorService.page(new Page<>(current, size), queryWrapper);
Page<GeneratorVO> generatorVOPage = generatorService.getGeneratorVOPage(generatorPage, request);
// 写入本地缓存
cacheManager.put(cacheKey, generatorVOPage);
return ResultUtils.success(generatorVOPage);
}
3. 测试
移除序列化后,qps 达到了 1000 多, 提升了 5 倍左右!
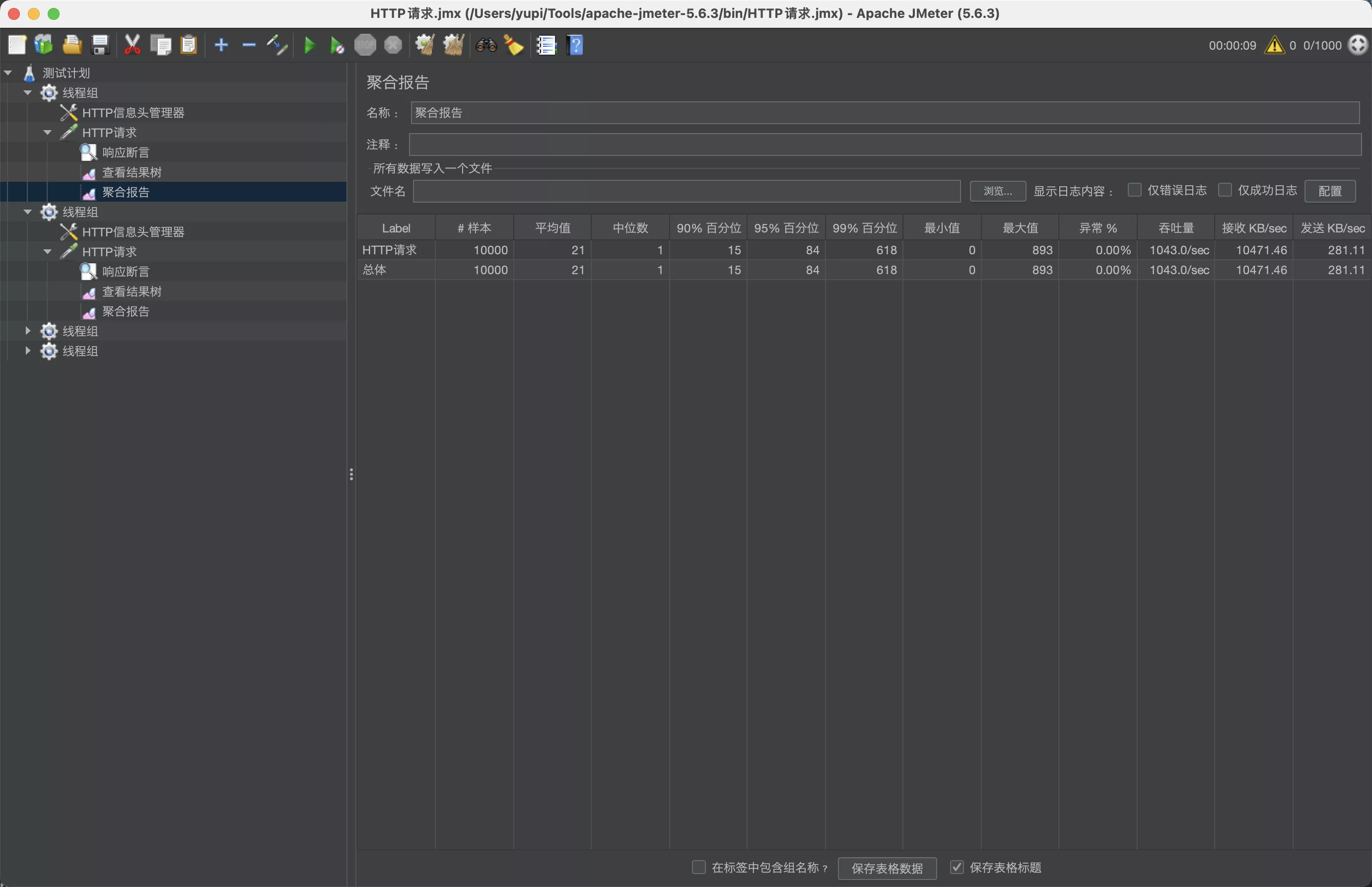
1000 qps 已经超过了之前设置的压测线程生成速率,结果可能不准。所以更改线程组配置,将循环次数扩大为 100,相当于每秒创建 1 万个线程测试
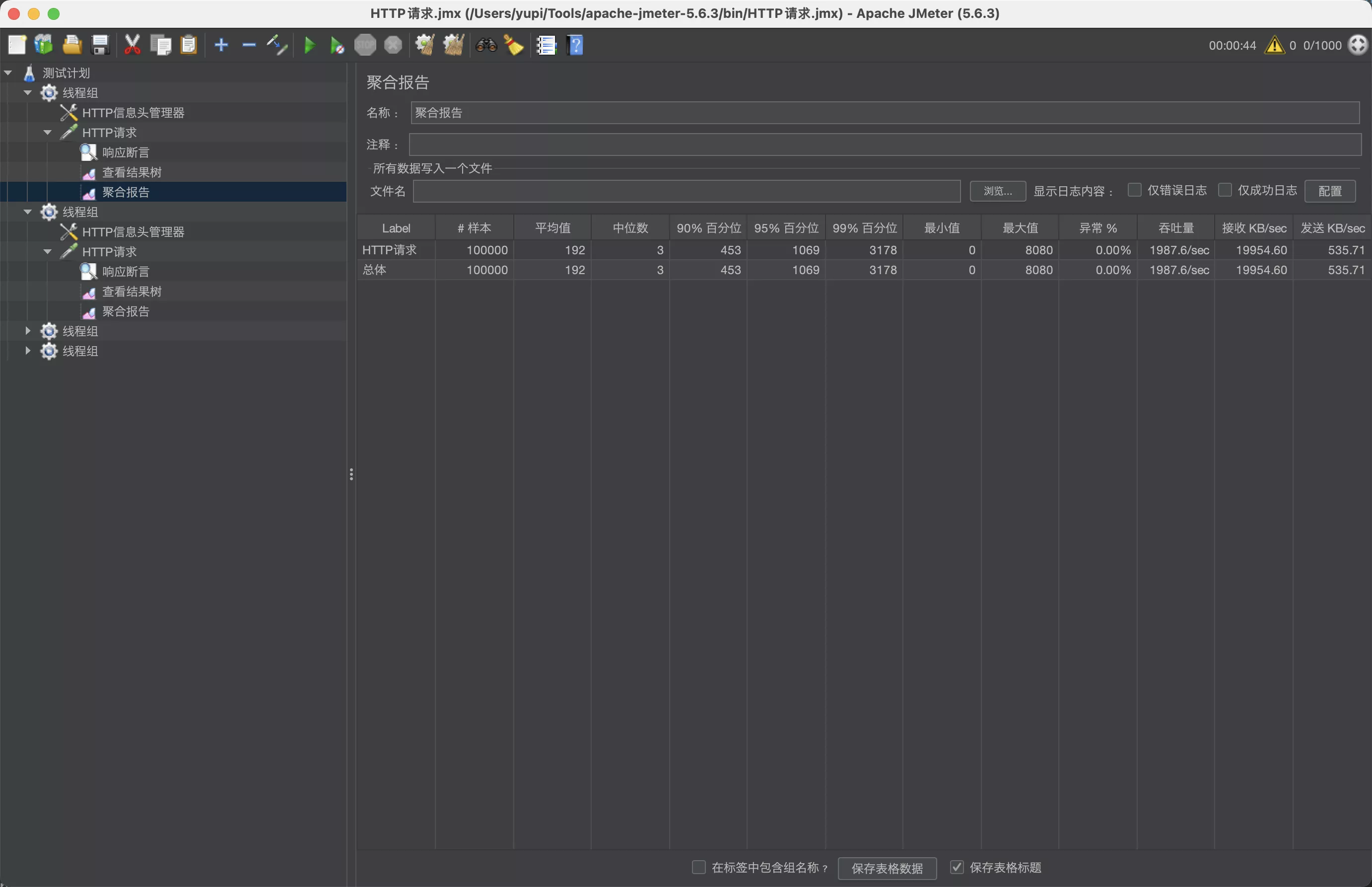
再次压测,qps 达到了 2000,是最开始做任何优化前的 30 倍!
7. 请求层性能优化
1. 参数优化
当并发请求数量超出系统处理能力时,会出现请求排队,而且请求排队最大时间长达 8 秒
- Spring Boot 最大连接数和最大并发数是多少?问倒一大片!
- Spring Boot 项目默认使用嵌入式的 Tomcat 服务器接受处理请求,可以调整 tomcat 的参数,比如最大线程数 maxThreads、最大连接数 maxConnections、请求队列长度 accept-count 等,来增加同时接受处理请求的能力
server:
tomcat:
max-connections: 10_000
threads:
max: 1024
accept-count: 1_000
压力测试,qps 达到了 3700,性能又提升了接近 1 倍,是最初的 60 倍!
注意:更高的最大线程数设置未必能提升 qps。因为在 CPU 资源有限的情况下,线程数过多可能导致资源的竞争和上下文的频繁切换。所以最大线程数设置为多少,取决于实际的性能测试
2. 测试空接口性能
可以编写一个干净的、没有任何业务逻辑的接口,然后测试 Tomcat 服务器处理请求的最大性能
- 编写一个干净的接口
/**
* 健康检查
*/
@RestController
@RequestMapping("/health")
@Slf4j
public class HealthController {
@GetMapping
public String healthCheck() {
return "ok";
}
}
- 注释掉请求拦截器,防止额外的处理逻辑干扰测试结果:
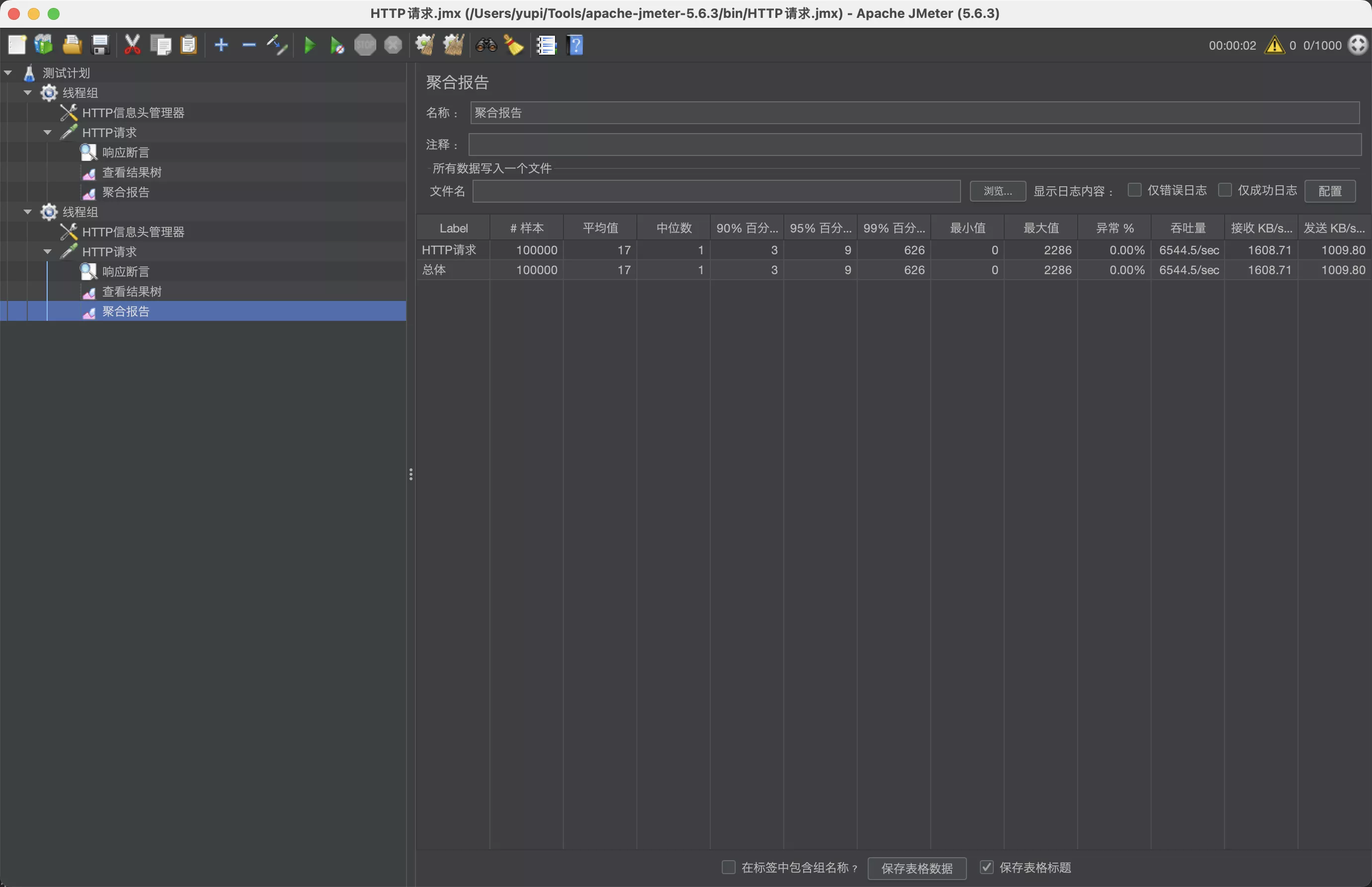
- 新增一个线程组来压力测试,线程组配置(1000 个线程、100 组、10 秒启动)。空接口的 qps 最高能到 6500 左右
- 该环境下,一个接近极限的数字,无论再怎么优化业务逻辑,qps 也不会超过这个值
3. Vert.x 反应式编程
接受请求的服务器性能有限,就尝试更换一个性能更高的服务器(或请求处理框架),比如基于反应式编程的 Vert.x。
- 它是基于 Java 的
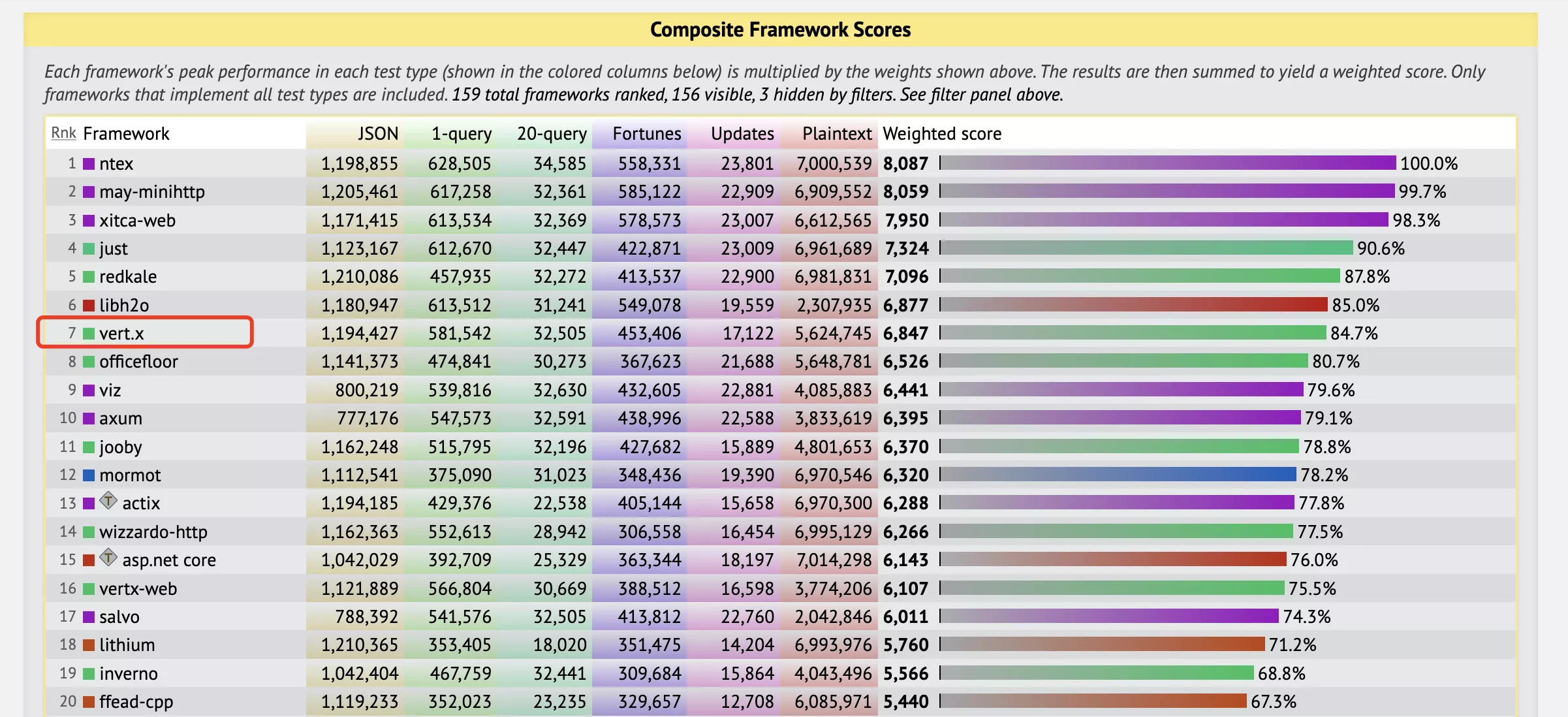
- 在 techempower 最新的压力测试排行榜上,Vert.x 框架排名高达第 7 名!Spring 排名是第 88 名
1. Vert.x入门
Vert.x 的优点在于:官方文档
- 充分利用资源节约成本
- 更方便的并发和异步编程
- 使用更灵活,易于整合、启动和部署
首先阅读 官方入门教程,学习成本比较高的,官方文档一般,入门教程页面都存在问题
- 引入依赖:
<!-- https://mvnrepository.com/artifact/io.vertx/vertx-core -->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>4.5.1</version>
</dependency>
- 写一个 Web 服务器,提供 Http 接口
- 在 Vert.x 中,可以通过定义 Verticle 来实现 Web 服务。Verticle 是 Vert.x 中的一个组件,用于处理事件、执行业务逻辑,并能够在 Vert.x 实例中进行水平扩展,Verticle 之间可以相互通讯
为了便于理解,可以把它当成一个嵌入式的 Tomcat
package com.yupi.web;
import io.vertx.core.AbstractVerticle;
import io.vertx.core.Verticle;
import io.vertx.core.Vertx;
public class MainVerticle extends AbstractVerticle {
@Override
public void start() throws Exception {
// Create the HTTP server
vertx.createHttpServer()
// Handle every request using the router
.requestHandler(req -> {
req.response()
.putHeader("content-type", "text/plain")
.end("ok");
})
// Start listening
.listen(8888)
// Print the port
.onSuccess(server ->
System.out.println(
"HTTP server started on port " + server.actualPort()
)
);
}
public static void main(String[] args) throws Exception {
Vertx vertx = Vertx.vertx();
Verticle myVerticle = new MainVerticle();
vertx.deployVerticle(myVerticle);
}
}
也可以尝试使用 Vert.x_web 组件开发接口,类似 Node.js 后端框架的语法
import io.vertx.core.AbstractVerticle;
import io.vertx.core.Future;
import io.vertx.core.http.HttpServer;
import io.vertx.core.http.HttpServerRequest;
import io.vertx.ext.web.Router;
public class MyVerticle extends AbstractVerticle {
@Override
public void start(Future<Void> startFuture) {
// Create an HTTP server
HttpServer server = vertx.createHttpServer();
// Create a router to handle requests
Router router = Router.router(vertx);
// Define a route that handles GET requests to "/hello"
router.get("/hello").handler(this::handleHello);
// Set the router as the request handler for the server
server.requestHandler(router);
// Listen on port 8080
server.listen(8080, ar -> {
if (ar.succeeded()) {
System.out.println("Server started on port 8080");
startFuture.complete();
} else {
System.out.println("Failed to start server");
startFuture.fail(ar.cause());
}
});
}
// Handler method for the "/hello" route
private void handleHello(HttpServerRequest request) {
// Respond with a "Hello, Vert.x!" message
request.response()
.putHeader("content-type", "text/plain")
.end("Hello, Vert.x!");
}
}
- 同样的线程组压力测试(1000 个线程、100 组、10 秒启动),发现 Vert.x 的空接口 qps 高达 1 万多!极限性能高于 Tomcat
2. Vert.x为什么快
关于 Vert.x 特性和原理的讲解
1. 异步非阻塞
经典面试题:
- 什么是同步和异步?
- 什么是阻塞和非阻塞?
- 什么是异步非阻塞?
- 同步:一个任务的完成需要等待另一个任务的结果。必须按照顺序,先完成上一个任务,才能执行下一个任务
- 异步:一个任务的完成不需要等待另一个任务的结果
- 先烧一壶水、再去学编程,按下烧水按钮后,不需要干瞪眼等水烧好,可以直接去学编程了。异步通常会涉及回调、事件通知机制,比如水烧好后会有响声,提醒我们水已经烧好,我们就可以取水了
- 阻塞:执行一个任务时,需要一直等待,期间无法执行其他任务,直到执行完成
- 非阻塞:执行一个任务时,不需要等待,可以继续执行其他任务。然后通过定时的检查来确认任务是否完成,也就是所谓的轮询
- 通过电话联系某人。阻塞方式,只要对方不接电话,我就一直拿电话等着,不能再给其他人打电话。非阻塞方式,我可以每隔 10 分钟打一次电话,这期间即使对方不在,我也能继续给别人打电话,直到最后打通
同步 / 异步、阻塞 / 非阻塞之间有什么区别呢?一种解释:
- 同步 / 异步:更关注 消息通信机制 ,即调用方以什么方式获取到结果,是直接返回、还是通过回调通知
- 阻塞 / 非阻塞:更关注线程在等待调用结果时的状态。如果是阻塞,会一直占用线程资源;而如果是非阻塞,发起调用后可以立即返回,线程可以被解放出来做其他的工作
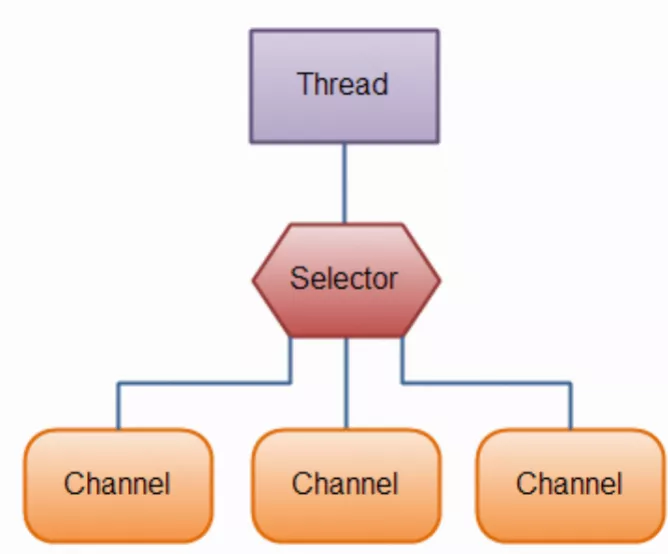
NIO(非阻塞 I/O),是 Java 提供的一组支持非阻塞 I/O 操作的 API,通过通道、缓冲区、选择器等组件,实现了一个线程同时处理多个通道请求的能力;并且实现了事件驱动机制,当通道有事件发生时,通过选择器响应,而不是轮询所有的通道
- 通过 Selector,可以复用一个线程处理多个 Channel(客户端连接)
- eg:要收整个班级的作业,不用让老师一个一个学生收、也不用每个学生分配一个老师一直等着,直接让做完作业的学生通知老师即可,这期间老师可以做其他事情
2. 事件驱动
事件驱动:是一种编程范式,指整个系统间的各个组件通过发送和接收事件进行通信和协作,从而实现异步非阻塞 IO。
- eg:前端和后端协作开发,可以先分别开发、各干各的,不用等待对方开发完成再开发。等后端写完了接口,通知前端(相当于发送了一个事件),前端接收到这个信息后,就可以对接后端了
- 实际的事件驱动实现中,一般会有事件总线(Event Bus)概念,相当于一个中间人,负责接受所有的事件,并分发给不同的事件处理者
- 消息队列即事件驱动,实现异步通信和应用解耦

3. 事件循环
是实现事件驱动的核心操作,也是实现异步、非阻塞编程的方法
- 在一个事件循环中,程序会不断地检查事件队列,如果有新事件到达,就会触发相应处理程序的回调函数来执行。允许程序在等待 I/O 操作完成的同时继续执行其他任务,而不会阻塞整个进程
Node.js 就使用了事件循环机制,实现了非阻塞 IO 和事件驱动
4. 反应式编程
是一种编程范式,常用于异步的数据流和事件处理,通过声明的方式来定义处理规则
- 核心作用:实现了异步处理(类似 CompletableFuture),只不过通过一系列 API 的支持,便于我们更轻松地处理异步数据
import reactor.core.publisher.Mono;
public class UserService {
public Mono<User> getUserById(long userId) {
// 使用反应式编程的 Mono 封装异步查询
return userRepository.findById(userId);
}
}
反应式编程。getUserById() 返回的是 Reactor 的 Mono 类型,表示异步计算的结果,可以再对这个 Mono 类型定义各种复杂的处理操作。其中调用的 userRepository.findById() 是一个异步的数据库查询操作,不会阻塞当前线程
4. Vert.x改造请求
- 在
vertx包下创建一个新的 Verticle,名称为MainVericle.java- 需要自主获取请求信息,判断请求的路径和方法、获取请求数据,并执行对应的逻辑
- 将之前查询接口的逻辑搬到 Verticle 中。为了方便测试,仅编写读取缓存的逻辑
package com.yupi.web.vertx;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.yupi.web.common.ResultUtils;
import com.yupi.web.controller.GeneratorController;
import com.yupi.web.manager.CacheManager;
import com.yupi.web.model.dto.generator.GeneratorQueryRequest;
import com.yupi.web.model.vo.GeneratorVO;
import io.vertx.core.AbstractVerticle;
import io.vertx.core.http.HttpMethod;
import io.vertx.core.http.HttpServerResponse;
public class MainVerticle extends AbstractVerticle {
private CacheManager cacheManager;
public MainVerticle(CacheManager cacheManager) {
this.cacheManager = cacheManager;
}
@Override
public void start() {
// Create the HTTP server
vertx.createHttpServer()
// Handle every request using the router
.requestHandler(req -> {
HttpMethod httpMethod = req.method();
String path = req.path();
// 分页获取生成器
if (HttpMethod.POST.equals(httpMethod) && "/generator/page".equals(path)) {
// 设置请求体处理器
req.handler(buffer -> {
// 获取请求体中的 JSON 数据
String requestBody = buffer.toString();
GeneratorQueryRequest generatorQueryRequest = JSONUtil.toBean(requestBody, GeneratorQueryRequest.class);
// 处理 JSON 数据
// 在实际应用中,这里可以解析 JSON、执行业务逻辑等
String cacheKey = GeneratorController.getPageCacheKey(generatorQueryRequest);
// 设置响应头
HttpServerResponse response = req.response();
response.putHeader("content-type", "application/json");
// 本地缓存
Object cacheValue = cacheManager.get(cacheKey);
if (cacheValue != null) {
// 返回 JSON 响应
response.end(JSONUtil.toJsonStr(ResultUtils.success((Page<GeneratorVO>) cacheValue)));
return;
}
response.end("");
});
}
})
// Start listening
.listen(8888)
// Print the port
.onSuccess(server ->
System.out.println(
"HTTP server started on port " + server.actualPort()
)
);
}
}
- 创建 VertxManager Bean,用于创建 Vertx 容器、并给它注入 cacheManager 依赖
package com.yupi.web.vertx;
import com.yupi.web.manager.CacheManager;
import io.vertx.core.Verticle;
import io.vertx.core.Vertx;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
@Component
public class VertxManager {
@Resource
private CacheManager cacheManager;
@PostConstruct
public void init() {
Vertx vertx = Vertx.vertx();
Verticle myVerticle = new MainVerticle(cacheManager);
vertx.deployVerticle(myVerticle);
}
}
5. 测试
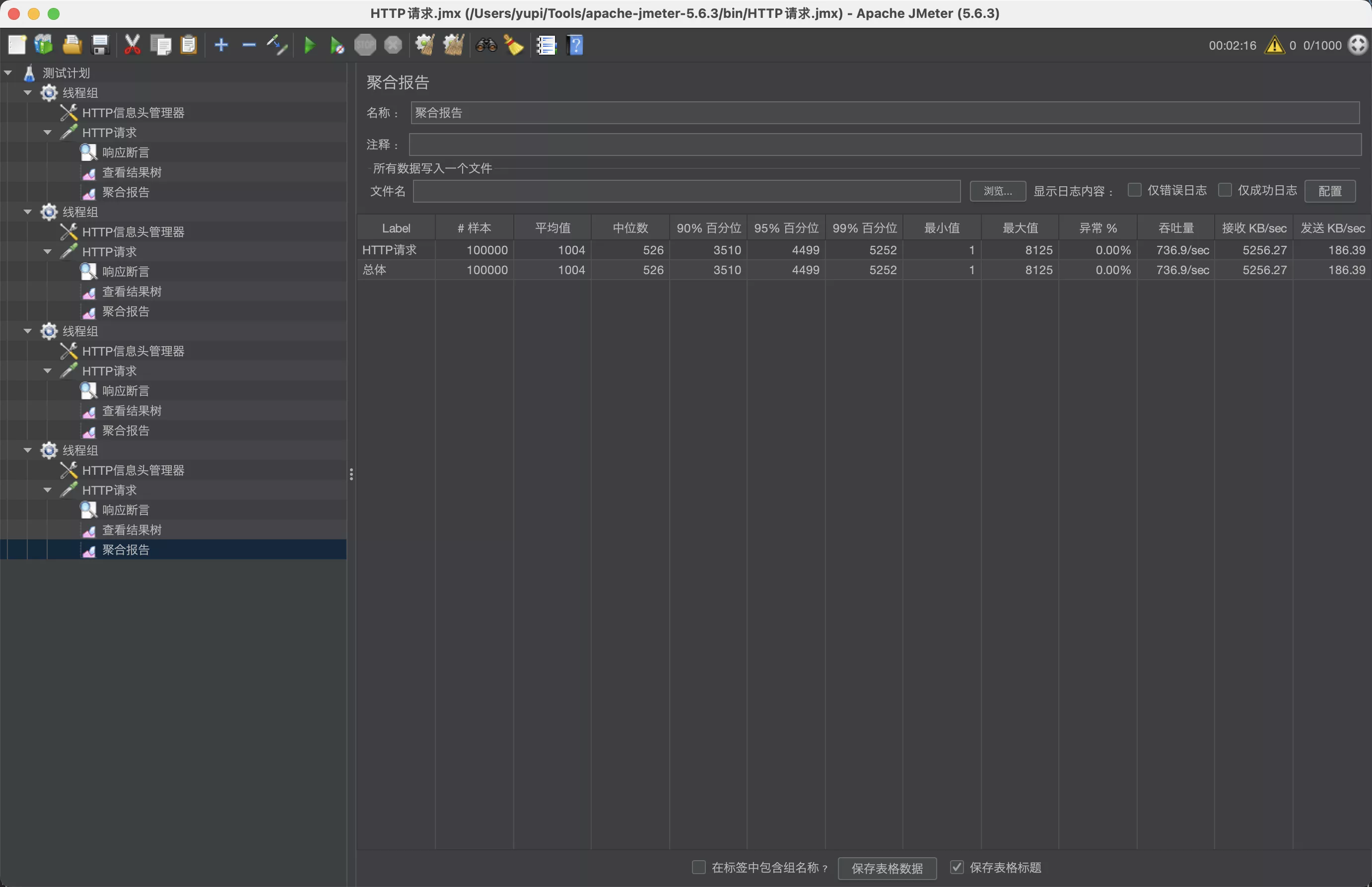
创建新的压力测试,复用之前的线程组设置,请求地址修改为 Vert.x 的接口地址 /generator/page,传入同样的参数
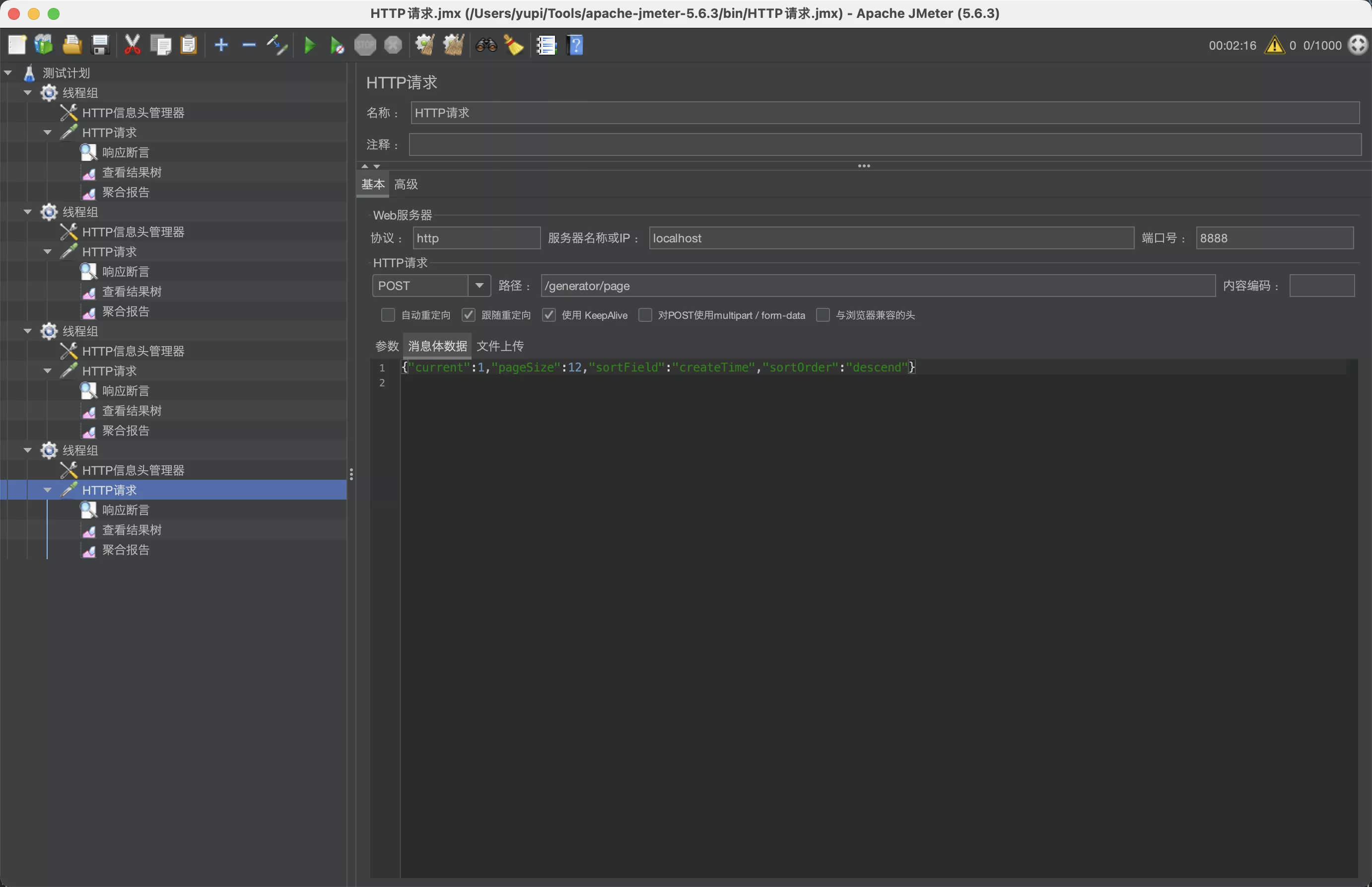
qps 反而更低了?!
Vert.x 是一个基于事件驱动、非阻塞、异步的框架,它的设计目标是处理大量并发连接。与之相反,Spring Boot 内置的 Tomcat 是同步阻塞模型。在某些场景下(比如传统 CRUD 应用、或 IO 操作较少),同步阻塞模型可能会更适用,因为都需要等待数据处理完成后再返回响应,反而减少了线程调度的成本。Vert.x 更适合于实时应用,例如聊天应用、实时通信等,或者 IO 密集型的任务